mirror of
https://github.com/qodo-ai/pr-agent.git
synced 2025-12-12 02:45:18 +00:00
Compare commits
425 commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
bf5da9a9fb | ||
|
|
ede3f82143 | ||
|
|
5ec92b3535 | ||
|
|
4a67e23eab | ||
|
|
3ce4780e38 | ||
|
|
edd9ef9d4f | ||
|
|
e661147a1d | ||
|
|
d8dcc3ca34 | ||
|
|
f7a4f3fc8b | ||
|
|
0bbad14c70 | ||
|
|
4c5d3d6a6e | ||
|
|
a98eced418 | ||
|
|
6d22618756 | ||
|
|
8dbc53271e | ||
|
|
79e0ff03fa | ||
|
|
d36ad319f7 | ||
|
|
2f4b71da83 | ||
|
|
7b365b8d1c | ||
|
|
7de5ac74ca | ||
|
|
bfc82390dd | ||
|
|
a2b5ae87d7 | ||
|
|
d141e4ff9d | ||
|
|
8bd134e30c | ||
|
|
a84ba36cf4 | ||
|
|
3d54b501b2 | ||
|
|
a2fd3cc190 | ||
|
|
f2bbf708f2 | ||
|
|
5f8ac3d8cf | ||
|
|
9ee7ba3919 | ||
|
|
c728a486b4 | ||
|
|
8d3f3bca45 | ||
|
|
8a0759f835 | ||
|
|
f88b7ffb4d | ||
|
|
51084b4617 | ||
|
|
40ff5db659 | ||
|
|
b7874e6e5f | ||
|
|
1d7c82d68c | ||
|
|
fc7d614552 | ||
|
|
ec784874f9 | ||
|
|
eebdeea9f9 | ||
|
|
cb1c82073b | ||
|
|
335dadd0ac | ||
|
|
33744d9544 | ||
|
|
bf1cc50ece | ||
|
|
d67d053ae5 | ||
|
|
e43bf05c6e | ||
|
|
f2ba770558 | ||
|
|
3dd373a77e | ||
|
|
b9c6a2c747 | ||
|
|
a6e11f60ce | ||
|
|
604c17348d | ||
|
|
8c7712bf30 | ||
|
|
7969e4ba30 | ||
|
|
dcab8a893c | ||
|
|
2230da73fd | ||
|
|
f251a8a6cb | ||
|
|
76ed9156d3 | ||
|
|
9fd28e5680 | ||
|
|
d0bbc56480 | ||
|
|
c3bc789cd3 | ||
|
|
9252cb88d8 | ||
|
|
1527ea07cf | ||
|
|
5592e9d49d | ||
|
|
40633d7a9e | ||
|
|
d862d82475 | ||
|
|
5623fd14da | ||
|
|
26c7574b3b | ||
|
|
01a7c04263 | ||
|
|
a194ca65d2 | ||
|
|
584e87ae48 | ||
|
|
632c39962c | ||
|
|
be93651db8 | ||
|
|
fea8bc5150 | ||
|
|
58fe872a44 | ||
|
|
2866384931 | ||
|
|
3d66a9e8c3 | ||
|
|
65dea899ec | ||
|
|
7db9529d96 | ||
|
|
b5260a824f | ||
|
|
ccfc24ea85 | ||
|
|
063d0999c5 | ||
|
|
91dade811f | ||
|
|
3388ca34df | ||
|
|
10f960f43d | ||
|
|
7573dbbc1b | ||
|
|
ae9bb72f8e | ||
|
|
76d05e2279 | ||
|
|
544c962dd7 | ||
|
|
557a52b7f3 | ||
|
|
ed2c615d65 | ||
|
|
d35f051a58 | ||
|
|
7fc0a2330d | ||
|
|
5b5e4dd59f | ||
|
|
40ea7fcb6c | ||
|
|
96299b28bc | ||
|
|
0ee6ee6e7d | ||
|
|
60948ac3c8 | ||
|
|
0588459ca3 | ||
|
|
42f7c72857 | ||
|
|
393749dcb7 | ||
|
|
7981a2de2e | ||
|
|
6274852a88 | ||
|
|
fc1b757e92 | ||
|
|
3fd8210279 | ||
|
|
6c0087e0d9 | ||
|
|
7d7292b2d0 | ||
|
|
ae4c8f85f9 | ||
|
|
6dabc7b1ae | ||
|
|
9ad8e921b5 | ||
|
|
12eea7acf3 | ||
|
|
1fff1b0208 | ||
|
|
0989247d42 | ||
|
|
411f933a34 | ||
|
|
2a5a84367c | ||
|
|
5de82e379a | ||
|
|
532fbbe0a6 | ||
|
|
0f8606b899 | ||
|
|
c84a602d3a | ||
|
|
025b9bf44c | ||
|
|
785dde5e54 | ||
|
|
08a683c9a4 | ||
|
|
a53a9358ed | ||
|
|
03832818e6 | ||
|
|
ead49dc605 | ||
|
|
ae4fc71603 | ||
|
|
8258c2e774 | ||
|
|
dae9683770 | ||
|
|
5fc466bfbc | ||
|
|
d2c304eede | ||
|
|
a3217042f4 | ||
|
|
07cc7f9f42 | ||
|
|
604e5743f3 | ||
|
|
7597d27095 | ||
|
|
fb452b992d | ||
|
|
0b801d391c | ||
|
|
8f9ad2b38e | ||
|
|
10a7a0fbef | ||
|
|
e4d3f8fe7f | ||
|
|
08da41c929 | ||
|
|
0a3d655912 | ||
|
|
81525cd25a | ||
|
|
aafa835137 | ||
|
|
57ec112b4d | ||
|
|
f645ebb938 | ||
|
|
ae799d1327 | ||
|
|
9c3972d619 | ||
|
|
e0a4be1397 | ||
|
|
d01a7daaa7 | ||
|
|
5c3da5d83e | ||
|
|
9e2f1ed603 | ||
|
|
6d38a90ba1 | ||
|
|
6499b8e592 | ||
|
|
9bbed66028 | ||
|
|
74a7163eea | ||
|
|
e2cfc897ab | ||
|
|
5e28f8a1d1 | ||
|
|
2de4a9996f | ||
|
|
01f16f57ca | ||
|
|
bcfd2b3d6d | ||
|
|
34b562db22 | ||
|
|
4a6a55ca7c | ||
|
|
af803ce473 | ||
|
|
9ab0a611e2 | ||
|
|
a60b91e85d | ||
|
|
4958decc89 | ||
|
|
bb115432f2 | ||
|
|
f3287a9f67 | ||
|
|
9a2ba2d881 | ||
|
|
0090f7be81 | ||
|
|
c927d20b5e | ||
|
|
8e36f46dae | ||
|
|
de5c1adaa0 | ||
|
|
1c25420fb3 | ||
|
|
62a029d36a | ||
|
|
5162d847b3 | ||
|
|
6be8860959 | ||
|
|
406ef6a934 | ||
|
|
3980c0d9d5 | ||
|
|
385f8908ad | ||
|
|
e14beacc19 | ||
|
|
fd7f8f2596 | ||
|
|
df9cb3f635 | ||
|
|
4fb22beb3a | ||
|
|
03867d5962 | ||
|
|
96435a34f8 | ||
|
|
807ce6ec65 | ||
|
|
395e5a2e04 | ||
|
|
65457b2569 | ||
|
|
82feddbb95 | ||
|
|
fb73eb75f9 | ||
|
|
39add8d78a | ||
|
|
d406555f23 | ||
|
|
0d3c2e6b51 | ||
|
|
8e33b18e2c | ||
|
|
0b00812269 | ||
|
|
06bb64a0a2 | ||
|
|
dcfc7cc54f | ||
|
|
9383cdd520 | ||
|
|
dd6f56915b | ||
|
|
54ffb2d0a1 | ||
|
|
79253e8f60 | ||
|
|
8cef104784 | ||
|
|
6aa26d8c56 | ||
|
|
10cd8848d9 | ||
|
|
fdd91c6663 | ||
|
|
5d50cfcb34 | ||
|
|
a23b527101 | ||
|
|
b81b671ab1 | ||
|
|
2d858a43be | ||
|
|
d497c33c74 | ||
|
|
642c413f08 | ||
|
|
fb3ba64576 | ||
|
|
eb10d8c6d3 | ||
|
|
aa9bfb07af | ||
|
|
0dd4f682d9 | ||
|
|
9e4923aa79 | ||
|
|
497396eaeb | ||
|
|
3a87d3ef03 | ||
|
|
d0c0aaf1c7 | ||
|
|
0b962a16e4 | ||
|
|
1e285aca1f | ||
|
|
91cc4daada | ||
|
|
fc3045df95 | ||
|
|
12a01ef5f5 | ||
|
|
aae7726bb2 | ||
|
|
70a3059cbf | ||
|
|
c12cd2d02d | ||
|
|
c3b153cdc1 | ||
|
|
460b1a54b9 | ||
|
|
a8b8202567 | ||
|
|
af2b66bb51 | ||
|
|
7b4c50c717 | ||
|
|
86847c40ff | ||
|
|
6e543da4b4 | ||
|
|
ad2a96da50 | ||
|
|
359462abfe | ||
|
|
d4ab8c46e8 | ||
|
|
5e53466d97 | ||
|
|
3efe091bc8 | ||
|
|
6f7d81b086 | ||
|
|
755165e90c | ||
|
|
179fef796d | ||
|
|
0f7f135083 | ||
|
|
4bb7da1376 | ||
|
|
e2377a46f3 | ||
|
|
4448e03117 | ||
|
|
436b5c7a0a | ||
|
|
c7511ac0d5 | ||
|
|
a397ac1e63 | ||
|
|
4384740cb6 | ||
|
|
ae6576c06b | ||
|
|
940f82b695 | ||
|
|
441b4b3795 | ||
|
|
bdee6f9f36 | ||
|
|
1663eaad4a | ||
|
|
0ee115e19c | ||
|
|
aaba9b6b3c | ||
|
|
93aaa59b2d | ||
|
|
f1c068bc44 | ||
|
|
fffbee5b34 | ||
|
|
5e555d09c7 | ||
|
|
7f95e39361 | ||
|
|
730fa66594 | ||
|
|
f42dc28a55 | ||
|
|
7251e6df96 | ||
|
|
b01a2b5f4a | ||
|
|
f170af4675 | ||
|
|
96d408c42a | ||
|
|
65e71cb2ee | ||
|
|
9773afe155 | ||
|
|
0a8a263809 | ||
|
|
597f553dd5 | ||
|
|
4b6fcfe60e | ||
|
|
7cc4206b70 | ||
|
|
8906a81a2e | ||
|
|
6179eeca58 | ||
|
|
e8c73e7baa | ||
|
|
754d47f187 | ||
|
|
bec70dc96a | ||
|
|
fd32c83c29 | ||
|
|
7efeeb1de8 | ||
|
|
d7d4b7de89 | ||
|
|
2a37225574 | ||
|
|
e87fdd0ab5 | ||
|
|
c0d7fd8c36 | ||
|
|
380437b44f | ||
|
|
5933280417 | ||
|
|
8e0c5c8784 | ||
|
|
0e9cf274ef | ||
|
|
3aae48f09c | ||
|
|
c4dd07b3b8 | ||
|
|
8c7680d85d | ||
|
|
11fb6ccc7e | ||
|
|
3aaa727e05 | ||
|
|
6108f96bff | ||
|
|
5a00897cbe | ||
|
|
e12b27879c | ||
|
|
fac2141df3 | ||
|
|
1dbfd27d8e | ||
|
|
eaeee97535 | ||
|
|
71bbc52a99 | ||
|
|
4a8e9b79e8 | ||
|
|
efdb0f5744 | ||
|
|
28750c70e0 | ||
|
|
583ed10dca | ||
|
|
07d71f2d25 | ||
|
|
447a384aee | ||
|
|
d9eb0367cf | ||
|
|
85484899c3 | ||
|
|
00b5815785 | ||
|
|
9becad2eaf | ||
|
|
74df3f8bd5 | ||
|
|
4ab97d8969 | ||
|
|
6057812a20 | ||
|
|
598e2c731b | ||
|
|
0742d8052f | ||
|
|
1713cded21 | ||
|
|
e7268dd314 | ||
|
|
50c2578cfd | ||
|
|
5a56d11e16 | ||
|
|
31e25a5965 | ||
|
|
85e1e2d4ee | ||
|
|
2d8bee0d6d | ||
|
|
e0d7083768 | ||
|
|
dbf96ff749 | ||
|
|
5f9eee2d12 | ||
|
|
d4c5ab7bf0 | ||
|
|
5ae6d71c37 | ||
|
|
d30d077939 | ||
|
|
aa18d532cf | ||
|
|
92d36f6791 | ||
|
|
5e82d0a316 | ||
|
|
b7b198947c | ||
|
|
fb69313d87 | ||
|
|
017db5b63c | ||
|
|
3f632835c5 | ||
|
|
e2d71acb9d | ||
|
|
8127d52ab3 | ||
|
|
6a55bbcd23 | ||
|
|
12af211c13 | ||
|
|
34594e5436 | ||
|
|
17a90c536f | ||
|
|
ef2e69dbf3 | ||
|
|
38dc9a8fe5 | ||
|
|
c3f8ef939c | ||
|
|
34cc434459 | ||
|
|
a3d52f9cc7 | ||
|
|
f56728fbca | ||
|
|
19ddf1b2e4 | ||
|
|
23ce79589c | ||
|
|
8cd82b5dbf | ||
|
|
dba6846a04 | ||
|
|
317eb65cc2 | ||
|
|
9817602ab5 | ||
|
|
8a7b37ab4c | ||
|
|
3b071ccb4e | ||
|
|
822a253eb5 | ||
|
|
aeb1bd8dbc | ||
|
|
df8290a290 | ||
|
|
9e20373cb0 | ||
|
|
6dc38e5bca | ||
|
|
f7efa2c7c7 | ||
|
|
d77d2f86da | ||
|
|
2276caba39 | ||
|
|
12d3d6cc0b | ||
|
|
630712e24c | ||
|
|
e1a112d26e | ||
|
|
1b46d64d71 | ||
|
|
38eda2f7b6 | ||
|
|
53b9c8ec97 | ||
|
|
7e8e95b748 | ||
|
|
7f51661e64 | ||
|
|
70023d2c4f | ||
|
|
c5d34f5ad5 | ||
|
|
8d3e51c205 | ||
|
|
b213753420 | ||
|
|
2eb8019325 | ||
|
|
9115cb7d31 | ||
|
|
62adad8f12 | ||
|
|
56f7ae0b46 | ||
|
|
446c1fb49a | ||
|
|
7d50625bd6 | ||
|
|
bd9ddc8b86 | ||
|
|
dd4fe4dcb4 | ||
|
|
1c174f263f | ||
|
|
d860e17b3b | ||
|
|
f83970bc6b | ||
|
|
87a245bf9c | ||
|
|
2d1afc634e | ||
|
|
e4f477dae0 | ||
|
|
8e210f8ea0 | ||
|
|
9c87056263 | ||
|
|
3251f19a19 | ||
|
|
299a2c89d1 | ||
|
|
c7241ca093 | ||
|
|
1a00e61239 | ||
|
|
f166e7f497 | ||
|
|
8dc08e4596 | ||
|
|
ead2c9273f | ||
|
|
5062543325 | ||
|
|
35e865bfb6 | ||
|
|
abb576c84f | ||
|
|
2d61ff7b88 | ||
|
|
e75b863f3b | ||
|
|
849cb2ea5a | ||
|
|
ab80677e3a | ||
|
|
bd7017d630 | ||
|
|
6e2bc01294 | ||
|
|
22c16f586b | ||
|
|
a42e3331d8 | ||
|
|
e14834c84e | ||
|
|
915a1c563b | ||
|
|
bc99cf83dd | ||
|
|
d00cbd4da7 | ||
|
|
721ff18a63 | ||
|
|
1a003fe4d3 | ||
|
|
68f78e1a30 | ||
|
|
7759d1d3fc | ||
|
|
738f9856a4 | ||
|
|
fbce8cd2f5 | ||
|
|
ea63c8e63a | ||
|
|
d8fea6afc4 | ||
|
|
ff16e1cd26 | ||
|
|
9b5ae1a322 | ||
|
|
8b8464163d |
98 changed files with 4746 additions and 878 deletions
|
|
@ -34,7 +34,7 @@ This Code of Conduct applies both within project spaces and in public spaces whe
|
||||||
individual is representing the project or its community.
|
individual is representing the project or its community.
|
||||||
|
|
||||||
Instances of abusive, harassing, or otherwise unacceptable behavior may be reported by
|
Instances of abusive, harassing, or otherwise unacceptable behavior may be reported by
|
||||||
contacting a project maintainer at tal.r@qodo.ai . All complaints will
|
contacting a project maintainer at dana.f@qodo.ai . All complaints will
|
||||||
be reviewed and investigated and will result in a response that is deemed necessary and
|
be reviewed and investigated and will result in a response that is deemed necessary and
|
||||||
appropriate to the circumstances. Maintainers are obligated to maintain confidentiality
|
appropriate to the circumstances. Maintainers are obligated to maintain confidentiality
|
||||||
with regard to the reporter of an incident.
|
with regard to the reporter of an incident.
|
||||||
|
|
|
||||||
271
README.md
271
README.md
|
|
@ -1,261 +1,36 @@
|
||||||
<div align="center">
|
# 🧠 PR Agent LEGACY STATUS (open source)
|
||||||
|
Originally created and open-sourced by Qodo - the team behind next-generation AI Code Review.
|
||||||
|
|
||||||
<div align="center">
|
## 🚀 About
|
||||||
|
PR Agent was the first AI assistant for pull requests, built by Qodo, and contributed to the open-source community.
|
||||||
|
It represents the first generation of intelligent code review - the project that started Qodo’s journey toward fully AI-driven development, Code Review.
|
||||||
|
If you enjoy this project, you’ll love the next-level PR Agent - Qodo free tier version, which is faster, smarter, and built for today’s workflows.
|
||||||
|
|
||||||
<picture>
|
🚀 Qodo includes a free user trial, 250 tokens, bonus tokens for active contributors, and 50% more advanced features than this open-source version.
|
||||||
<source media="(prefers-color-scheme: dark)" srcset="https://www.qodo.ai/wp-content/uploads/2025/02/PR-Agent-Purple-2.png">
|
|
||||||
<source media="(prefers-color-scheme: light)" srcset="https://www.qodo.ai/wp-content/uploads/2025/02/PR-Agent-Purple-2.png">
|
|
||||||
<img src="https://codium.ai/images/pr_agent/logo-light.png" alt="logo" width="330">
|
|
||||||
|
|
||||||
</picture>
|
If you have an open-source project, you can get the Qodo paid version for free for your project, powered by Google Gemini 2.5 Pro – [https://www.qodo.ai/solutions/open-source/](https://www.qodo.ai/solutions/open-source/)
|
||||||
<br/>
|
|
||||||
|
|
||||||
[Installation Guide](https://qodo-merge-docs.qodo.ai/installation/) |
|
|
||||||
[Usage Guide](https://qodo-merge-docs.qodo.ai/usage-guide/) |
|
|
||||||
[Tools Guide](https://qodo-merge-docs.qodo.ai/tools/) |
|
|
||||||
[Qodo Merge](https://qodo-merge-docs.qodo.ai/overview/pr_agent_pro/) 💎
|
|
||||||
|
|
||||||
PR-Agent aims to help efficiently review and handle pull requests, by providing AI feedback and suggestions
|
|
||||||
</div>
|
|
||||||
|
|
||||||
[](https://chromewebstore.google.com/detail/qodo-merge-ai-powered-cod/ephlnjeghhogofkifjloamocljapahnl)
|
|
||||||
[](https://github.com/apps/qodo-merge-pro/)
|
|
||||||
[](https://github.com/apps/qodo-merge-pro-for-open-source/)
|
|
||||||
[](https://discord.com/invite/SgSxuQ65GF)
|
|
||||||
<a href="https://github.com/Codium-ai/pr-agent/commits/main">
|
|
||||||
<img alt="GitHub" src="https://img.shields.io/github/last-commit/Codium-ai/pr-agent/main?style=for-the-badge" height="20">
|
|
||||||
</a>
|
|
||||||
</div>
|
|
||||||
|
|
||||||
## Table of Contents
|
|
||||||
|
|
||||||
- [Getting Started](#getting-started)
|
|
||||||
- [News and Updates](#news-and-updates)
|
|
||||||
- [Overview](#overview)
|
|
||||||
- [See It in Action](#see-it-in-action)
|
|
||||||
- [Try It Now](#try-it-now)
|
|
||||||
- [Qodo Merge 💎](#qodo-merge-)
|
|
||||||
- [How It Works](#how-it-works)
|
|
||||||
- [Why Use PR-Agent?](#why-use-pr-agent)
|
|
||||||
- [Data Privacy](#data-privacy)
|
|
||||||
- [Contributing](#contributing)
|
|
||||||
- [Links](#links)
|
|
||||||
|
|
||||||
## Getting Started
|
|
||||||
|
|
||||||
### Try it Instantly
|
|
||||||
Test PR-Agent on any public GitHub repository by commenting `@CodiumAI-Agent /improve`
|
|
||||||
|
|
||||||
### GitHub Action
|
|
||||||
Add automated PR reviews to your repository with a simple workflow file using [GitHub Action setup guide](https://qodo-merge-docs.qodo.ai/installation/github/#run-as-a-github-action)
|
|
||||||
|
|
||||||
#### Other Platforms
|
|
||||||
- [GitLab webhook setup](https://qodo-merge-docs.qodo.ai/installation/gitlab/)
|
|
||||||
- [BitBucket app installation](https://qodo-merge-docs.qodo.ai/installation/bitbucket/)
|
|
||||||
- [Azure DevOps setup](https://qodo-merge-docs.qodo.ai/installation/azure/)
|
|
||||||
|
|
||||||
### CLI Usage
|
|
||||||
Run PR-Agent locally on your repository via command line: [Local CLI setup guide](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#local-repo-cli)
|
|
||||||
|
|
||||||
### Discover Qodo Merge 💎
|
|
||||||
Zero-setup hosted solution with advanced features and priority support
|
|
||||||
- [Intro and Installation guide](https://qodo-merge-docs.qodo.ai/installation/qodo_merge/)
|
|
||||||
- [Plans & Pricing](https://www.qodo.ai/pricing/)
|
|
||||||
|
|
||||||
|
|
||||||
## News and Updates
|
|
||||||
|
|
||||||
## Jun 3, 2025
|
|
||||||
|
|
||||||
Qodo Merge now offers a simplified free tier 💎.
|
|
||||||
Organizations can use Qodo Merge at no cost, with a [monthly limit](https://qodo-merge-docs.qodo.ai/installation/qodo_merge/#cloud-users) of 75 PR reviews per organization.
|
|
||||||
|
|
||||||
## May 17, 2025
|
|
||||||
|
|
||||||
- v0.29 was [released](https://github.com/qodo-ai/pr-agent/releases)
|
|
||||||
- `Qodo Merge Pull Request Benchmark` was [released](https://qodo-merge-docs.qodo.ai/pr_benchmark/). This benchmark evaluates and compares the performance of LLMs in analyzing pull request code.
|
|
||||||
- `Recent Updates and Future Roadmap` page was added to the [Qodo Merge Docs](https://qodo-merge-docs.qodo.ai/recent_updates/)
|
|
||||||
|
|
||||||
## Apr 30, 2025
|
|
||||||
|
|
||||||
A new feature is now available in the `/improve` tool for Qodo Merge 💎 - Chat on code suggestions.
|
|
||||||
|
|
||||||
<img width="512" alt="image" src="https://codium.ai/images/pr_agent/improve_chat_on_code_suggestions_ask.png" />
|
|
||||||
|
|
||||||
Read more about it [here](https://qodo-merge-docs.qodo.ai/tools/improve/#chat-on-code-suggestions).
|
|
||||||
|
|
||||||
## Apr 16, 2025
|
|
||||||
|
|
||||||
New tool for Qodo Merge 💎 - `/scan_repo_discussions`.
|
|
||||||
|
|
||||||
<img width="635" alt="image" src="https://codium.ai/images/pr_agent/scan_repo_discussions_2.png" />
|
|
||||||
|
|
||||||
Read more about it [here](https://qodo-merge-docs.qodo.ai/tools/scan_repo_discussions/).
|
|
||||||
|
|
||||||
## Overview
|
|
||||||
|
|
||||||
<div style="text-align:left;">
|
|
||||||
|
|
||||||
Supported commands per platform:
|
|
||||||
|
|
||||||
| | | GitHub | GitLab | Bitbucket | Azure DevOps | Gitea |
|
|
||||||
|---------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------|:------:|:------:|:---------:|:------------:|:-----:|
|
|
||||||
| [TOOLS](https://qodo-merge-docs.qodo.ai/tools/) | [Describe](https://qodo-merge-docs.qodo.ai/tools/describe/) | ✅ | ✅ | ✅ | ✅ | ✅ |
|
|
||||||
| | [Review](https://qodo-merge-docs.qodo.ai/tools/review/) | ✅ | ✅ | ✅ | ✅ | ✅ |
|
|
||||||
| | [Improve](https://qodo-merge-docs.qodo.ai/tools/improve/) | ✅ | ✅ | ✅ | ✅ | ✅ |
|
|
||||||
| | [Ask](https://qodo-merge-docs.qodo.ai/tools/ask/) | ✅ | ✅ | ✅ | ✅ | |
|
|
||||||
| | ⮑ [Ask on code lines](https://qodo-merge-docs.qodo.ai/tools/ask/#ask-lines) | ✅ | ✅ | | | |
|
|
||||||
| | [Help Docs](https://qodo-merge-docs.qodo.ai/tools/help_docs/?h=auto#auto-approval) | ✅ | ✅ | ✅ | | |
|
|
||||||
| | [Update CHANGELOG](https://qodo-merge-docs.qodo.ai/tools/update_changelog/) | ✅ | ✅ | ✅ | ✅ | |
|
|
||||||
| | [Add Documentation](https://qodo-merge-docs.qodo.ai/tools/documentation/) 💎 | ✅ | ✅ | | | |
|
|
||||||
| | [Analyze](https://qodo-merge-docs.qodo.ai/tools/analyze/) 💎 | ✅ | ✅ | | | |
|
|
||||||
| | [Auto-Approve](https://qodo-merge-docs.qodo.ai/tools/improve/?h=auto#auto-approval) 💎 | ✅ | ✅ | ✅ | | |
|
|
||||||
| | [CI Feedback](https://qodo-merge-docs.qodo.ai/tools/ci_feedback/) 💎 | ✅ | | | | |
|
|
||||||
| | [Custom Prompt](https://qodo-merge-docs.qodo.ai/tools/custom_prompt/) 💎 | ✅ | ✅ | ✅ | | |
|
|
||||||
| | [Generate Custom Labels](https://qodo-merge-docs.qodo.ai/tools/custom_labels/) 💎 | ✅ | ✅ | | | |
|
|
||||||
| | [Generate Tests](https://qodo-merge-docs.qodo.ai/tools/test/) 💎 | ✅ | ✅ | | | |
|
|
||||||
| | [Implement](https://qodo-merge-docs.qodo.ai/tools/implement/) 💎 | ✅ | ✅ | ✅ | | |
|
|
||||||
| | [Scan Repo Discussions](https://qodo-merge-docs.qodo.ai/tools/scan_repo_discussions/) 💎 | ✅ | | | | |
|
|
||||||
| | [Similar Code](https://qodo-merge-docs.qodo.ai/tools/similar_code/) 💎 | ✅ | | | | |
|
|
||||||
| | [Ticket Context](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/) 💎 | ✅ | ✅ | ✅ | | |
|
|
||||||
| | [Utilizing Best Practices](https://qodo-merge-docs.qodo.ai/tools/improve/#best-practices) 💎 | ✅ | ✅ | ✅ | | |
|
|
||||||
| | [PR Chat](https://qodo-merge-docs.qodo.ai/chrome-extension/features/#pr-chat) 💎 | ✅ | | | | |
|
|
||||||
| | [Suggestion Tracking](https://qodo-merge-docs.qodo.ai/tools/improve/#suggestion-tracking) 💎 | ✅ | ✅ | | | |
|
|
||||||
| | | | | | | |
|
|
||||||
| [USAGE](https://qodo-merge-docs.qodo.ai/usage-guide/) | [CLI](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#local-repo-cli) | ✅ | ✅ | ✅ | ✅ | ✅ |
|
|
||||||
| | [App / webhook](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#github-app) | ✅ | ✅ | ✅ | ✅ | ✅ |
|
|
||||||
| | [Tagging bot](https://github.com/Codium-ai/pr-agent#try-it-now) | ✅ | | | | |
|
|
||||||
| | [Actions](https://qodo-merge-docs.qodo.ai/installation/github/#run-as-a-github-action) | ✅ | ✅ | ✅ | ✅ | |
|
|
||||||
| | | | | | | |
|
|
||||||
| [CORE](https://qodo-merge-docs.qodo.ai/core-abilities/) | [Adaptive and token-aware file patch fitting](https://qodo-merge-docs.qodo.ai/core-abilities/compression_strategy/) | ✅ | ✅ | ✅ | ✅ | |
|
|
||||||
| | [Auto Best Practices 💎](https://qodo-merge-docs.qodo.ai/core-abilities/auto_best_practices/) | ✅ | | | | |
|
|
||||||
| | [Chat on code suggestions](https://qodo-merge-docs.qodo.ai/core-abilities/chat_on_code_suggestions/) | ✅ | ✅ | | | |
|
|
||||||
| | [Code Validation 💎](https://qodo-merge-docs.qodo.ai/core-abilities/code_validation/) | ✅ | ✅ | ✅ | ✅ | |
|
|
||||||
| | [Dynamic context](https://qodo-merge-docs.qodo.ai/core-abilities/dynamic_context/) | ✅ | ✅ | ✅ | ✅ | |
|
|
||||||
| | [Fetching ticket context](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/) | ✅ | ✅ | ✅ | | |
|
|
||||||
| | [Global and wiki configurations](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/) 💎 | ✅ | ✅ | ✅ | | |
|
|
||||||
| | [Impact Evaluation](https://qodo-merge-docs.qodo.ai/core-abilities/impact_evaluation/) 💎 | ✅ | ✅ | | | |
|
|
||||||
| | [Incremental Update](https://qodo-merge-docs.qodo.ai/core-abilities/incremental_update/) | ✅ | | | | |
|
|
||||||
| | [Interactivity](https://qodo-merge-docs.qodo.ai/core-abilities/interactivity/) | ✅ | ✅ | | | |
|
|
||||||
| | [Local and global metadata](https://qodo-merge-docs.qodo.ai/core-abilities/metadata/) | ✅ | ✅ | ✅ | ✅ | |
|
|
||||||
| | [Multiple models support](https://qodo-merge-docs.qodo.ai/usage-guide/changing_a_model/) | ✅ | ✅ | ✅ | ✅ | |
|
|
||||||
| | [PR compression](https://qodo-merge-docs.qodo.ai/core-abilities/compression_strategy/) | ✅ | ✅ | ✅ | ✅ | |
|
|
||||||
| | [PR interactive actions](https://www.qodo.ai/images/pr_agent/pr-actions.mp4) 💎 | ✅ | ✅ | | | |
|
|
||||||
| | [RAG context enrichment](https://qodo-merge-docs.qodo.ai/core-abilities/rag_context_enrichment/) | ✅ | | ✅ | | |
|
|
||||||
| | [Self reflection](https://qodo-merge-docs.qodo.ai/core-abilities/self_reflection/) | ✅ | ✅ | ✅ | ✅ | |
|
|
||||||
| | [Static code analysis](https://qodo-merge-docs.qodo.ai/core-abilities/static_code_analysis/) 💎 | ✅ | ✅ | | | |
|
|
||||||
- 💎 means this feature is available only in [Qodo Merge](https://www.qodo.ai/pricing/)
|
|
||||||
|
|
||||||
[//]: # (- Support for additional git providers is described in [here](./docs/Full_environments.md))
|
|
||||||
___
|
|
||||||
|
|
||||||
## See It in Action
|
|
||||||
|
|
||||||
</div>
|
|
||||||
<h4><a href="https://github.com/Codium-ai/pr-agent/pull/530">/describe</a></h4>
|
|
||||||
<div align="center">
|
|
||||||
<p float="center">
|
|
||||||
<img src="https://www.codium.ai/images/pr_agent/describe_new_short_main.png" width="512">
|
|
||||||
</p>
|
|
||||||
</div>
|
|
||||||
<hr>
|
|
||||||
|
|
||||||
<h4><a href="https://github.com/Codium-ai/pr-agent/pull/732#issuecomment-1975099151">/review</a></h4>
|
|
||||||
<div align="center">
|
|
||||||
<p float="center">
|
|
||||||
<kbd>
|
|
||||||
<img src="https://www.codium.ai/images/pr_agent/review_new_short_main.png" width="512">
|
|
||||||
</kbd>
|
|
||||||
</p>
|
|
||||||
</div>
|
|
||||||
<hr>
|
|
||||||
|
|
||||||
<h4><a href="https://github.com/Codium-ai/pr-agent/pull/732#issuecomment-1975099159">/improve</a></h4>
|
|
||||||
<div align="center">
|
|
||||||
<p float="center">
|
|
||||||
<kbd>
|
|
||||||
<img src="https://www.codium.ai/images/pr_agent/improve_new_short_main.png" width="512">
|
|
||||||
</kbd>
|
|
||||||
</p>
|
|
||||||
</div>
|
|
||||||
|
|
||||||
<div align="left">
|
|
||||||
|
|
||||||
</div>
|
|
||||||
<hr>
|
|
||||||
|
|
||||||
## Try It Now
|
|
||||||
|
|
||||||
Try the Claude Sonnet powered PR-Agent instantly on _your public GitHub repository_. Just mention `@CodiumAI-Agent` and add the desired command in any PR comment. The agent will generate a response based on your command.
|
|
||||||
For example, add a comment to any pull request with the following text:
|
|
||||||
|
|
||||||
```
|
|
||||||
@CodiumAI-Agent /review
|
|
||||||
```
|
|
||||||
|
|
||||||
and the agent will respond with a review of your PR.
|
|
||||||
|
|
||||||
Note that this is a promotional bot, suitable only for initial experimentation.
|
|
||||||
It does not have 'edit' access to your repo, for example, so it cannot update the PR description or add labels (`@CodiumAI-Agent /describe` will publish PR description as a comment). In addition, the bot cannot be used on private repositories, as it does not have access to the files there.
|
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
## Qodo Merge 💎
|
## ✨ Advanced Features in Qodo
|
||||||
|
|
||||||
[Qodo Merge](https://www.qodo.ai/pricing/) is a hosted version of PR-Agent, provided by Qodo. It is available for a monthly fee, and provides the following benefits:
|
### 🧭 PR → Ticket Automation
|
||||||
|
Seamlessly links pull requests to your project tracking system for end-to-end visibility.
|
||||||
|
|
||||||
1. **Fully managed** - We take care of everything for you - hosting, models, regular updates, and more. Installation is as simple as signing up and adding the Qodo Merge app to your GitHub/GitLab/BitBucket repo.
|
### ✅ Auto Best Practices
|
||||||
2. **Improved privacy** - No data will be stored or used to train models. Qodo Merge will employ zero data retention, and will use an OpenAI account with zero data retention.
|
Learns your team’s standards and automatically enforces them during code reviews.
|
||||||
3. **Improved support** - Qodo Merge users will receive priority support, and will be able to request new features and capabilities.
|
|
||||||
4. **Extra features** - In addition to the benefits listed above, Qodo Merge will emphasize more customization, and the usage of static code analysis, in addition to LLM logic, to improve results.
|
|
||||||
See [here](https://qodo-merge-docs.qodo.ai/overview/pr_agent_pro/) for a list of features available in Qodo Merge.
|
|
||||||
|
|
||||||
## How It Works
|
### 🧪 Code Validation
|
||||||
|
Performs advanced static and semantic analysis to catch issues before merge.
|
||||||
|
|
||||||
The following diagram illustrates PR-Agent tools and their flow:
|
### 💬 PR Chat Interface
|
||||||
|
Lets you converse with your PR to explain, summarize, or suggest improvements instantly.
|
||||||
|
|
||||||
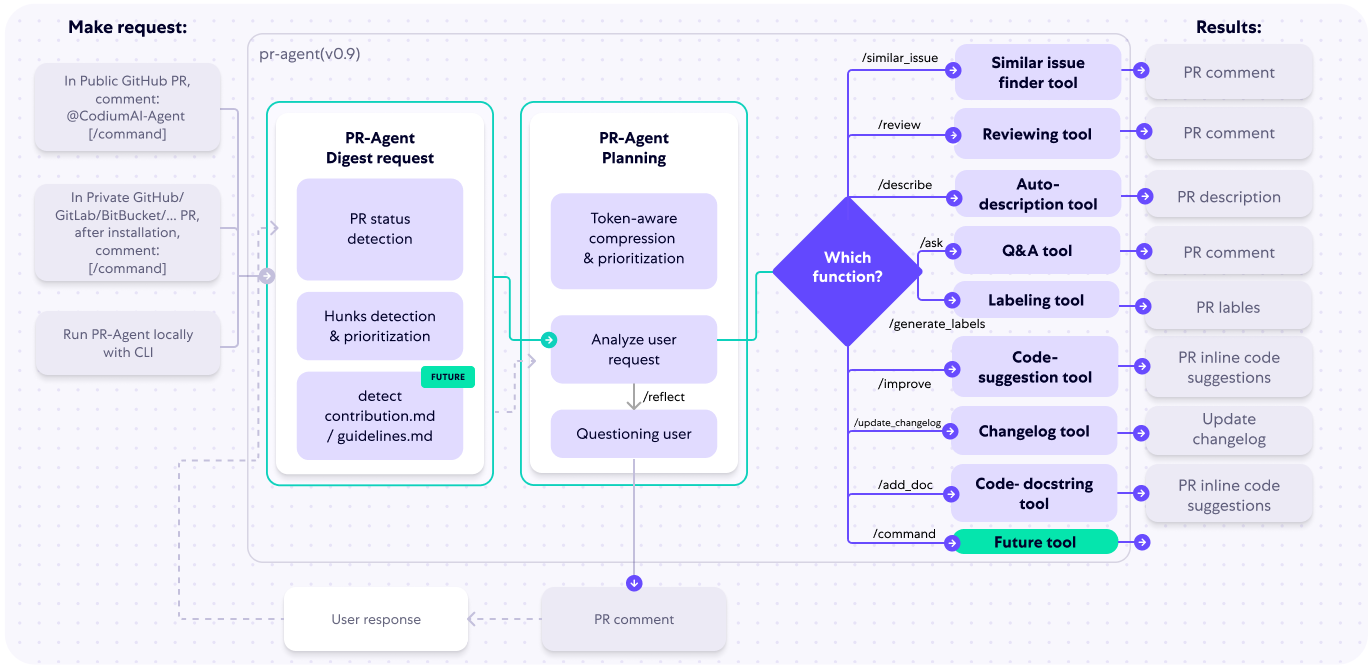
|
### 🔍 Impact Evaluation
|
||||||
|
Analyzes the business and technical effect of each change before approval.
|
||||||
|
|
||||||
Check out the [PR Compression strategy](https://qodo-merge-docs.qodo.ai/core-abilities/#pr-compression-strategy) page for more details on how we convert a code diff to a manageable LLM prompt
|
---
|
||||||
|
|
||||||
## Why Use PR-Agent?
|
## ❤️ Community
|
||||||
|
This open-source release remains here as a community contribution from Qodo — the origin of modern AI-powered code collaboration.
|
||||||
A reasonable question that can be asked is: `"Why use PR-Agent? What makes it stand out from existing tools?"`
|
We’re proud to share it and inspire developers worldwide.
|
||||||
|
|
||||||
Here are some advantages of PR-Agent:
|
|
||||||
|
|
||||||
- We emphasize **real-life practical usage**. Each tool (review, improve, ask, ...) has a single LLM call, no more. We feel that this is critical for realistic team usage - obtaining an answer quickly (~30 seconds) and affordably.
|
|
||||||
- Our [PR Compression strategy](https://qodo-merge-docs.qodo.ai/core-abilities/#pr-compression-strategy) is a core ability that enables to effectively tackle both short and long PRs.
|
|
||||||
- Our JSON prompting strategy enables us to have **modular, customizable tools**. For example, the '/review' tool categories can be controlled via the [configuration](pr_agent/settings/configuration.toml) file. Adding additional categories is easy and accessible.
|
|
||||||
- We support **multiple git providers** (GitHub, GitLab, BitBucket), **multiple ways** to use the tool (CLI, GitHub Action, GitHub App, Docker, ...), and **multiple models** (GPT, Claude, Deepseek, ...)
|
|
||||||
|
|
||||||
## Data Privacy
|
|
||||||
|
|
||||||
### Self-hosted PR-Agent
|
|
||||||
|
|
||||||
- If you host PR-Agent with your OpenAI API key, it is between you and OpenAI. You can read their API data privacy policy here:
|
|
||||||
https://openai.com/enterprise-privacy
|
|
||||||
|
|
||||||
### Qodo-hosted Qodo Merge 💎
|
|
||||||
|
|
||||||
- When using Qodo Merge 💎, hosted by Qodo, we will not store any of your data, nor will we use it for training. You will also benefit from an OpenAI account with zero data retention.
|
|
||||||
|
|
||||||
- For certain clients, Qodo-hosted Qodo Merge will use Qodo’s proprietary models — if this is the case, you will be notified.
|
|
||||||
|
|
||||||
- No passive collection of Code and Pull Requests’ data — Qodo Merge will be active only when you invoke it, and it will then extract and analyze only data relevant to the executed command and queried pull request.
|
|
||||||
|
|
||||||
### Qodo Merge Chrome extension
|
|
||||||
|
|
||||||
- The [Qodo Merge Chrome extension](https://chromewebstore.google.com/detail/qodo-merge-ai-powered-cod/ephlnjeghhogofkifjloamocljapahnl) serves solely to modify the visual appearance of a GitHub PR screen. It does not transmit any user's repo or pull request code. Code is only sent for processing when a user submits a GitHub comment that activates a PR-Agent tool, in accordance with the standard privacy policy of Qodo-Merge.
|
|
||||||
|
|
||||||
## Contributing
|
|
||||||
|
|
||||||
To contribute to the project, get started by reading our [Contributing Guide](https://github.com/qodo-ai/pr-agent/blob/b09eec265ef7d36c232063f76553efb6b53979ff/CONTRIBUTING.md).
|
|
||||||
|
|
||||||
## Links
|
|
||||||
|
|
||||||
- Discord community: https://discord.com/invite/SgSxuQ65GF
|
|
||||||
- Qodo site: https://www.qodo.ai/
|
|
||||||
- Blog: https://www.qodo.ai/blog/
|
|
||||||
- Troubleshooting: https://www.qodo.ai/blog/technical-faq-and-troubleshooting/
|
|
||||||
- Support: support@qodo.ai
|
|
||||||
|
|
|
||||||
|
|
@ -59,6 +59,6 @@ steps:
|
||||||
|
|
||||||
We take the security of PR-Agent seriously. If you discover a security vulnerability, please report it immediately to:
|
We take the security of PR-Agent seriously. If you discover a security vulnerability, please report it immediately to:
|
||||||
|
|
||||||
Email: tal.r@qodo.ai
|
Email: security@qodo.ai
|
||||||
|
|
||||||
Please include a description of the vulnerability, steps to reproduce, and the affected PR-Agent version.
|
Please include a description of the vulnerability, steps to reproduce, and the affected PR-Agent version.
|
||||||
|
|
|
||||||
5
docs/docs/.gitbook.yaml
Normal file
5
docs/docs/.gitbook.yaml
Normal file
|
|
@ -0,0 +1,5 @@
|
||||||
|
root: ./
|
||||||
|
|
||||||
|
structure:
|
||||||
|
readme: ../README.md
|
||||||
|
summary: ./summary.md
|
||||||
|
|
@ -19,7 +19,6 @@
|
||||||
</div>
|
</div>
|
||||||
|
|
||||||
<style>
|
<style>
|
||||||
Untitled
|
|
||||||
.search-section {
|
.search-section {
|
||||||
max-width: 800px;
|
max-width: 800px;
|
||||||
margin: 0 auto;
|
margin: 0 auto;
|
||||||
|
|
@ -202,7 +201,23 @@ h1 {
|
||||||
|
|
||||||
<script>
|
<script>
|
||||||
window.addEventListener('load', function() {
|
window.addEventListener('load', function() {
|
||||||
function displayResults(responseText) {
|
function extractText(responseText) {
|
||||||
|
try {
|
||||||
|
console.log('responseText: ', responseText);
|
||||||
|
const results = JSON.parse(responseText);
|
||||||
|
const msg = results.message;
|
||||||
|
|
||||||
|
if (!msg || msg.trim() === '') {
|
||||||
|
return "No results found";
|
||||||
|
}
|
||||||
|
return msg;
|
||||||
|
} catch (error) {
|
||||||
|
console.error('Error parsing results:', error);
|
||||||
|
throw new Error("Failed parsing response message");
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
function displayResults(msg) {
|
||||||
const resultsContainer = document.getElementById('results');
|
const resultsContainer = document.getElementById('results');
|
||||||
const spinner = document.getElementById('spinner');
|
const spinner = document.getElementById('spinner');
|
||||||
const searchContainer = document.querySelector('.search-container');
|
const searchContainer = document.querySelector('.search-container');
|
||||||
|
|
@ -214,8 +229,6 @@ window.addEventListener('load', function() {
|
||||||
searchContainer.scrollIntoView({ behavior: 'smooth', block: 'start' });
|
searchContainer.scrollIntoView({ behavior: 'smooth', block: 'start' });
|
||||||
|
|
||||||
try {
|
try {
|
||||||
const results = JSON.parse(responseText);
|
|
||||||
|
|
||||||
marked.setOptions({
|
marked.setOptions({
|
||||||
breaks: true,
|
breaks: true,
|
||||||
gfm: true,
|
gfm: true,
|
||||||
|
|
@ -223,7 +236,7 @@ window.addEventListener('load', function() {
|
||||||
sanitize: false
|
sanitize: false
|
||||||
});
|
});
|
||||||
|
|
||||||
const htmlContent = marked.parse(results.message);
|
const htmlContent = marked.parse(msg);
|
||||||
|
|
||||||
resultsContainer.className = 'markdown-content';
|
resultsContainer.className = 'markdown-content';
|
||||||
resultsContainer.innerHTML = htmlContent;
|
resultsContainer.innerHTML = htmlContent;
|
||||||
|
|
@ -242,7 +255,7 @@ window.addEventListener('load', function() {
|
||||||
}, 100);
|
}, 100);
|
||||||
} catch (error) {
|
} catch (error) {
|
||||||
console.error('Error parsing results:', error);
|
console.error('Error parsing results:', error);
|
||||||
resultsContainer.innerHTML = '<div class="error-message">Error processing results</div>';
|
resultsContainer.innerHTML = '<div class="error-message">Cannot process results</div>';
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|
@ -275,24 +288,24 @@ window.addEventListener('load', function() {
|
||||||
body: JSON.stringify(data)
|
body: JSON.stringify(data)
|
||||||
};
|
};
|
||||||
|
|
||||||
// const API_ENDPOINT = 'http://0.0.0.0:3000/api/v1/docs_help';
|
//const API_ENDPOINT = 'http://0.0.0.0:3000/api/v1/docs_help';
|
||||||
const API_ENDPOINT = 'https://help.merge.qodo.ai/api/v1/docs_help';
|
const API_ENDPOINT = 'https://help.merge.qodo.ai/api/v1/docs_help';
|
||||||
|
|
||||||
const response = await fetch(API_ENDPOINT, options);
|
const response = await fetch(API_ENDPOINT, options);
|
||||||
|
const responseText = await response.text();
|
||||||
|
const msg = extractText(responseText);
|
||||||
|
|
||||||
if (!response.ok) {
|
if (!response.ok) {
|
||||||
throw new Error(`HTTP error! status: ${response.status}`);
|
throw new Error(`An error (${response.status}) occurred during search: "${msg}"`);
|
||||||
}
|
}
|
||||||
|
|
||||||
const responseText = await response.text();
|
displayResults(msg);
|
||||||
displayResults(responseText);
|
|
||||||
} catch (error) {
|
} catch (error) {
|
||||||
spinner.style.display = 'none';
|
spinner.style.display = 'none';
|
||||||
resultsContainer.innerHTML = `
|
const errorDiv = document.createElement('div');
|
||||||
<div class="error-message">
|
errorDiv.className = 'error-message';
|
||||||
An error occurred while searching. Please try again later.
|
errorDiv.textContent = error instanceof Error ? error.message : String(error);
|
||||||
</div>
|
resultsContainer.replaceChildren(errorDiv);
|
||||||
`;
|
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -1,8 +1,10 @@
|
||||||
|
`Platforms supported: GitHub Cloud`
|
||||||
|
|
||||||
[Qodo Merge Chrome extension](https://chromewebstore.google.com/detail/pr-agent-chrome-extension/ephlnjeghhogofkifjloamocljapahnl){:target="_blank"} is a collection of tools that integrates seamlessly with your GitHub environment, aiming to enhance your Git usage experience, and providing AI-powered capabilities to your PRs.
|
[Qodo Merge Chrome extension](https://chromewebstore.google.com/detail/pr-agent-chrome-extension/ephlnjeghhogofkifjloamocljapahnl){:target="_blank"} is a collection of tools that integrates seamlessly with your GitHub environment, aiming to enhance your Git usage experience, and providing AI-powered capabilities to your PRs.
|
||||||
|
|
||||||
With a single-click installation you will gain access to a context-aware chat on your pull requests code, a toolbar extension with multiple AI feedbacks, Qodo Merge filters, and additional abilities.
|
With a single-click installation you will gain access to a context-aware chat on your pull requests code, a toolbar extension with multiple AI feedbacks, Qodo Merge filters, and additional abilities.
|
||||||
|
|
||||||
The extension is powered by top code models like Claude 3.7 Sonnet and o4-mini. All the extension's features are free to use on public repositories.
|
The extension is powered by top code models like GPT-5. All the extension's features are free to use on public repositories.
|
||||||
|
|
||||||
For private repositories, you will need to install [Qodo Merge](https://github.com/apps/qodo-merge-pro){:target="_blank"} in addition to the extension.
|
For private repositories, you will need to install [Qodo Merge](https://github.com/apps/qodo-merge-pro){:target="_blank"} in addition to the extension.
|
||||||
For a demonstration of how to install Qodo Merge and use it with the Chrome extension, please refer to the tutorial video at the provided [link](https://codium.ai/images/pr_agent/private_repos.mp4){:target="_blank"}.
|
For a demonstration of how to install Qodo Merge and use it with the Chrome extension, please refer to the tutorial video at the provided [link](https://codium.ai/images/pr_agent/private_repos.mp4){:target="_blank"}.
|
||||||
|
|
@ -12,3 +14,101 @@ For a demonstration of how to install Qodo Merge and use it with the Chrome exte
|
||||||
### Supported browsers
|
### Supported browsers
|
||||||
|
|
||||||
The extension is supported on all Chromium-based browsers, including Google Chrome, Arc, Opera, Brave, and Microsoft Edge.
|
The extension is supported on all Chromium-based browsers, including Google Chrome, Arc, Opera, Brave, and Microsoft Edge.
|
||||||
|
|
||||||
|
## Features
|
||||||
|
|
||||||
|
### PR chat
|
||||||
|
|
||||||
|
The PR-Chat feature allows to freely chat with your PR code, within your GitHub environment.
|
||||||
|
It will seamlessly use the PR as context to your chat session, and provide AI-powered feedback.
|
||||||
|
|
||||||
|
To enable private chat, simply install the Qodo Merge Chrome extension. After installation, each PR's file-changed tab will include a chat box, where you may ask questions about your code.
|
||||||
|
This chat session is **private**, and won't be visible to other users.
|
||||||
|
|
||||||
|
All open-source repositories are supported.
|
||||||
|
For private repositories, you will also need to install Qodo Merge. After installation, make sure to open at least one new PR to fully register your organization. Once done, you can chat with both new and existing PRs across all installed repositories.
|
||||||
|
|
||||||
|
#### Context-aware PR chat
|
||||||
|
|
||||||
|
Qodo Merge constructs a comprehensive context for each pull request, incorporating the PR description, commit messages, and code changes with extended dynamic context. This contextual information, along with additional PR-related data, forms the foundation for an AI-powered chat session. The agent then leverages this rich context to provide intelligent, tailored responses to user inquiries about the pull request.
|
||||||
|
|
||||||
|
<img src="https://codium.ai/images/pr_agent/pr_chat_1.png" width="768">
|
||||||
|
<img src="https://codium.ai/images/pr_agent/pr_chat_2.png" width="768">
|
||||||
|
|
||||||
|
### Toolbar extension
|
||||||
|
|
||||||
|
With Qodo Merge Chrome extension, it's [easier than ever](https://www.youtube.com/watch?v=gT5tli7X4H4) to interactively configure and experiment with the different tools and configuration options.
|
||||||
|
|
||||||
|
For private repositories, after you found the setup that works for you, you can also easily export it as a persistent configuration file, and use it for automatic commands.
|
||||||
|
|
||||||
|
<img src="https://codium.ai/images/pr_agent/toolbar1.png" width="512">
|
||||||
|
|
||||||
|
<img src="https://codium.ai/images/pr_agent/toolbar2.png" width="512">
|
||||||
|
|
||||||
|
### Qodo Merge filters
|
||||||
|
|
||||||
|
Qodo Merge filters is a sidepanel option. that allows you to filter different message in the conversation tab.
|
||||||
|
|
||||||
|
For example, you can choose to present only message from Qodo Merge, or filter those messages, focusing only on user's comments.
|
||||||
|
|
||||||
|
<img src="https://codium.ai/images/pr_agent/pr_agent_filters1.png" width="256">
|
||||||
|
|
||||||
|
<img src="https://codium.ai/images/pr_agent/pr_agent_filters2.png" width="256">
|
||||||
|
|
||||||
|
### Enhanced code suggestions
|
||||||
|
|
||||||
|
Qodo Merge Chrome extension adds the following capabilities to code suggestions tool's comments:
|
||||||
|
|
||||||
|
- Auto-expand the table when you are viewing a code block, to avoid clipping.
|
||||||
|
- Adding a "quote-and-reply" button, that enables to address and comment on a specific suggestion (for example, asking the author to fix the issue)
|
||||||
|
|
||||||
|
<img src="https://codium.ai/images/pr_agent/chrome_extension_code_suggestion1.png" width="512">
|
||||||
|
|
||||||
|
<img src="https://codium.ai/images/pr_agent/chrome_extension_code_suggestion2.png" width="512">
|
||||||
|
|
||||||
|
## Data Privacy
|
||||||
|
|
||||||
|
We take your code's security and privacy seriously:
|
||||||
|
|
||||||
|
- The Chrome extension will not send your code to any external servers.
|
||||||
|
- For private repositories, we will first validate the user's identity and permissions. After authentication, we generate responses using the existing Qodo Merge integration.
|
||||||
|
|
||||||
|
## Options and Configurations
|
||||||
|
|
||||||
|
### Accessing the Options Page
|
||||||
|
|
||||||
|
To access the options page for the Qodo Merge Chrome extension:
|
||||||
|
|
||||||
|
1. Find the extension icon in your Chrome toolbar (usually in the top-right corner of your browser)
|
||||||
|
2. Right-click on the extension icon
|
||||||
|
3. Select "Options" from the context menu that appears
|
||||||
|
|
||||||
|
Alternatively, you can access the options page directly using this URL:
|
||||||
|
|
||||||
|
[chrome-extension://ephlnjeghhogofkifjloamocljapahnl/options.html](chrome-extension://ephlnjeghhogofkifjloamocljapahnl/options.html)
|
||||||
|
|
||||||
|
<img src="https://codium.ai/images/pr_agent/chrome_ext_options.png" width="256">
|
||||||
|
|
||||||
|
### Configuration Options
|
||||||
|
|
||||||
|
<img src="https://codium.ai/images/pr_agent/chrome_ext_settings_page.png" width="512">
|
||||||
|
|
||||||
|
#### API Base Host
|
||||||
|
|
||||||
|
For single-tenant customers, you can configure the extension to communicate directly with your company's Qodo Merge server instance.
|
||||||
|
|
||||||
|
To set this up:
|
||||||
|
|
||||||
|
- Enter your organization's Qodo Merge API endpoint in the "API Base Host" field
|
||||||
|
- This endpoint should be provided by your Qodo DevOps Team
|
||||||
|
|
||||||
|
*Note: The extension does not send your code to the server, but only triggers your previously installed Qodo Merge application.*
|
||||||
|
|
||||||
|
#### Interface Options
|
||||||
|
|
||||||
|
You can customize the extension's interface by:
|
||||||
|
|
||||||
|
- Toggling the "Show Qodo Merge Toolbar" option
|
||||||
|
- When disabled, the toolbar will not appear in your Github comment bar
|
||||||
|
|
||||||
|
Remember to click "Save Settings" after making any changes.
|
||||||
|
|
@ -41,13 +41,9 @@ When presenting the suggestions generated by the `improve` tool, Qodo Merge will
|
||||||
|
|
||||||
Teams and companies can also manually define their own [custom best practices](https://qodo-merge-docs.qodo.ai/tools/improve/#best-practices) in Qodo Merge.
|
Teams and companies can also manually define their own [custom best practices](https://qodo-merge-docs.qodo.ai/tools/improve/#best-practices) in Qodo Merge.
|
||||||
|
|
||||||
When custom best practices exist, Qodo Merge will still generate an 'auto best practices' wiki file, though it won't be used by the `improve` tool.
|
When custom best practices exist, Qodo Merge will use both the auto-generated best practices and your custom best practices together. The auto best practices file provides additional insights derived from suggestions your team found valuable enough to implement, while also demonstrating effective patterns for writing AI-friendly best practices.
|
||||||
However, this auto-generated file can still serve two valuable purposes:
|
|
||||||
|
|
||||||
1. It can help enhance your custom best practices with additional insights derived from suggestions your team found valuable enough to implement
|
We recommend utilizing both auto and custom best practices to get the most comprehensive code improvement suggestions for your team.
|
||||||
2. It demonstrates effective patterns for writing AI-friendly best practices
|
|
||||||
|
|
||||||
Even when using custom best practices, we recommend regularly reviewing the auto best practices file to refine your custom rules.
|
|
||||||
|
|
||||||
## Relevant configurations
|
## Relevant configurations
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -9,9 +9,10 @@ This integration enriches the review process by automatically surfacing relevant
|
||||||
|
|
||||||
**Ticket systems supported**:
|
**Ticket systems supported**:
|
||||||
|
|
||||||
- [GitHub](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/#github-issues-integration)
|
- [GitHub/Gitlab Issues](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/#githubgitlab-issues-integration)
|
||||||
- [Jira (💎)](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/#jira-integration)
|
- [Jira (💎)](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/#jira-integration)
|
||||||
- [Linear (💎)](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/#linear-integration)
|
- [Linear (💎)](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/#linear-integration)
|
||||||
|
- [Monday (💎)](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/#monday-integration)
|
||||||
|
|
||||||
**Ticket data fetched:**
|
**Ticket data fetched:**
|
||||||
|
|
||||||
|
|
@ -53,17 +54,17 @@ A `PR Code Verified` label indicates the PR code meets ticket requirements, but
|
||||||
|
|
||||||
#### Configuration options
|
#### Configuration options
|
||||||
|
|
||||||
-
|
-
|
||||||
|
|
||||||
By default, the tool will automatically validate if the PR complies with the referenced ticket.
|
By default, the `review` tool will automatically validate if the PR complies with the referenced ticket.
|
||||||
If you want to disable this feedback, add the following line to your configuration file:
|
If you want to disable this feedback, add the following line to your configuration file:
|
||||||
|
|
||||||
```toml
|
```toml
|
||||||
[pr_reviewer]
|
[pr_reviewer]
|
||||||
require_ticket_analysis_review=false
|
require_ticket_analysis_review=false
|
||||||
```
|
```
|
||||||
|
|
||||||
-
|
-
|
||||||
|
|
||||||
If you set:
|
If you set:
|
||||||
```toml
|
```toml
|
||||||
|
|
@ -71,18 +72,48 @@ A `PR Code Verified` label indicates the PR code meets ticket requirements, but
|
||||||
check_pr_additional_content=true
|
check_pr_additional_content=true
|
||||||
```
|
```
|
||||||
(default: `false`)
|
(default: `false`)
|
||||||
|
|
||||||
the `review` tool will also validate that the PR code doesn't contain any additional content that is not related to the ticket. If it does, the PR will be labeled at best as `PR Code Verified`, and the `review` tool will provide a comment with the additional unrelated content found in the PR code.
|
the `review` tool will also validate that the PR code doesn't contain any additional content that is not related to the ticket. If it does, the PR will be labeled at best as `PR Code Verified`, and the `review` tool will provide a comment with the additional unrelated content found in the PR code.
|
||||||
|
|
||||||
## GitHub Issues Integration
|
### Compliance tool
|
||||||
|
|
||||||
Qodo Merge will automatically recognize GitHub issues mentioned in the PR description and fetch the issue content.
|
The `compliance` tool also uses ticket context to validate that PR changes fulfill the requirements specified in linked tickets.
|
||||||
Examples of valid GitHub issue references:
|
|
||||||
|
|
||||||
- `https://github.com/<ORG_NAME>/<REPO_NAME>/issues/<ISSUE_NUMBER>`
|
#### Configuration options
|
||||||
|
|
||||||
|
-
|
||||||
|
|
||||||
|
By default, the `compliance` tool will automatically validate if the PR complies with the referenced ticket.
|
||||||
|
If you want to disable ticket compliance checking in the compliance tool, add the following line to your configuration file:
|
||||||
|
|
||||||
|
```toml
|
||||||
|
[pr_compliance]
|
||||||
|
require_ticket_analysis_review=false
|
||||||
|
```
|
||||||
|
|
||||||
|
-
|
||||||
|
|
||||||
|
If you set:
|
||||||
|
```toml
|
||||||
|
[pr_compliance]
|
||||||
|
check_pr_additional_content=true
|
||||||
|
```
|
||||||
|
(default: `false`)
|
||||||
|
|
||||||
|
the `compliance` tool will also validate that the PR code doesn't contain any additional content that is not related to the ticket.
|
||||||
|
|
||||||
|
## GitHub/Gitlab Issues Integration
|
||||||
|
|
||||||
|
Qodo Merge will automatically recognize GitHub/Gitlab issues mentioned in the PR description and fetch the issue content.
|
||||||
|
Examples of valid GitHub/Gitlab issue references:
|
||||||
|
|
||||||
|
- `https://github.com/<ORG_NAME>/<REPO_NAME>/issues/<ISSUE_NUMBER>` or `https://gitlab.com/<ORG_NAME>/<REPO_NAME>/-/issues/<ISSUE_NUMBER>`
|
||||||
- `#<ISSUE_NUMBER>`
|
- `#<ISSUE_NUMBER>`
|
||||||
- `<ORG_NAME>/<REPO_NAME>#<ISSUE_NUMBER>`
|
- `<ORG_NAME>/<REPO_NAME>#<ISSUE_NUMBER>`
|
||||||
|
|
||||||
|
Branch names can also be used to link issues, for example:
|
||||||
|
- `123-fix-bug` (where `123` is the issue number)
|
||||||
|
|
||||||
Since Qodo Merge is integrated with GitHub, it doesn't require any additional configuration to fetch GitHub issues.
|
Since Qodo Merge is integrated with GitHub, it doesn't require any additional configuration to fetch GitHub issues.
|
||||||
|
|
||||||
## Jira Integration 💎
|
## Jira Integration 💎
|
||||||
|
|
@ -104,7 +135,7 @@ Installation steps:
|
||||||
2. Click on the Connect **Jira Cloud** button to connect the Jira Cloud app
|
2. Click on the Connect **Jira Cloud** button to connect the Jira Cloud app
|
||||||
|
|
||||||
3. Click the `accept` button.<br>
|
3. Click the `accept` button.<br>
|
||||||
{width=384}
|
{width=384}
|
||||||
|
|
||||||
4. After installing the app, you will be redirected to the Qodo Merge registration page. and you will see a success message.<br>
|
4. After installing the app, you will be redirected to the Qodo Merge registration page. and you will see a success message.<br>
|
||||||
{width=384}
|
{width=384}
|
||||||
|
|
@ -448,3 +479,49 @@ Name your branch with the ticket ID as a prefix (e.g., `ABC-123-feature-descript
|
||||||
```
|
```
|
||||||
|
|
||||||
Replace `[ORG_ID]` with your Linear organization identifier.
|
Replace `[ORG_ID]` with your Linear organization identifier.
|
||||||
|
|
||||||
|
## Monday Integration 💎
|
||||||
|
|
||||||
|
### Monday App Authentication
|
||||||
|
The recommended way to authenticate with Monday is to connect the Monday app through the Qodo Merge portal.
|
||||||
|
|
||||||
|
Installation steps:
|
||||||
|
|
||||||
|
1. Go to the [Qodo Merge integrations page](https://app.qodo.ai/qodo-merge/integrations)
|
||||||
|
2. Navigate to the **Integrations** tab
|
||||||
|
3. Click on the **Monday** button to connect the Monday app
|
||||||
|
4. Follow the authentication flow to authorize Qodo Merge to access your Monday workspace
|
||||||
|
5. Once connected, Qodo Merge will be able to fetch Monday ticket context for your PRs
|
||||||
|
|
||||||
|
### Monday Ticket Context
|
||||||
|
`Ticket Context and Ticket Compliance are supported for Monday items, but not yet available in the "PR to Ticket" feature.`
|
||||||
|
|
||||||
|
When Qodo Merge processes your PRs, it extracts the following information from Monday items:
|
||||||
|
|
||||||
|
* **Item ID and Name:** The unique identifier and title of the Monday item
|
||||||
|
* **Item URL:** Direct link to the Monday item in your workspace
|
||||||
|
* **Ticket Description:** All long text type columns and their values from the item
|
||||||
|
* **Status and Labels:** Current status values and color-coded labels for quick context
|
||||||
|
* **Sub-items:** Names, IDs, and descriptions of all related sub-items with hierarchical structure
|
||||||
|
|
||||||
|
### How Monday Items are Detected
|
||||||
|
Qodo Merge automatically detects Monday items from:
|
||||||
|
|
||||||
|
* PR Descriptions: Full Monday URLs like https://workspace.monday.com/boards/123/pulses/456
|
||||||
|
* Branch Names: Item IDs in branch names (6-12 digit patterns) - requires `monday_base_url` configuration
|
||||||
|
|
||||||
|
### Configuration Setup (Optional)
|
||||||
|
If you want to extract Monday item references from branch names or use standalone item IDs, you need to set the `monday_base_url` in your configuration file:
|
||||||
|
|
||||||
|
To support Monday ticket referencing from branch names, item IDs (6-12 digits) should be part of the branch names and you need to configure `monday_base_url`:
|
||||||
|
```toml
|
||||||
|
[monday]
|
||||||
|
monday_base_url = "https://your_monday_workspace.monday.com"
|
||||||
|
```
|
||||||
|
|
||||||
|
Examples of supported branch name patterns:
|
||||||
|
|
||||||
|
* `feature/123456789` → extracts item ID 123456789
|
||||||
|
* `bugfix/456789012-login-fix` → extracts item ID 456789012
|
||||||
|
* `123456789` → extracts item ID 123456789
|
||||||
|
* `456789012-login-fix` → extracts item ID 456789012
|
||||||
|
|
|
||||||
19
docs/docs/core-abilities/high_level_suggestions.md
Normal file
19
docs/docs/core-abilities/high_level_suggestions.md
Normal file
|
|
@ -0,0 +1,19 @@
|
||||||
|
# High-level Code Suggestions 💎
|
||||||
|
|
||||||
|
`Supported Git Platforms: GitHub, GitLab, Bitbucket Cloud, Bitbucket Server`
|
||||||
|
|
||||||
|
## Overview
|
||||||
|
High-level code suggestions, generated by the `improve` tool, offer big-picture code suggestions for your pull request. They focus on broader improvements rather than local fixes, and provide before-and-after code snippets to illustrate the recommended changes and guide implementation.
|
||||||
|
|
||||||
|
### How it works
|
||||||
|
|
||||||
|
=== "Example of a high-level suggestion"
|
||||||
|
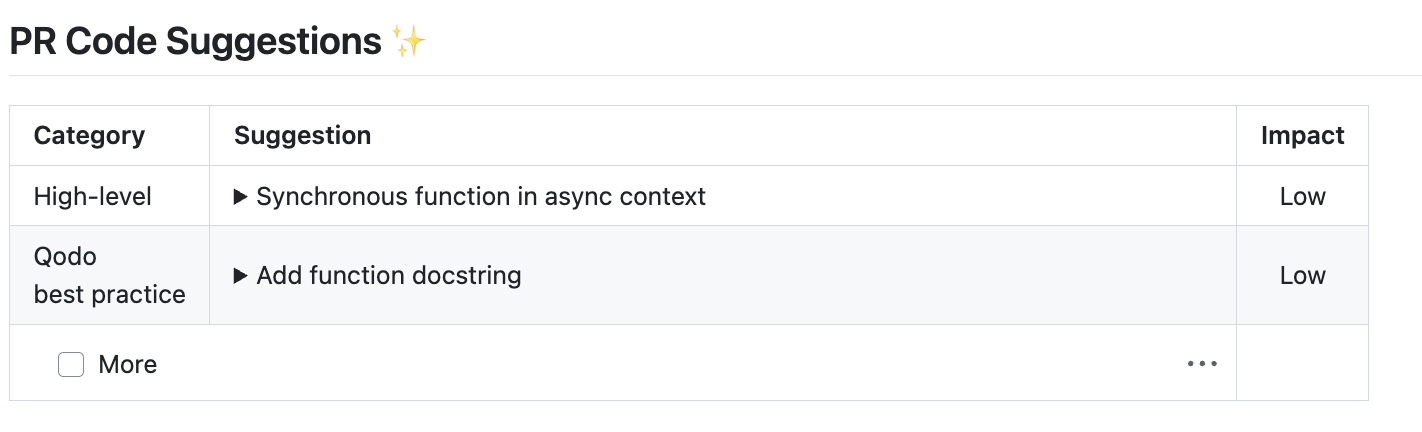{width=512}
|
||||||
|
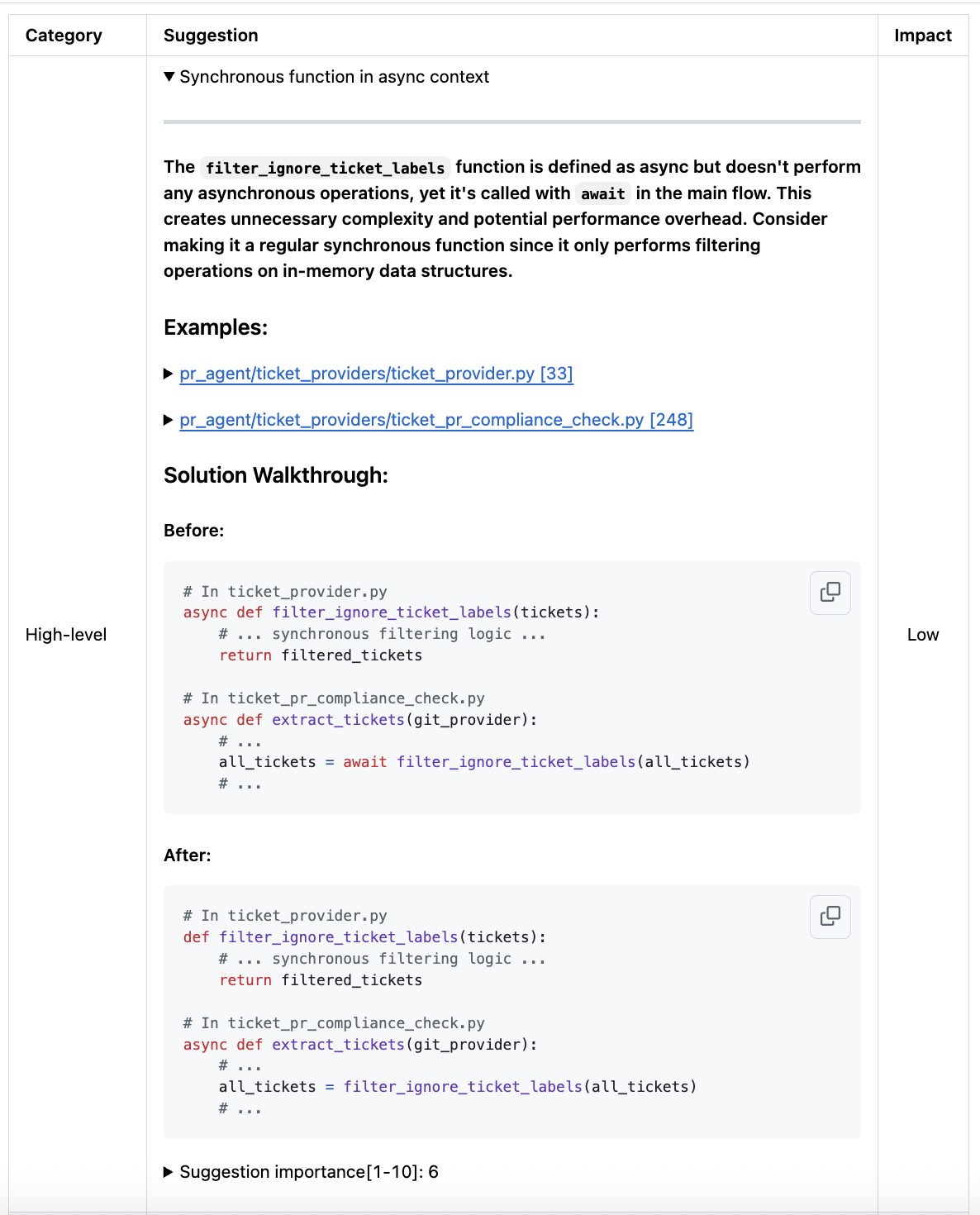{width=512}
|
||||||
|
|
||||||
|
___
|
||||||
|
|
||||||
|
### Benefits for Developers
|
||||||
|
|
||||||
|
- Help spot systematic issues in the pull request
|
||||||
|
- Give the author another review angle, while giving them the freedom on how to address the suggestion.
|
||||||
|
|
@ -1,6 +1,6 @@
|
||||||
# Incremental Update 💎
|
# Incremental Update 💎
|
||||||
|
|
||||||
`Supported Git Platforms: GitHub`
|
`Supported Git Platforms: GitHub, GitLab (Both cloud & server. For server: Version 17 and above)`
|
||||||
|
|
||||||
## Overview
|
## Overview
|
||||||
The Incremental Update feature helps users focus on feedback for their newest changes, making large PRs more manageable.
|
The Incremental Update feature helps users focus on feedback for their newest changes, making large PRs more manageable.
|
||||||
|
|
|
||||||
|
|
@ -5,10 +5,11 @@ Qodo Merge utilizes a variety of core abilities to provide a comprehensive and e
|
||||||
- [Auto approval](https://qodo-merge-docs.qodo.ai/core-abilities/auto_approval/)
|
- [Auto approval](https://qodo-merge-docs.qodo.ai/core-abilities/auto_approval/)
|
||||||
- [Auto best practices](https://qodo-merge-docs.qodo.ai/core-abilities/auto_best_practices/)
|
- [Auto best practices](https://qodo-merge-docs.qodo.ai/core-abilities/auto_best_practices/)
|
||||||
- [Chat on code suggestions](https://qodo-merge-docs.qodo.ai/core-abilities/chat_on_code_suggestions/)
|
- [Chat on code suggestions](https://qodo-merge-docs.qodo.ai/core-abilities/chat_on_code_suggestions/)
|
||||||
- [Code validation](https://qodo-merge-docs.qodo.ai/core-abilities/code_validation/)
|
- [Chrome extension](https://qodo-merge-docs.qodo.ai/chrome-extension/)
|
||||||
- [Compression strategy](https://qodo-merge-docs.qodo.ai/core-abilities/compression_strategy/)
|
- [Code validation](https://qodo-merge-docs.qodo.ai/core-abilities/code_validation/) <!-- - [Compression strategy](https://qodo-merge-docs.qodo.ai/core-abilities/compression_strategy/) -->
|
||||||
- [Dynamic context](https://qodo-merge-docs.qodo.ai/core-abilities/dynamic_context/)
|
- [Dynamic context](https://qodo-merge-docs.qodo.ai/core-abilities/dynamic_context/)
|
||||||
- [Fetching ticket context](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/)
|
- [Fetching ticket context](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/)
|
||||||
|
- [High-level Suggestions](https://qodo-merge-docs.qodo.ai/core-abilities/high_level_suggestions/)
|
||||||
- [Impact evaluation](https://qodo-merge-docs.qodo.ai/core-abilities/impact_evaluation/)
|
- [Impact evaluation](https://qodo-merge-docs.qodo.ai/core-abilities/impact_evaluation/)
|
||||||
- [Incremental Update](https://qodo-merge-docs.qodo.ai/core-abilities/incremental_update/)
|
- [Incremental Update](https://qodo-merge-docs.qodo.ai/core-abilities/incremental_update/)
|
||||||
- [Interactivity](https://qodo-merge-docs.qodo.ai/core-abilities/interactivity/)
|
- [Interactivity](https://qodo-merge-docs.qodo.ai/core-abilities/interactivity/)
|
||||||
|
|
|
||||||
|
|
@ -1,6 +1,6 @@
|
||||||
# RAG Context Enrichment 💎
|
# RAG Context Enrichment 💎
|
||||||
|
|
||||||
`Supported Git Platforms: GitHub, Bitbucket Data Center`
|
`Supported Git Platforms: GitHub, GitLab, Bitbucket, Bitbucket Data Center`
|
||||||
|
|
||||||
!!! info "Prerequisites"
|
!!! info "Prerequisites"
|
||||||
- RAG is available only for Qodo enterprise plan users, with single tenant or on-premises setup.
|
- RAG is available only for Qodo enterprise plan users, with single tenant or on-premises setup.
|
||||||
|
|
@ -44,11 +44,18 @@ enable_rag=true
|
||||||
|
|
||||||
RAG capability is exclusively available in the following tools:
|
RAG capability is exclusively available in the following tools:
|
||||||
|
|
||||||
=== "`/review`"
|
=== "`/ask`"
|
||||||
The [`/review`](https://qodo-merge-docs.qodo.ai/tools/review/) tool offers the _Focus area from RAG data_ which contains feedback based on the RAG references analysis.
|
The [`/ask`](https://qodo-merge-docs.qodo.ai/tools/ask/) tool can access broader repository context through the RAG feature when answering questions that go beyond the PR scope alone.
|
||||||
The complete list of references found relevant to the PR will be shown in the _References_ section, helping developers understand the broader context by exploring the provided references.
|
The _References_ section displays the additional repository content consulted to formulate the answer.
|
||||||
|
|
||||||
{width=640}
|
{width=640}
|
||||||
|
|
||||||
|
|
||||||
|
=== "`/compliance`"
|
||||||
|
The [`/compliance`](https://qodo-merge-docs.qodo.ai/tools/compliance/) tool offers the _Codebase Code Duplication Compliance_ section which contains feedback based on the RAG references.
|
||||||
|
This section highlights possible code duplication issues in the PR, providing developers with insights into potential code quality concerns.
|
||||||
|
|
||||||
|
{width=640}
|
||||||
|
|
||||||
=== "`/implement`"
|
=== "`/implement`"
|
||||||
The [`/implement`](https://qodo-merge-docs.qodo.ai/tools/implement/) tool utilizes the RAG feature to provide comprehensive context of the repository codebase, allowing it to generate more refined code output.
|
The [`/implement`](https://qodo-merge-docs.qodo.ai/tools/implement/) tool utilizes the RAG feature to provide comprehensive context of the repository codebase, allowing it to generate more refined code output.
|
||||||
|
|
@ -56,11 +63,11 @@ RAG capability is exclusively available in the following tools:
|
||||||
|
|
||||||
{width=640}
|
{width=640}
|
||||||
|
|
||||||
=== "`/ask`"
|
=== "`/review`"
|
||||||
The [`/ask`](https://qodo-merge-docs.qodo.ai/tools/ask/) tool can access broader repository context through the RAG feature when answering questions that go beyond the PR scope alone.
|
The [`/review`](https://qodo-merge-docs.qodo.ai/tools/review/) tool offers the _Focus area from RAG data_ which contains feedback based on the RAG references analysis.
|
||||||
The _References_ section displays the additional repository content consulted to formulate the answer.
|
The complete list of references found relevant to the PR will be shown in the _References_ section, helping developers understand the broader context by exploring the provided references.
|
||||||
|
|
||||||
{width=640}
|
{width=640}
|
||||||
|
|
||||||
## Limitations
|
## Limitations
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -8,7 +8,7 @@ By combining static code analysis with LLM capabilities, Qodo Merge can provide
|
||||||
It scans the PR code changes, finds all the code components (methods, functions, classes) that changed, and enables to interactively generate tests, docs, code suggestions and similar code search for each component.
|
It scans the PR code changes, finds all the code components (methods, functions, classes) that changed, and enables to interactively generate tests, docs, code suggestions and similar code search for each component.
|
||||||
|
|
||||||
!!! note "Language that are currently supported:"
|
!!! note "Language that are currently supported:"
|
||||||
Python, Java, C++, JavaScript, TypeScript, C#, Go.
|
Python, Java, C++, JavaScript, TypeScript, C#, Go, Kotlin
|
||||||
|
|
||||||
## Capabilities
|
## Capabilities
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -26,7 +26,7 @@ ___
|
||||||
|
|
||||||
#### Answer:<span style="display:none;">2</span>
|
#### Answer:<span style="display:none;">2</span>
|
||||||
|
|
||||||
- Modern AI models, like Claude Sonnet and GPT-4, are improving rapidly but remain imperfect. Users should critically evaluate all suggestions rather than accepting them automatically.
|
- Modern AI models, like Claude Sonnet and GPT-5, are improving rapidly but remain imperfect. Users should critically evaluate all suggestions rather than accepting them automatically.
|
||||||
- AI errors are rare, but possible. A main value from reviewing the code suggestions lies in their high probability of catching **mistakes or bugs made by the PR author**. We believe it's worth spending 30-60 seconds reviewing suggestions, even if some aren't relevant, as this practice can enhance code quality and prevent bugs in production.
|
- AI errors are rare, but possible. A main value from reviewing the code suggestions lies in their high probability of catching **mistakes or bugs made by the PR author**. We believe it's worth spending 30-60 seconds reviewing suggestions, even if some aren't relevant, as this practice can enhance code quality and prevent bugs in production.
|
||||||
|
|
||||||
|
|
||||||
|
|
@ -66,7 +66,7 @@ ___
|
||||||
___
|
___
|
||||||
|
|
||||||
??? note "Q: Can Qodo Merge review draft/offline PRs?"
|
??? note "Q: Can Qodo Merge review draft/offline PRs?"
|
||||||
#### Answer:<span style="display:none;">5</span>
|
#### Answer:<span style="display:none;">6</span>
|
||||||
|
|
||||||
Yes. While Qodo Merge won't automatically review draft PRs, you can still get feedback by manually requesting it through [online commenting](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#online-usage).
|
Yes. While Qodo Merge won't automatically review draft PRs, you can still get feedback by manually requesting it through [online commenting](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#online-usage).
|
||||||
|
|
||||||
|
|
@ -74,7 +74,7 @@ ___
|
||||||
___
|
___
|
||||||
|
|
||||||
??? note "Q: Can the 'Review effort' feedback be calibrated or customized?"
|
??? note "Q: Can the 'Review effort' feedback be calibrated or customized?"
|
||||||
#### Answer:<span style="display:none;">5</span>
|
#### Answer:<span style="display:none;">7</span>
|
||||||
|
|
||||||
Yes, you can customize review effort estimates using the `extra_instructions` configuration option (see [documentation](https://qodo-merge-docs.qodo.ai/tools/review/#configuration-options)).
|
Yes, you can customize review effort estimates using the `extra_instructions` configuration option (see [documentation](https://qodo-merge-docs.qodo.ai/tools/review/#configuration-options)).
|
||||||
|
|
||||||
|
|
@ -88,3 +88,35 @@ ___
|
||||||
Note: The effort levels (1-5) are primarily meant for _comparative_ purposes, helping teams prioritize reviewing smaller PRs first. The actual review duration may vary, as the focus is on providing consistent relative effort estimates.
|
Note: The effort levels (1-5) are primarily meant for _comparative_ purposes, helping teams prioritize reviewing smaller PRs first. The actual review duration may vary, as the focus is on providing consistent relative effort estimates.
|
||||||
|
|
||||||
___
|
___
|
||||||
|
|
||||||
|
??? note "Q: How to reduce the noise generated by Qodo Merge?"
|
||||||
|
#### Answer:<span style="display:none;">3</span>
|
||||||
|
|
||||||
|
The default configuration of Qodo Merge is designed to balance helpful feedback with noise reduction. It reduces noise through several approaches:
|
||||||
|
|
||||||
|
- Auto-feedback uses three highly structured tools (`/describe`, `/review`, and `/improve`), designed to be accessible at a glance without creating large visual overload
|
||||||
|
- Suggestions are presented in a table format rather than as committable comments, which are far noisier
|
||||||
|
- The 'File Walkthrough' section is folded by default, as it tends to be verbose
|
||||||
|
- Intermediate comments are avoided when creating new PRs (like "Qodo Merge is now reviewing your PR..."), which would generate email noise
|
||||||
|
|
||||||
|
From our experience, especially in large teams or organizations, complaints about "noise" sometimes stem from the following issues:
|
||||||
|
|
||||||
|
- **Feedback from multiple bots**: When multiple bots provide feedback on the same PR, it creates confusion and noise. We recommend using Qodo Merge as the primary feedback tool to streamline the process and reduce redundancy.
|
||||||
|
- **Getting familiar with the tool**: Unlike many tools that provide feedback only on demand, Qodo Merge automatically analyzes and suggests improvements for every code change. While this proactive approach can feel intimidating at first, it's designed to continuously enhance code quality and catch bugs and problems when they occur. We recommend reviewing [this guide](https://qodo-merge-docs.qodo.ai/tools/improve/#understanding-ai-code-suggestions) to help align expectations and maximize the value of Qodo Merge's auto-feedback.
|
||||||
|
|
||||||
|
Therefore, at a global configuration level, we recommend using the default configuration, which is designed to reduce noise while providing valuable feedback.
|
||||||
|
|
||||||
|
However, if you still find the feedback too noisy, you can adjust the configuration. Since each user and team has different needs, it's definitely possible - and even recommended - to adjust configurations for specific repos as needed.
|
||||||
|
Ways to adjust the configuration for noise reduction include for example:
|
||||||
|
|
||||||
|
- [Score thresholds for code suggestions](https://qodo-merge-docs.qodo.ai/tools/improve/#configuration-options)
|
||||||
|
- [Utilizing the `extra_instructions` field for more tailored feedback](https://qodo-merge-docs.qodo.ai/tools/improve/#extra-instructions)
|
||||||
|
- [Controlling which tools run automatically](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#github-app-automatic-tools-when-a-new-pr-is-opened)
|
||||||
|
|
||||||
|
Note that some users may prefer the opposite - more thorough and detailed feedback. Qodo Merge is designed to be flexible and customizable, allowing you to tailor the feedback to your team's specific needs and preferences.
|
||||||
|
Examples of ways to increase feedback include:
|
||||||
|
|
||||||
|
- [`Exhaustive` code suggestions](https://qodo-merge-docs.qodo.ai/tools/improve/#controlling-suggestions-depth)
|
||||||
|
- [Dual-publishing mode](https://qodo-merge-docs.qodo.ai/tools/improve/#dual-publishing-mode)
|
||||||
|
- [Interactive usage](https://qodo-merge-docs.qodo.ai/core-abilities/interactivity/)
|
||||||
|
___
|
||||||
|
|
|
||||||
|
|
@ -9,7 +9,7 @@ Qodo Merge is a hosted version of PR-Agent, designed for companies and teams tha
|
||||||
|
|
||||||
- See the [Tools Guide](./tools/index.md) for a detailed description of the different tools.
|
- See the [Tools Guide](./tools/index.md) for a detailed description of the different tools.
|
||||||
|
|
||||||
- See the [Video Tutorials](https://www.youtube.com/playlist?list=PLRTpyDOSgbwFMA_VBeKMnPLaaZKwjGBFT) for practical demonstrations on how to use the tools.
|
- See the video tutorials [[1](https://www.youtube.com/playlist?list=PLRTpyDOSgbwFMA_VBeKMnPLaaZKwjGBFT), [2](https://www.youtube.com/watch?v=7-yJLd7zu40)] for practical demonstrations on how to use the tools.
|
||||||
|
|
||||||
## Docs Smart Search
|
## Docs Smart Search
|
||||||
|
|
||||||
|
|
@ -24,53 +24,54 @@ To search the documentation site using natural language:
|
||||||
|
|
||||||
## Features
|
## Features
|
||||||
|
|
||||||
PR-Agent and Qodo Merge offers extensive pull request functionalities across various git providers:
|
PR-Agent and Qodo Merge offer comprehensive pull request functionalities integrated with various git providers:
|
||||||
|
|
||||||
| | | GitHub | GitLab | Bitbucket | Azure DevOps | Gitea |
|
| | | GitHub | GitLab | Bitbucket | Azure DevOps | Gitea |
|
||||||
| ----- |---------------------------------------------------------------------------------------------------------------------|:------:|:------:|:---------:|:------------:|:-----:|
|
| ----- |---------------------------------------------------------------------------------------------------------------------|:------:|:------:|:---------:|:------------:|:-----:|
|
||||||
| [TOOLS](https://qodo-merge-docs.qodo.ai/tools/) | [Describe](https://qodo-merge-docs.qodo.ai/tools/describe/) | ✅ | ✅ | ✅ | ✅ | ✅ |
|
| [TOOLS](https://qodo-merge-docs.qodo.ai/tools/) | [Describe](https://qodo-merge-docs.qodo.ai/tools/describe/) | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||||
| | [Review](https://qodo-merge-docs.qodo.ai/tools/review/) | ✅ | ✅ | ✅ | ✅ | ✅ |
|
| | [Review](https://qodo-merge-docs.qodo.ai/tools/review/) | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||||
| | [Improve](https://qodo-merge-docs.qodo.ai/tools/improve/) | ✅ | ✅ | ✅ | ✅ | ✅ |
|
| | [Improve](https://qodo-merge-docs.qodo.ai/tools/improve/) | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||||
| | [Ask](https://qodo-merge-docs.qodo.ai/tools/ask/) | ✅ | ✅ | ✅ | ✅ | |
|
| | [Ask](https://qodo-merge-docs.qodo.ai/tools/ask/) | ✅ | ✅ | ✅ | ✅ | |
|
||||||
| | ⮑ [Ask on code lines](https://qodo-merge-docs.qodo.ai/tools/ask/#ask-lines) | ✅ | ✅ | | | |
|
| | ⮑ [Ask on code lines](https://qodo-merge-docs.qodo.ai/tools/ask/#ask-lines) | ✅ | ✅ | | | |
|
||||||
| | [Help Docs](https://qodo-merge-docs.qodo.ai/tools/help_docs/?h=auto#auto-approval) | ✅ | ✅ | ✅ | | |
|
| | [Help Docs](https://qodo-merge-docs.qodo.ai/tools/help_docs/?h=auto#auto-approval) | ✅ | ✅ | ✅ | | |
|
||||||
| | [Update CHANGELOG](https://qodo-merge-docs.qodo.ai/tools/update_changelog/) | ✅ | ✅ | ✅ | ✅ | |
|
| | [Update CHANGELOG](https://qodo-merge-docs.qodo.ai/tools/update_changelog/) | ✅ | ✅ | ✅ | ✅ | |
|
||||||
| | [Add Documentation](https://qodo-merge-docs.qodo.ai/tools/documentation/) 💎 | ✅ | ✅ | | | |
|
| | [Add Documentation](https://qodo-merge-docs.qodo.ai/tools/documentation/) 💎 | ✅ | ✅ | | | |
|
||||||
| | [Analyze](https://qodo-merge-docs.qodo.ai/tools/analyze/) 💎 | ✅ | ✅ | | | |
|
| | [Analyze](https://qodo-merge-docs.qodo.ai/tools/analyze/) 💎 | ✅ | ✅ | | | |
|
||||||
| | [Auto-Approve](https://qodo-merge-docs.qodo.ai/tools/improve/?h=auto#auto-approval) 💎 | ✅ | ✅ | ✅ | | |
|
| | [Auto-Approve](https://qodo-merge-docs.qodo.ai/tools/improve/?h=auto#auto-approval) 💎 | ✅ | ✅ | ✅ | | |
|
||||||
| | [CI Feedback](https://qodo-merge-docs.qodo.ai/tools/ci_feedback/) 💎 | ✅ | | | | |
|
| | [CI Feedback](https://qodo-merge-docs.qodo.ai/tools/ci_feedback/) 💎 | ✅ | | | | |
|
||||||
|
| | [Compliance](https://qodo-merge-docs.qodo.ai/tools/compliance/) 💎 | ✅ | ✅ | ✅ | | |
|
||||||
| | [Custom Prompt](https://qodo-merge-docs.qodo.ai/tools/custom_prompt/) 💎 | ✅ | ✅ | ✅ | | |
|
| | [Custom Prompt](https://qodo-merge-docs.qodo.ai/tools/custom_prompt/) 💎 | ✅ | ✅ | ✅ | | |
|
||||||
| | [Generate Custom Labels](https://qodo-merge-docs.qodo.ai/tools/custom_labels/) 💎 | ✅ | ✅ | | | |
|
| | [Generate Custom Labels](https://qodo-merge-docs.qodo.ai/tools/custom_labels/) 💎 | ✅ | ✅ | | | |
|
||||||
| | [Generate Tests](https://qodo-merge-docs.qodo.ai/tools/test/) 💎 | ✅ | ✅ | | | |
|
| | [Generate Tests](https://qodo-merge-docs.qodo.ai/tools/test/) 💎 | ✅ | ✅ | | | |
|
||||||
| | [Implement](https://qodo-merge-docs.qodo.ai/tools/implement/) 💎 | ✅ | ✅ | ✅ | | |
|
| | [Implement](https://qodo-merge-docs.qodo.ai/tools/implement/) 💎 | ✅ | ✅ | ✅ | | |
|
||||||
|
| | [PR Chat](https://qodo-merge-docs.qodo.ai/chrome-extension/features/#pr-chat) 💎 | ✅ | | | | |
|
||||||
|
| | [PR to Ticket](https://qodo-merge-docs.qodo.ai/tools/pr_to_ticket/) 💎 | ✅ | ✅ | ✅ | | |
|
||||||
| | [Scan Repo Discussions](https://qodo-merge-docs.qodo.ai/tools/scan_repo_discussions/) 💎 | ✅ | | | | |
|
| | [Scan Repo Discussions](https://qodo-merge-docs.qodo.ai/tools/scan_repo_discussions/) 💎 | ✅ | | | | |
|
||||||
| | [Similar Code](https://qodo-merge-docs.qodo.ai/tools/similar_code/) 💎 | ✅ | | | | |
|
| | [Similar Code](https://qodo-merge-docs.qodo.ai/tools/similar_code/) 💎 | ✅ | | | | |
|
||||||
| | [Ticket Context](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/) 💎 | ✅ | ✅ | ✅ | | |
|
|
||||||
| | [Utilizing Best Practices](https://qodo-merge-docs.qodo.ai/tools/improve/#best-practices) 💎 | ✅ | ✅ | ✅ | | |
|
|
||||||
| | [PR Chat](https://qodo-merge-docs.qodo.ai/chrome-extension/features/#pr-chat) 💎 | ✅ | | | | |
|
|
||||||
| | [Suggestion Tracking](https://qodo-merge-docs.qodo.ai/tools/improve/#suggestion-tracking) 💎 | ✅ | ✅ | | | |
|
| | [Suggestion Tracking](https://qodo-merge-docs.qodo.ai/tools/improve/#suggestion-tracking) 💎 | ✅ | ✅ | | | |
|
||||||
|
| | [Utilizing Best Practices](https://qodo-merge-docs.qodo.ai/tools/improve/#best-practices) 💎 | ✅ | ✅ | ✅ | | |
|
||||||
| | | | | | | |
|
| | | | | | | |
|
||||||
| [USAGE](https://qodo-merge-docs.qodo.ai/usage-guide/) | [CLI](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#local-repo-cli) | ✅ | ✅ | ✅ | ✅ | ✅ |
|
| [USAGE](https://qodo-merge-docs.qodo.ai/usage-guide/) | [CLI](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#local-repo-cli) | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||||
| | [App / webhook](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#github-app) | ✅ | ✅ | ✅ | ✅ | ✅ |
|
| | [App / webhook](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#github-app) | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||||
| | [Tagging bot](https://github.com/Codium-ai/pr-agent#try-it-now) | ✅ | | | | |
|
| | [Tagging bot](https://github.com/Codium-ai/pr-agent#try-it-now) | ✅ | | | | |
|
||||||
| | [Actions](https://qodo-merge-docs.qodo.ai/installation/github/#run-as-a-github-action) | ✅ | ✅ | ✅ | ✅ | |
|
| | [Actions](https://qodo-merge-docs.qodo.ai/installation/github/#run-as-a-github-action) | ✅ | ✅ | ✅ | ✅ | |
|
||||||
| | | | | | | |
|
| | | | | | | |
|
||||||
| [CORE](https://qodo-merge-docs.qodo.ai/core-abilities/) | [Adaptive and token-aware file patch fitting](https://qodo-merge-docs.qodo.ai/core-abilities/compression_strategy/) | ✅ | ✅ | ✅ | ✅ | |
|
| [CORE](https://qodo-merge-docs.qodo.ai/core-abilities/) | [Adaptive and token-aware file patch fitting](https://qodo-merge-docs.qodo.ai/core-abilities/compression_strategy/) | ✅ | ✅ | ✅ | ✅ | |
|
||||||
| | [Auto Best Practices 💎](https://qodo-merge-docs.qodo.ai/core-abilities/auto_best_practices/) | ✅ | | | | |
|
| | [Auto Best Practices 💎](https://qodo-merge-docs.qodo.ai/core-abilities/auto_best_practices/) | ✅ | | | | |
|
||||||
| | [Chat on code suggestions](https://qodo-merge-docs.qodo.ai/core-abilities/chat_on_code_suggestions/) | ✅ | ✅ | | | |
|
| | [Chat on code suggestions](https://qodo-merge-docs.qodo.ai/core-abilities/chat_on_code_suggestions/) | ✅ | ✅ | | | |
|
||||||
| | [Code Validation 💎](https://qodo-merge-docs.qodo.ai/core-abilities/code_validation/) | ✅ | ✅ | ✅ | ✅ | |
|
| | [Code Validation 💎](https://qodo-merge-docs.qodo.ai/core-abilities/code_validation/) | ✅ | ✅ | ✅ | ✅ | |
|
||||||
| | [Dynamic context](https://qodo-merge-docs.qodo.ai/core-abilities/dynamic_context/) | ✅ | ✅ | ✅ | ✅ | |
|
| | [Dynamic context](https://qodo-merge-docs.qodo.ai/core-abilities/dynamic_context/) | ✅ | ✅ | ✅ | ✅ | |
|
||||||
| | [Fetching ticket context](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/) | ✅ | ✅ | ✅ | | |
|
| | [Fetching ticket context](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/) | ✅ | ✅ | ✅ | | |
|
||||||
| | [Global and wiki configurations](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/) 💎 | ✅ | ✅ | ✅ | | |
|
| | [Global and wiki configurations](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/) 💎 | ✅ | ✅ | ✅ | | |
|
||||||
| | [Impact Evaluation](https://qodo-merge-docs.qodo.ai/core-abilities/impact_evaluation/) 💎 | ✅ | ✅ | | | |
|
| | [Impact Evaluation](https://qodo-merge-docs.qodo.ai/core-abilities/impact_evaluation/) 💎 | ✅ | ✅ | | | |
|
||||||
| | [Incremental Update 💎](https://qodo-merge-docs.qodo.ai/core-abilities/incremental_update/) | ✅ | | | | |
|
| | [Incremental Update 💎](https://qodo-merge-docs.qodo.ai/core-abilities/incremental_update/) | ✅ | | | | |
|
||||||
| | [Interactivity](https://qodo-merge-docs.qodo.ai/core-abilities/interactivity/) | ✅ | ✅ | | | |
|
| | [Interactivity](https://qodo-merge-docs.qodo.ai/core-abilities/interactivity/) | ✅ | ✅ | | | |
|
||||||
| | [Local and global metadata](https://qodo-merge-docs.qodo.ai/core-abilities/metadata/) | ✅ | ✅ | ✅ | ✅ | |
|
| | [Local and global metadata](https://qodo-merge-docs.qodo.ai/core-abilities/metadata/) | ✅ | ✅ | ✅ | ✅ | |
|
||||||
| | [Multiple models support](https://qodo-merge-docs.qodo.ai/usage-guide/changing_a_model/) | ✅ | ✅ | ✅ | ✅ | |
|
| | [Multiple models support](https://qodo-merge-docs.qodo.ai/usage-guide/changing_a_model/) | ✅ | ✅ | ✅ | ✅ | |
|
||||||
| | [PR compression](https://qodo-merge-docs.qodo.ai/core-abilities/compression_strategy/) | ✅ | ✅ | ✅ | ✅ | |
|
| | [PR compression](https://qodo-merge-docs.qodo.ai/core-abilities/compression_strategy/) | ✅ | ✅ | ✅ | ✅ | |
|
||||||
| | [PR interactive actions](https://www.qodo.ai/images/pr_agent/pr-actions.mp4) 💎 | ✅ | ✅ | | | |
|
| | [PR interactive actions](https://www.qodo.ai/images/pr_agent/pr-actions.mp4) 💎 | ✅ | ✅ | | | |
|
||||||
| | [RAG context enrichment](https://qodo-merge-docs.qodo.ai/core-abilities/rag_context_enrichment/) | ✅ | | ✅ | | |
|
| | [RAG context enrichment](https://qodo-merge-docs.qodo.ai/core-abilities/rag_context_enrichment/) | ✅ | | ✅ | | |
|
||||||
| | [Self reflection](https://qodo-merge-docs.qodo.ai/core-abilities/self_reflection/) | ✅ | ✅ | ✅ | ✅ | |
|
| | [Self reflection](https://qodo-merge-docs.qodo.ai/core-abilities/self_reflection/) | ✅ | ✅ | ✅ | ✅ | |
|
||||||
| | [Static code analysis](https://qodo-merge-docs.qodo.ai/core-abilities/static_code_analysis/) 💎 | ✅ | ✅ | | | |
|
| | [Static code analysis](https://qodo-merge-docs.qodo.ai/core-abilities/static_code_analysis/) 💎 | ✅ | ✅ | | | |
|
||||||
!!! note "💎 means Qodo Merge only"
|
!!! note "💎 means Qodo Merge only"
|
||||||
All along the documentation, 💎 marks a feature available only in [Qodo Merge](https://www.codium.ai/pricing/){:target="_blank"}, and not in the open-source version.
|
All along the documentation, 💎 marks a feature available only in [Qodo Merge](https://www.codium.ai/pricing/){:target="_blank"}, and not in the open-source version.
|
||||||
|
|
|
||||||
|
|
@ -1,19 +1,23 @@
|
||||||
## Azure DevOps Pipeline
|
## Azure DevOps Pipeline
|
||||||
|
|
||||||
You can use a pre-built Action Docker image to run PR-Agent as an Azure devops pipeline.
|
You can use a pre-built Action Docker image to run PR-Agent as an Azure DevOps pipeline.
|
||||||
add the following file to your repository under `azure-pipelines.yml`:
|
Add the following file to your repository under `azure-pipelines.yml`:
|
||||||
|
|
||||||
```yaml
|
```yaml
|
||||||
# Opt out of CI triggers
|
# Opt out of CI triggers
|
||||||
trigger: none
|
trigger: none
|
||||||
|
|
||||||
# Configure PR trigger
|
# Configure PR trigger
|
||||||
pr:
|
# pr:
|
||||||
branches:
|
# branches:
|
||||||
include:
|
# include:
|
||||||
- '*'
|
# - '*'
|
||||||
autoCancel: true
|
# autoCancel: true
|
||||||
drafts: false
|
# drafts: false
|
||||||
|
|
||||||
|
# NOTE for Azure Repos Git:
|
||||||
|
# Azure Repos does not honor YAML pr: triggers. Configure Build Validation
|
||||||
|
# via Branch Policies instead (see note below). You can safely omit pr:.
|
||||||
|
|
||||||
stages:
|
stages:
|
||||||
- stage: pr_agent
|
- stage: pr_agent
|
||||||
|
|
@ -61,6 +65,19 @@ Make sure to give pipeline permissions to the `pr_agent` variable group.
|
||||||
|
|
||||||
> Note that Azure Pipelines lacks support for triggering workflows from PR comments. If you find a viable solution, please contribute it to our [issue tracker](https://github.com/Codium-ai/pr-agent/issues)
|
> Note that Azure Pipelines lacks support for triggering workflows from PR comments. If you find a viable solution, please contribute it to our [issue tracker](https://github.com/Codium-ai/pr-agent/issues)
|
||||||
|
|
||||||
|
### Azure Repos Git PR triggers and Build Validation
|
||||||
|
|
||||||
|
Azure Repos Git does not use YAML `pr:` triggers for pipelines. Instead, configure Build Validation on the target branch to run the PR Agent pipeline for pull requests:
|
||||||
|
|
||||||
|
1. Go to Project Settings → Repositories → Branches.
|
||||||
|
2. Select the target branch and open Branch Policies.
|
||||||
|
3. Under Build Validation, add a policy:
|
||||||
|
- Select the PR Agent pipeline (the `azure-pipelines.yml` above).
|
||||||
|
- Set it as Required.
|
||||||
|
4. Remove the `pr:` section from your YAML (not needed for Azure Repos Git).
|
||||||
|
|
||||||
|
This distinction applies specifically to Azure Repos Git. Other providers like GitHub and Bitbucket Cloud can use YAML-based PR triggers.
|
||||||
|
|
||||||
## Azure DevOps from CLI
|
## Azure DevOps from CLI
|
||||||
|
|
||||||
To use Azure DevOps provider use the following settings in configuration.toml:
|
To use Azure DevOps provider use the following settings in configuration.toml:
|
||||||
|
|
@ -71,7 +88,7 @@ git_provider="azure"
|
||||||
```
|
```
|
||||||
|
|
||||||
Azure DevOps provider supports [PAT token](https://learn.microsoft.com/en-us/azure/devops/organizations/accounts/use-personal-access-tokens-to-authenticate?view=azure-devops&tabs=Windows) or [DefaultAzureCredential](https://learn.microsoft.com/en-us/azure/developer/python/sdk/authentication-overview#authentication-in-server-environments) authentication.
|
Azure DevOps provider supports [PAT token](https://learn.microsoft.com/en-us/azure/devops/organizations/accounts/use-personal-access-tokens-to-authenticate?view=azure-devops&tabs=Windows) or [DefaultAzureCredential](https://learn.microsoft.com/en-us/azure/developer/python/sdk/authentication-overview#authentication-in-server-environments) authentication.
|
||||||
PAT is faster to create, but has build in expiration date, and will use the user identity for API calls.
|
PAT is faster to create, but has built-in expiration date, and will use the user identity for API calls.
|
||||||
Using DefaultAzureCredential you can use managed identity or Service principle, which are more secure and will create separate ADO user identity (via AAD) to the agent.
|
Using DefaultAzureCredential you can use managed identity or Service principle, which are more secure and will create separate ADO user identity (via AAD) to the agent.
|
||||||
|
|
||||||
If PAT was chosen, you can assign the value in .secrets.toml.
|
If PAT was chosen, you can assign the value in .secrets.toml.
|
||||||
|
|
|
||||||
|
|
@ -39,6 +39,13 @@ Generate the token and add it to .secret.toml under `bitbucket_server` section
|
||||||
bearer_token = "<your key>"
|
bearer_token = "<your key>"
|
||||||
```
|
```
|
||||||
|
|
||||||
|
Don't forget to also set the URL of your Bitbucket Server instance (either in `.secret.toml` or in `configuration.toml`):
|
||||||
|
|
||||||
|
```toml
|
||||||
|
[bitbucket_server]
|
||||||
|
url = "<full URL to your Bitbucket instance, e.g.: https://git.bitbucket.com>"
|
||||||
|
```
|
||||||
|
|
||||||
### Run it as CLI
|
### Run it as CLI
|
||||||
|
|
||||||
Modify `configuration.toml`:
|
Modify `configuration.toml`:
|
||||||
|
|
@ -47,10 +54,12 @@ Modify `configuration.toml`:
|
||||||
git_provider="bitbucket_server"
|
git_provider="bitbucket_server"
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
and pass the Pull request URL:
|
and pass the Pull request URL:
|
||||||
|
|
||||||
```shell
|
```shell
|
||||||
python cli.py --pr_url https://git.onpreminstanceofbitbucket.com/projects/PROJECT/repos/REPO/pull-requests/1 review
|
python cli.py --pr_url https://git.on-prem-instance-of-bitbucket.com/projects/PROJECT/repos/REPO/pull-requests/1 review
|
||||||
```
|
```
|
||||||
|
|
||||||
### Run it as service
|
### Run it as service
|
||||||
|
|
@ -63,6 +72,6 @@ docker push codiumai/pr-agent:bitbucket_server_webhook # Push to your Docker re
|
||||||
```
|
```
|
||||||
|
|
||||||
Navigate to `Projects` or `Repositories`, `Settings`, `Webhooks`, `Create Webhook`.
|
Navigate to `Projects` or `Repositories`, `Settings`, `Webhooks`, `Create Webhook`.
|
||||||
Fill the name and URL, Authentication None select the Pull Request Opened checkbox to receive that event as webhook.
|
Fill in the name and URL. For Authentication, select 'None'. Select the 'Pull Request Opened' checkbox to receive that event as a webhook.
|
||||||
|
|
||||||
The URL should end with `/webhook`, for example: https://domain.com/webhook
|
The URL should end with `/webhook`, for example: https://domain.com/webhook
|
||||||
|
|
|
||||||
|
|
@ -17,12 +17,11 @@ git clone https://github.com/qodo-ai/pr-agent.git
|
||||||
```
|
```
|
||||||
|
|
||||||
5. Prepare variables and secrets. Skip this step if you plan on setting these as environment variables when running the agent:
|
5. Prepare variables and secrets. Skip this step if you plan on setting these as environment variables when running the agent:
|
||||||
1. In the configuration file/variables:
|
- In the configuration file/variables:
|
||||||
- Set `config.git_provider` to "gitea"
|
- Set `config.git_provider` to "gitea"
|
||||||
|
- In the secrets file/variables:
|
||||||
2. In the secrets file/variables:
|
- Set your AI model key in the respective section
|
||||||
- Set your AI model key in the respective section
|
- In the [Gitea] section, set `personal_access_token` (with token from step 2) and `webhook_secret` (with secret from step 3)
|
||||||
- In the [Gitea] section, set `personal_access_token` (with token from step 2) and `webhook_secret` (with secret from step 3)
|
|
||||||
|
|
||||||
6. Build a Docker image for the app and optionally push it to a Docker repository. We'll use Dockerhub as an example:
|
6. Build a Docker image for the app and optionally push it to a Docker repository. We'll use Dockerhub as an example:
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -1,3 +1,5 @@
|
||||||
|
In this page we will cover how to install and run PR-Agent as a GitHub Action or GitHub App, and how to configure it for your needs.
|
||||||
|
|
||||||
## Run as a GitHub Action
|
## Run as a GitHub Action
|
||||||
|
|
||||||
You can use our pre-built Github Action Docker image to run PR-Agent as a Github Action.
|
You can use our pre-built Github Action Docker image to run PR-Agent as a Github Action.
|
||||||
|
|
@ -51,6 +53,437 @@ When you open your next PR, you should see a comment from `github-actions` bot w
|
||||||
|
|
||||||
See detailed usage instructions in the [USAGE GUIDE](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#github-action)
|
See detailed usage instructions in the [USAGE GUIDE](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#github-action)
|
||||||
|
|
||||||
|
### Configuration Examples
|
||||||
|
|
||||||
|
This section provides detailed, step-by-step examples for configuring PR-Agent with different models and advanced options in GitHub Actions.
|
||||||
|
|
||||||
|
#### Quick Start Examples
|
||||||
|
|
||||||
|
##### Basic Setup (OpenAI Default)
|
||||||
|
|
||||||
|
Copy this minimal workflow to get started with the default OpenAI models:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
name: PR Agent
|
||||||
|
on:
|
||||||
|
pull_request:
|
||||||
|
types: [opened, reopened, ready_for_review]
|
||||||
|
issue_comment:
|
||||||
|
jobs:
|
||||||
|
pr_agent_job:
|
||||||
|
if: ${{ github.event.sender.type != 'Bot' }}
|
||||||
|
runs-on: ubuntu-latest
|
||||||
|
permissions:
|
||||||
|
issues: write
|
||||||
|
pull-requests: write
|
||||||
|
contents: write
|
||||||
|
steps:
|
||||||
|
- name: PR Agent action step
|
||||||
|
uses: qodo-ai/pr-agent@main
|
||||||
|
env:
|
||||||
|
OPENAI_KEY: ${{ secrets.OPENAI_KEY }}
|
||||||
|
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||||
|
```
|
||||||
|
|
||||||
|
##### Gemini Setup
|
||||||
|
|
||||||
|
Ready-to-use workflow for Gemini models:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
name: PR Agent (Gemini)
|
||||||
|
on:
|
||||||
|
pull_request:
|
||||||
|
types: [opened, reopened, ready_for_review]
|
||||||
|
issue_comment:
|
||||||
|
jobs:
|
||||||
|
pr_agent_job:
|
||||||
|
if: ${{ github.event.sender.type != 'Bot' }}
|
||||||
|
runs-on: ubuntu-latest
|
||||||
|
permissions:
|
||||||
|
issues: write
|
||||||
|
pull-requests: write
|
||||||
|
contents: write
|
||||||
|
steps:
|
||||||
|
- name: PR Agent action step
|
||||||
|
uses: qodo-ai/pr-agent@main
|
||||||
|
env:
|
||||||
|
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||||
|
config.model: "gemini/gemini-1.5-flash"
|
||||||
|
config.fallback_models: '["gemini/gemini-1.5-flash"]'
|
||||||
|
GOOGLE_AI_STUDIO.GEMINI_API_KEY: ${{ secrets.GEMINI_API_KEY }}
|
||||||
|
github_action_config.auto_review: "true"
|
||||||
|
github_action_config.auto_describe: "true"
|
||||||
|
github_action_config.auto_improve: "true"
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Claude Setup
|
||||||
|
|
||||||
|
Ready-to-use workflow for Claude models:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
name: PR Agent (Claude)
|
||||||
|
on:
|
||||||
|
pull_request:
|
||||||
|
types: [opened, reopened, ready_for_review]
|
||||||
|
issue_comment:
|
||||||
|
jobs:
|
||||||
|
pr_agent_job:
|
||||||
|
if: ${{ github.event.sender.type != 'Bot' }}
|
||||||
|
runs-on: ubuntu-latest
|
||||||
|
permissions:
|
||||||
|
issues: write
|
||||||
|
pull-requests: write
|
||||||
|
contents: write
|
||||||
|
steps:
|
||||||
|
- name: PR Agent action step
|
||||||
|
uses: qodo-ai/pr-agent@main
|
||||||
|
env:
|
||||||
|
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||||
|
config.model: "anthropic/claude-3-opus-20240229"
|
||||||
|
config.fallback_models: '["anthropic/claude-3-haiku-20240307"]'
|
||||||
|
ANTHROPIC.KEY: ${{ secrets.ANTHROPIC_KEY }}
|
||||||
|
github_action_config.auto_review: "true"
|
||||||
|
github_action_config.auto_describe: "true"
|
||||||
|
github_action_config.auto_improve: "true"
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Basic Configuration with Tool Controls
|
||||||
|
|
||||||
|
Start with this enhanced workflow that includes tool configuration:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
on:
|
||||||
|
pull_request:
|
||||||
|
types: [opened, reopened, ready_for_review]
|
||||||
|
issue_comment:
|
||||||
|
jobs:
|
||||||
|
pr_agent_job:
|
||||||
|
if: ${{ github.event.sender.type != 'Bot' }}
|
||||||
|
runs-on: ubuntu-latest
|
||||||
|
permissions:
|
||||||
|
issues: write
|
||||||
|
pull-requests: write
|
||||||
|
contents: write
|
||||||
|
name: Run pr agent on every pull request, respond to user comments
|
||||||
|
steps:
|
||||||
|
- name: PR Agent action step
|
||||||
|
id: pragent
|
||||||
|
uses: qodo-ai/pr-agent@main
|
||||||
|
env:
|
||||||
|
OPENAI_KEY: ${{ secrets.OPENAI_KEY }}
|
||||||
|
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||||
|
# Enable/disable automatic tools
|
||||||
|
github_action_config.auto_review: "true"
|
||||||
|
github_action_config.auto_describe: "true"
|
||||||
|
github_action_config.auto_improve: "true"
|
||||||
|
# Configure which PR events trigger the action
|
||||||
|
github_action_config.pr_actions: '["opened", "reopened", "ready_for_review", "review_requested"]'
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Switching Models
|
||||||
|
|
||||||
|
##### Using Gemini (Google AI Studio)
|
||||||
|
|
||||||
|
To use Gemini models instead of the default OpenAI models:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
env:
|
||||||
|
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||||
|
# Set the model to Gemini
|
||||||
|
config.model: "gemini/gemini-1.5-flash"
|
||||||
|
config.fallback_models: '["gemini/gemini-1.5-flash"]'
|
||||||
|
# Add your Gemini API key
|
||||||
|
GOOGLE_AI_STUDIO.GEMINI_API_KEY: ${{ secrets.GEMINI_API_KEY }}
|
||||||
|
# Tool configuration
|
||||||
|
github_action_config.auto_review: "true"
|
||||||
|
github_action_config.auto_describe: "true"
|
||||||
|
github_action_config.auto_improve: "true"
|
||||||
|
```
|
||||||
|
|
||||||
|
**Required Secrets:**
|
||||||
|
|
||||||
|
- Add `GEMINI_API_KEY` to your repository secrets (get it from [Google AI Studio](https://aistudio.google.com/))
|
||||||
|
|
||||||
|
**Note:** When using non-OpenAI models like Gemini, you don't need to set `OPENAI_KEY` - only the model-specific API key is required.
|
||||||
|
|
||||||
|
##### Using Claude (Anthropic)
|
||||||
|
|
||||||
|
To use Claude models:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
env:
|
||||||
|
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||||
|
# Set the model to Claude
|
||||||
|
config.model: "anthropic/claude-3-opus-20240229"
|
||||||
|
config.fallback_models: '["anthropic/claude-3-haiku-20240307"]'
|
||||||
|
# Add your Anthropic API key
|
||||||
|
ANTHROPIC.KEY: ${{ secrets.ANTHROPIC_KEY }}
|
||||||
|
# Tool configuration
|
||||||
|
github_action_config.auto_review: "true"
|
||||||
|
github_action_config.auto_describe: "true"
|
||||||
|
github_action_config.auto_improve: "true"
|
||||||
|
```
|
||||||
|
|
||||||
|
**Required Secrets:**
|
||||||
|
|
||||||
|
- Add `ANTHROPIC_KEY` to your repository secrets (get it from [Anthropic Console](https://console.anthropic.com/))
|
||||||
|
|
||||||
|
**Note:** When using non-OpenAI models like Claude, you don't need to set `OPENAI_KEY` - only the model-specific API key is required.
|
||||||
|
|
||||||
|
##### Using Azure OpenAI
|
||||||
|
|
||||||
|
To use Azure OpenAI services:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
env:
|
||||||
|
OPENAI_KEY: ${{ secrets.AZURE_OPENAI_KEY }}
|
||||||
|
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||||
|
# Azure OpenAI configuration
|
||||||
|
OPENAI.API_TYPE: "azure"
|
||||||
|
OPENAI.API_VERSION: "2023-05-15"
|
||||||
|
OPENAI.API_BASE: ${{ secrets.AZURE_OPENAI_ENDPOINT }}
|
||||||
|
OPENAI.DEPLOYMENT_ID: ${{ secrets.AZURE_OPENAI_DEPLOYMENT }}
|
||||||
|
# Set the model to match your Azure deployment
|
||||||
|
config.model: "gpt-4o"
|
||||||
|
config.fallback_models: '["gpt-4o"]'
|
||||||
|
# Tool configuration
|
||||||
|
github_action_config.auto_review: "true"
|
||||||
|
github_action_config.auto_describe: "true"
|
||||||
|
github_action_config.auto_improve: "true"
|
||||||
|
```
|
||||||
|
|
||||||
|
**Required Secrets:**
|
||||||
|
|
||||||
|
- `AZURE_OPENAI_KEY`: Your Azure OpenAI API key
|
||||||
|
- `AZURE_OPENAI_ENDPOINT`: Your Azure OpenAI endpoint URL
|
||||||
|
- `AZURE_OPENAI_DEPLOYMENT`: Your deployment name
|
||||||
|
|
||||||
|
##### Using Local Models (Ollama)
|
||||||
|
|
||||||
|
To use local models via Ollama:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
env:
|
||||||
|
OPENAI_KEY: ${{ secrets.OPENAI_KEY }}
|
||||||
|
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||||
|
# Set the model to a local Ollama model
|
||||||
|
config.model: "ollama/qwen2.5-coder:32b"
|
||||||
|
config.fallback_models: '["ollama/qwen2.5-coder:32b"]'
|
||||||
|
config.custom_model_max_tokens: "128000"
|
||||||
|
# Ollama configuration
|
||||||
|
OLLAMA.API_BASE: "http://localhost:11434"
|
||||||
|
# Tool configuration
|
||||||
|
github_action_config.auto_review: "true"
|
||||||
|
github_action_config.auto_describe: "true"
|
||||||
|
github_action_config.auto_improve: "true"
|
||||||
|
```
|
||||||
|
|
||||||
|
**Note:** For local models, you'll need to use a self-hosted runner with Ollama installed, as GitHub Actions hosted runners cannot access localhost services.
|
||||||
|
|
||||||
|
#### Advanced Configuration Options
|
||||||
|
|
||||||
|
##### Custom Review Instructions
|
||||||
|
|
||||||
|
Add specific instructions for the review process:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
env:
|
||||||
|
OPENAI_KEY: ${{ secrets.OPENAI_KEY }}
|
||||||
|
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||||
|
# Custom review instructions
|
||||||
|
pr_reviewer.extra_instructions: "Focus on security vulnerabilities and performance issues. Check for proper error handling."
|
||||||
|
# Tool configuration
|
||||||
|
github_action_config.auto_review: "true"
|
||||||
|
github_action_config.auto_describe: "true"
|
||||||
|
github_action_config.auto_improve: "true"
|
||||||
|
```
|
||||||
|
|
||||||
|
##### Language-Specific Configuration
|
||||||
|
|
||||||
|
Configure for specific programming languages:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
env:
|
||||||
|
OPENAI_KEY: ${{ secrets.OPENAI_KEY }}
|
||||||
|
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||||
|
# Language-specific settings
|
||||||
|
pr_reviewer.extra_instructions: "Focus on Python best practices, type hints, and docstrings."
|
||||||
|
pr_code_suggestions.num_code_suggestions: "8"
|
||||||
|
pr_code_suggestions.suggestions_score_threshold: "7"
|
||||||
|
# Tool configuration
|
||||||
|
github_action_config.auto_review: "true"
|
||||||
|
github_action_config.auto_describe: "true"
|
||||||
|
github_action_config.auto_improve: "true"
|
||||||
|
```
|
||||||
|
|
||||||
|
##### Selective Tool Execution
|
||||||
|
|
||||||
|
Run only specific tools automatically:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
env:
|
||||||
|
OPENAI_KEY: ${{ secrets.OPENAI_KEY }}
|
||||||
|
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||||
|
# Only run review and describe, skip improve
|
||||||
|
github_action_config.auto_review: "true"
|
||||||
|
github_action_config.auto_describe: "true"
|
||||||
|
github_action_config.auto_improve: "false"
|
||||||
|
# Only trigger on PR open and reopen
|
||||||
|
github_action_config.pr_actions: '["opened", "reopened"]'
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Using Configuration Files
|
||||||
|
|
||||||
|
Instead of setting all options via environment variables, you can use a `.pr_agent.toml` file in your repository root:
|
||||||
|
|
||||||
|
1. Create a `.pr_agent.toml` file in your repository root:
|
||||||
|
|
||||||
|
```toml
|
||||||
|
[config]
|
||||||
|
model = "gemini/gemini-1.5-flash"
|
||||||
|
fallback_models = ["anthropic/claude-3-opus-20240229"]
|
||||||
|
|
||||||
|
[pr_reviewer]
|
||||||
|
extra_instructions = "Focus on security issues and code quality."
|
||||||
|
|
||||||
|
[pr_code_suggestions]
|
||||||
|
num_code_suggestions = 6
|
||||||
|
suggestions_score_threshold = 7
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Use a simpler workflow file:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
on:
|
||||||
|
pull_request:
|
||||||
|
types: [opened, reopened, ready_for_review]
|
||||||
|
issue_comment:
|
||||||
|
jobs:
|
||||||
|
pr_agent_job:
|
||||||
|
if: ${{ github.event.sender.type != 'Bot' }}
|
||||||
|
runs-on: ubuntu-latest
|
||||||
|
permissions:
|
||||||
|
issues: write
|
||||||
|
pull-requests: write
|
||||||
|
contents: write
|
||||||
|
name: Run pr agent on every pull request, respond to user comments
|
||||||
|
steps:
|
||||||
|
- name: PR Agent action step
|
||||||
|
id: pragent
|
||||||
|
uses: qodo-ai/pr-agent@main
|
||||||
|
env:
|
||||||
|
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||||
|
GOOGLE_AI_STUDIO.GEMINI_API_KEY: ${{ secrets.GEMINI_API_KEY }}
|
||||||
|
ANTHROPIC.KEY: ${{ secrets.ANTHROPIC_KEY }}
|
||||||
|
github_action_config.auto_review: "true"
|
||||||
|
github_action_config.auto_describe: "true"
|
||||||
|
github_action_config.auto_improve: "true"
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Troubleshooting Common Issues
|
||||||
|
|
||||||
|
##### Model Not Found Errors
|
||||||
|
|
||||||
|
If you get model not found errors:
|
||||||
|
|
||||||
|
1. **Check model name format**: Ensure you're using the correct model identifier format (e.g., `gemini/gemini-1.5-flash`, not just `gemini-1.5-flash`)
|
||||||
|
|
||||||
|
2. **Verify API keys**: Make sure your API keys are correctly set as repository secrets
|
||||||
|
|
||||||
|
3. **Check model availability**: Some models may not be available in all regions or may require specific access
|
||||||
|
|
||||||
|
##### Environment Variable Format
|
||||||
|
|
||||||
|
Remember these key points about environment variables:
|
||||||
|
|
||||||
|
- Use dots (`.`) or double underscores (`__`) to separate sections and keys
|
||||||
|
- Boolean values should be strings: `"true"` or `"false"`
|
||||||
|
- Arrays should be JSON strings: `'["item1", "item2"]'`
|
||||||
|
- Model names are case-sensitive
|
||||||
|
|
||||||
|
##### Rate Limiting
|
||||||
|
|
||||||
|
If you encounter rate limiting:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
env:
|
||||||
|
OPENAI_KEY: ${{ secrets.OPENAI_KEY }}
|
||||||
|
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||||
|
# Add fallback models for better reliability
|
||||||
|
config.fallback_models: '["gpt-4o", "gpt-3.5-turbo"]'
|
||||||
|
# Increase timeout for slower models
|
||||||
|
config.ai_timeout: "300"
|
||||||
|
github_action_config.auto_review: "true"
|
||||||
|
github_action_config.auto_describe: "true"
|
||||||
|
github_action_config.auto_improve: "true"
|
||||||
|
```
|
||||||
|
|
||||||
|
##### Common Error Messages and Solutions
|
||||||
|
|
||||||
|
**Error: "Model not found"**
|
||||||
|
- **Solution**: Check the model name format and ensure it matches the exact identifier. See the [Changing a model in PR-Agent](../usage-guide/changing_a_model.md) guide for supported models and their correct identifiers.
|
||||||
|
|
||||||
|
**Error: "API key not found"**
|
||||||
|
- **Solution**: Verify that your API key is correctly set as a repository secret and the environment variable name matches exactly
|
||||||
|
- **Note**: For non-OpenAI models (Gemini, Claude, etc.), you only need the model-specific API key, not `OPENAI_KEY`
|
||||||
|
|
||||||
|
**Error: "Rate limit exceeded"**
|
||||||
|
- **Solution**: Add fallback models or increase the `config.ai_timeout` value
|
||||||
|
|
||||||
|
**Error: "Permission denied"**
|
||||||
|
- **Solution**: Ensure your workflow has the correct permissions set:
|
||||||
|
```yaml
|
||||||
|
permissions:
|
||||||
|
issues: write
|
||||||
|
pull-requests: write
|
||||||
|
contents: write
|
||||||
|
```
|
||||||
|
|
||||||
|
**Error: "Invalid JSON format"**
|
||||||
|
|
||||||
|
- **Solution**: Check that arrays are properly formatted as JSON strings:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
|
||||||
|
Correct:
|
||||||
|
config.fallback_models: '["model1", "model2"]'
|
||||||
|
Incorrect (interpreted as a YAML list, not a string):
|
||||||
|
config.fallback_models: ["model1", "model2"]
|
||||||
|
```
|
||||||
|
|
||||||
|
##### Debugging Tips
|
||||||
|
|
||||||
|
1. **Enable verbose logging**: Add `config.verbosity_level: "2"` to see detailed logs
|
||||||
|
2. **Check GitHub Actions logs**: Look at the step output for specific error messages
|
||||||
|
3. **Test with minimal configuration**: Start with just the basic setup and add options one by one
|
||||||
|
4. **Verify secrets**: Double-check that all required secrets are set in your repository settings
|
||||||
|
|
||||||
|
##### Performance Optimization
|
||||||
|
|
||||||
|
For better performance with large repositories:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
env:
|
||||||
|
OPENAI_KEY: ${{ secrets.OPENAI_KEY }}
|
||||||
|
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||||
|
# Optimize for large PRs
|
||||||
|
config.large_patch_policy: "clip"
|
||||||
|
config.max_model_tokens: "32000"
|
||||||
|
config.patch_extra_lines_before: "3"
|
||||||
|
config.patch_extra_lines_after: "1"
|
||||||
|
github_action_config.auto_review: "true"
|
||||||
|
github_action_config.auto_describe: "true"
|
||||||
|
github_action_config.auto_improve: "true"
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Reference
|
||||||
|
|
||||||
|
For more detailed configuration options, see:
|
||||||
|
|
||||||
|
- [Changing a model in PR-Agent](../usage-guide/changing_a_model.md)
|
||||||
|
- [Configuration options](../usage-guide/configuration_options.md)
|
||||||
|
- [Automations and usage](../usage-guide/automations_and_usage.md#github-action)
|
||||||
|
|
||||||
### Using a specific release
|
### Using a specific release
|
||||||
|
|
||||||
!!! tip ""
|
!!! tip ""
|
||||||
|
|
@ -178,7 +611,9 @@ cp pr_agent/settings/.secrets_template.toml pr_agent/settings/.secrets.toml
|
||||||
> For more information please check out the [USAGE GUIDE](../usage-guide/automations_and_usage.md#github-app)
|
> For more information please check out the [USAGE GUIDE](../usage-guide/automations_and_usage.md#github-app)
|
||||||
---
|
---
|
||||||
|
|
||||||
## Deploy as a Lambda Function
|
## Additional deployment methods
|
||||||
|
|
||||||
|
### Deploy as a Lambda Function
|
||||||
|
|
||||||
Note that since AWS Lambda env vars cannot have "." in the name, you can replace each "." in an env variable with "__".<br>
|
Note that since AWS Lambda env vars cannot have "." in the name, you can replace each "." in an env variable with "__".<br>
|
||||||
For example: `GITHUB.WEBHOOK_SECRET` --> `GITHUB__WEBHOOK_SECRET`
|
For example: `GITHUB.WEBHOOK_SECRET` --> `GITHUB__WEBHOOK_SECRET`
|
||||||
|
|
@ -187,9 +622,10 @@ For example: `GITHUB.WEBHOOK_SECRET` --> `GITHUB__WEBHOOK_SECRET`
|
||||||
2. Build a docker image that can be used as a lambda function
|
2. Build a docker image that can be used as a lambda function
|
||||||
|
|
||||||
```shell
|
```shell
|
||||||
# Note: --target github_lambda is optional as it's the default target
|
|
||||||
docker buildx build --platform=linux/amd64 . -t codiumai/pr-agent:github_lambda --target github_lambda -f docker/Dockerfile.lambda
|
docker buildx build --platform=linux/amd64 . -t codiumai/pr-agent:github_lambda --target github_lambda -f docker/Dockerfile.lambda
|
||||||
```
|
```
|
||||||
|
(Note: --target github_lambda is optional as it's the default target)
|
||||||
|
|
||||||
|
|
||||||
3. Push image to ECR
|
3. Push image to ECR
|
||||||
|
|
||||||
|
|
@ -204,7 +640,7 @@ For example: `GITHUB.WEBHOOK_SECRET` --> `GITHUB__WEBHOOK_SECRET`
|
||||||
7. Go back to steps 8-9 of [Method 5](#run-as-a-github-app) with the function url as your Webhook URL.
|
7. Go back to steps 8-9 of [Method 5](#run-as-a-github-app) with the function url as your Webhook URL.
|
||||||
The Webhook URL would look like `https://<LAMBDA_FUNCTION_URL>/api/v1/github_webhooks`
|
The Webhook URL would look like `https://<LAMBDA_FUNCTION_URL>/api/v1/github_webhooks`
|
||||||
|
|
||||||
### Using AWS Secrets Manager
|
#### Using AWS Secrets Manager
|
||||||
|
|
||||||
For production Lambda deployments, use AWS Secrets Manager instead of environment variables:
|
For production Lambda deployments, use AWS Secrets Manager instead of environment variables:
|
||||||
|
|
||||||
|
|
@ -228,7 +664,7 @@ CONFIG__SECRET_PROVIDER=aws_secrets_manager
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
## AWS CodeCommit Setup
|
### AWS CodeCommit Setup
|
||||||
|
|
||||||
Not all features have been added to CodeCommit yet. As of right now, CodeCommit has been implemented to run the Qodo Merge CLI on the command line, using AWS credentials stored in environment variables. (More features will be added in the future.) The following is a set of instructions to have Qodo Merge do a review of your CodeCommit pull request from the command line:
|
Not all features have been added to CodeCommit yet. As of right now, CodeCommit has been implemented to run the Qodo Merge CLI on the command line, using AWS credentials stored in environment variables. (More features will be added in the future.) The following is a set of instructions to have Qodo Merge do a review of your CodeCommit pull request from the command line:
|
||||||
|
|
||||||
|
|
@ -245,7 +681,7 @@ Not all features have been added to CodeCommit yet. As of right now, CodeCommit
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
#### AWS CodeCommit IAM Role Example
|
##### AWS CodeCommit IAM Role Example
|
||||||
|
|
||||||
Example IAM permissions to that user to allow access to CodeCommit:
|
Example IAM permissions to that user to allow access to CodeCommit:
|
||||||
|
|
||||||
|
|
@ -277,7 +713,7 @@ Example IAM permissions to that user to allow access to CodeCommit:
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
#### AWS CodeCommit Access Key and Secret
|
##### AWS CodeCommit Access Key and Secret
|
||||||
|
|
||||||
Example setting the Access Key and Secret using environment variables
|
Example setting the Access Key and Secret using environment variables
|
||||||
|
|
||||||
|
|
@ -287,7 +723,7 @@ export AWS_SECRET_ACCESS_KEY="XXXXXXXXXXXXXXXX"
|
||||||
export AWS_DEFAULT_REGION="us-east-1"
|
export AWS_DEFAULT_REGION="us-east-1"
|
||||||
```
|
```
|
||||||
|
|
||||||
#### AWS CodeCommit CLI Example
|
##### AWS CodeCommit CLI Example
|
||||||
|
|
||||||
After you set up AWS CodeCommit using the instructions above, here is an example CLI run that tells pr-agent to **review** a given pull request.
|
After you set up AWS CodeCommit using the instructions above, here is an example CLI run that tells pr-agent to **review** a given pull request.
|
||||||
(Replace your specific PYTHONPATH and PR URL in the example)
|
(Replace your specific PYTHONPATH and PR URL in the example)
|
||||||
|
|
@ -296,4 +732,4 @@ After you set up AWS CodeCommit using the instructions above, here is an example
|
||||||
PYTHONPATH="/PATH/TO/PROJECTS/pr-agent" python pr_agent/cli.py \
|
PYTHONPATH="/PATH/TO/PROJECTS/pr-agent" python pr_agent/cli.py \
|
||||||
--pr_url https://us-east-1.console.aws.amazon.com/codesuite/codecommit/repositories/MY_REPO_NAME/pull-requests/321 \
|
--pr_url https://us-east-1.console.aws.amazon.com/codesuite/codecommit/repositories/MY_REPO_NAME/pull-requests/321 \
|
||||||
review
|
review
|
||||||
```
|
```
|
||||||
|
|
@ -42,11 +42,14 @@ Note that if your base branches are not protected, don't set the variables as `p
|
||||||
|
|
||||||
> **Note**: The `$CI_SERVER_FQDN` variable is available starting from GitLab version 16.10. If you're using an earlier version, this variable will not be available. However, you can combine `$CI_SERVER_HOST` and `$CI_SERVER_PORT` to achieve the same result. Please ensure you're using a compatible version or adjust your configuration.
|
> **Note**: The `$CI_SERVER_FQDN` variable is available starting from GitLab version 16.10. If you're using an earlier version, this variable will not be available. However, you can combine `$CI_SERVER_HOST` and `$CI_SERVER_PORT` to achieve the same result. Please ensure you're using a compatible version or adjust your configuration.
|
||||||
|
|
||||||
|
> **Note**: The `gitlab__SSL_VERIFY` environment variable can be used to specify the path to a custom CA certificate bundle for SSL verification. GitLab exposes the `$CI_SERVER_TLS_CA_FILE` variable, which points to the custom CA certificate file configured in your GitLab instance.
|
||||||
|
> Alternatively, SSL verification can be disabled entirely by setting `gitlab__SSL_VERIFY=false`, although this is not recommended.
|
||||||
|
|
||||||
## Run a GitLab webhook server
|
## Run a GitLab webhook server
|
||||||
|
|
||||||
1. In GitLab create a new user and give it "Reporter" role ("Developer" if using Pro version of the agent) for the intended group or project.
|
1. In GitLab create a new user and give it "Reporter" role ("Developer" if using Pro version of the agent) for the intended group or project.
|
||||||
|
|
||||||
2. For the user from step 1. generate a `personal_access_token` with `api` access.
|
2. For the user from step 1, generate a `personal_access_token` with `api` access.
|
||||||
|
|
||||||
3. Generate a random secret for your app, and save it for later (`shared_secret`). For example, you can use:
|
3. Generate a random secret for your app, and save it for later (`shared_secret`). For example, you can use:
|
||||||
|
|
||||||
|
|
@ -67,6 +70,7 @@ git clone https://github.com/qodo-ai/pr-agent.git
|
||||||
2. In the secrets file/variables:
|
2. In the secrets file/variables:
|
||||||
- Set your AI model key in the respective section
|
- Set your AI model key in the respective section
|
||||||
- In the [gitlab] section, set `personal_access_token` (with token from step 2) and `shared_secret` (with secret from step 3)
|
- In the [gitlab] section, set `personal_access_token` (with token from step 2) and `shared_secret` (with secret from step 3)
|
||||||
|
- **Authentication type**: Set `auth_type` to `"private_token"` for older GitLab versions (e.g., 11.x) or private deployments. Default is `"oauth_token"` for gitlab.com and newer versions.
|
||||||
|
|
||||||
6. Build a Docker image for the app and optionally push it to a Docker repository. We'll use Dockerhub as an example:
|
6. Build a Docker image for the app and optionally push it to a Docker repository. We'll use Dockerhub as an example:
|
||||||
|
|
||||||
|
|
@ -82,6 +86,7 @@ CONFIG__GIT_PROVIDER=gitlab
|
||||||
GITLAB__PERSONAL_ACCESS_TOKEN=<personal_access_token>
|
GITLAB__PERSONAL_ACCESS_TOKEN=<personal_access_token>
|
||||||
GITLAB__SHARED_SECRET=<shared_secret>
|
GITLAB__SHARED_SECRET=<shared_secret>
|
||||||
GITLAB__URL=https://gitlab.com
|
GITLAB__URL=https://gitlab.com
|
||||||
|
GITLAB__AUTH_TYPE=oauth_token # Use "private_token" for older GitLab versions
|
||||||
OPENAI__KEY=<your_openai_api_key>
|
OPENAI__KEY=<your_openai_api_key>
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
@ -111,7 +116,7 @@ For example: `GITLAB.PERSONAL_ACCESS_TOKEN` --> `GITLAB__PERSONAL_ACCESS_TOKEN`
|
||||||
4. Create a lambda function that uses the uploaded image. Set the lambda timeout to be at least 3m.
|
4. Create a lambda function that uses the uploaded image. Set the lambda timeout to be at least 3m.
|
||||||
5. Configure the lambda function to have a Function URL.
|
5. Configure the lambda function to have a Function URL.
|
||||||
6. In the environment variables of the Lambda function, specify `AZURE_DEVOPS_CACHE_DIR` to a writable location such as /tmp. (see [link](https://github.com/Codium-ai/pr-agent/pull/450#issuecomment-1840242269))
|
6. In the environment variables of the Lambda function, specify `AZURE_DEVOPS_CACHE_DIR` to a writable location such as /tmp. (see [link](https://github.com/Codium-ai/pr-agent/pull/450#issuecomment-1840242269))
|
||||||
7. Go back to steps 8-9 of [Run a GitLab webhook server](#run-a-gitlab-webhook-server) with the function url as your Webhook URL.
|
7. Go back to steps 8-9 of [Run a GitLab webhook server](#run-a-gitlab-webhook-server) with the function URL as your Webhook URL.
|
||||||
The Webhook URL would look like `https://<LAMBDA_FUNCTION_URL>/webhook`
|
The Webhook URL would look like `https://<LAMBDA_FUNCTION_URL>/webhook`
|
||||||
|
|
||||||
### Using AWS Secrets Manager
|
### Using AWS Secrets Manager
|
||||||
|
|
|
||||||
|
|
@ -12,7 +12,7 @@ To invoke a tool (for example `review`), you can run PR-Agent directly from the
|
||||||
- For GitHub:
|
- For GitHub:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
docker run --rm -it -e OPENAI.KEY=<your key> -e GITHUB.USER_TOKEN=<your token> codiumai/pr-agent:latest --pr_url <pr_url> review
|
docker run --rm -it -e OPENAI.KEY=<your_openai_key> -e GITHUB.USER_TOKEN=<your_github_token> codiumai/pr-agent:latest --pr_url <pr_url> review
|
||||||
```
|
```
|
||||||
|
|
||||||
If you are using GitHub enterprise server, you need to specify the custom url as variable.
|
If you are using GitHub enterprise server, you need to specify the custom url as variable.
|
||||||
|
|
|
||||||
|
|
@ -33,7 +33,7 @@ To use Qodo Merge on your private GitHub Enterprise Server, you will need to [co
|
||||||
|
|
||||||
### GitHub Open Source Projects
|
### GitHub Open Source Projects
|
||||||
|
|
||||||
For open-source projects, Qodo Merge is available for free usage. To install Qodo Merge for your open-source repositories, use the following marketplace [link](https://github.com/apps/qodo-merge-pro-for-open-source).
|
For open-source projects, Qodo Merge is available for free usage. To install Qodo Merge for your open-source repositories, use the following marketplace [link](https://github.com/marketplace/qodo-merge-pro-for-open-source).
|
||||||
|
|
||||||
## Install Qodo Merge for Bitbucket
|
## Install Qodo Merge for Bitbucket
|
||||||
|
|
||||||
|
|
@ -51,50 +51,80 @@ To use Qodo Merge application on your private Bitbucket Server, you will need to
|
||||||
|
|
||||||
### GitLab Cloud
|
### GitLab Cloud
|
||||||
|
|
||||||
Since GitLab platform does not support apps, installing Qodo Merge for GitLab is a bit more involved, and requires the following steps:
|
Installing Qodo Merge for GitLab uses GitLab's OAuth 2.0 application system and requires the following steps:
|
||||||
|
|
||||||
#### Step 1
|
#### Step 1: Create a GitLab OAuth 2.0 Application
|
||||||
|
|
||||||
Acquire a personal, project or group level access token. Enable the “api” scope in order to allow Qodo Merge to read pull requests, comment and respond to requests.
|
Create a new OAuth 2.0 application in your GitLab instance:
|
||||||
|
|
||||||
<figure markdown="1">
|
1. Navigate to your GitLab group or subgroup settings
|
||||||
{width=750}
|
2. Go to "Applications" in the left sidebar
|
||||||
</figure>
|
3. Click on "Add new application"
|
||||||
|
4. Fill in the application details:
|
||||||
|
- **Name**: You can give any name you wish (e.g., "Qodo Merge")
|
||||||
|
- **Redirect URI**: `https://register.oauth.app.gitlab.merge.qodo.ai/oauth/callback`
|
||||||
|
- **Confidential**: Check this checkbox
|
||||||
|
- **Scopes**: Check the "api" scope
|
||||||
|
|
||||||
|
<figure markdown="1">
|
||||||
|
{width=750}
|
||||||
|
</figure>
|
||||||
|
|
||||||
Store the token in a safe place, you won’t be able to access it again after it was generated.
|
5. Click "Save application"
|
||||||
|
6. Copy both the **Application ID** and **Secret** - store them safely as you'll need them for the next step
|
||||||
|
|
||||||
#### Step 2
|
#### Step 2: Register Your OAuth Application
|
||||||
|
|
||||||
Generate a shared secret and link it to the access token. Browse to [https://register.gitlab.pr-agent.codium.ai](https://register.gitlab.pr-agent.codium.ai).
|
1. Browse to: <https://register.oauth.app.gitlab.merge.qodo.ai>
|
||||||
Fill in your generated GitLab token and your company or personal name in the appropriate fields and click "Submit".
|
2. Fill in the registration form:
|
||||||
|
- **Host Address**: Leave empty if using gitlab.com ([for self-hosted GitLab servers](#gitlab-server), enter your GitLab base URL including scheme (e.g., https://gitlab.mycorp-inc.com) without trailing slash. Do not include paths or query strings.
|
||||||
|
- **OAuth Application ID**: Enter the Application ID from Step 1
|
||||||
|
- **OAuth Application Secret**: Enter the Secret from Step 1
|
||||||
|
|
||||||
|
<figure markdown="1">
|
||||||
|
{width=750}
|
||||||
|
</figure>
|
||||||
|
|
||||||
You should see "Success!" displayed above the Submit button, and a shared secret will be generated. Store it in a safe place, you won’t be able to access it again after it was generated.
|
3. Click "Submit"
|
||||||
|
|
||||||
#### Step 3
|
#### Step 3: Authorize the OAuth Application
|
||||||
|
|
||||||
Install a webhook for your repository or groups, by clicking “webhooks” on the settings menu. Click the “Add new webhook” button.
|
If all fields show green checkmarks, a redirect popup from GitLab will appear requesting authorization for the OAuth app to access the "api" scope. Click "Authorize" to approve the application.
|
||||||
|
|
||||||
<figure markdown="1">
|
#### Step 4: Copy the Webhook Secret Token
|
||||||

|
|
||||||
</figure>
|
|
||||||
|
|
||||||
In the webhook definition form, fill in the following fields:
|
If the authorization is successful, a message will appear displaying a generated webhook secret token. Copy this token and store it safely - you'll need it for the next step.
|
||||||
URL: https://pro.gitlab.pr-agent.codium.ai/webhook
|
|
||||||
|
|
||||||
Secret token: Your QodoAI key
|
#### Step 5: Install Webhooks
|
||||||
Trigger: Check the ‘comments’ and ‘merge request events’ boxes.
|
|
||||||
Enable SSL verification: Check the box.
|
|
||||||
|
|
||||||
<figure markdown="1">
|
Install a webhook for your repository or groups by following these steps:
|
||||||
{width=750}
|
|
||||||
</figure>
|
|
||||||
|
|
||||||
#### Step 4
|
1. Navigate to your repository or group settings
|
||||||
|
2. Click "Webhooks" in the settings menu
|
||||||
|
3. Click the "Add new webhook" button
|
||||||
|
|
||||||
You’re all set!
|
<figure markdown="1">
|
||||||
|

|
||||||
|
</figure>
|
||||||
|
|
||||||
|
4. In the webhook definition form, fill in the following fields:
|
||||||
|
- **URL**: `https://pro.gitlab.pr-agent.codium.ai/webhook`
|
||||||
|
- **Secret token**: The webhook secret token generated in Step 4
|
||||||
|
- **Trigger**: Check the 'Comments' and 'Merge request events' boxes
|
||||||
|
- **Enable SSL verification**: Check this box
|
||||||
|
|
||||||
|
<figure markdown="1">
|
||||||
|
{width=750}
|
||||||
|
</figure>
|
||||||
|
|
||||||
|
5. Click "Add webhook"
|
||||||
|
|
||||||
|
**Note**: Repeat this webhook installation for each group or repository that is under the group or subgroup where the OAuth 2.0 application was created in Step 1.
|
||||||
|
|
||||||
|
#### Step 6: You’re all set!
|
||||||
|
|
||||||
Open a new merge request or add a MR comment with one of Qodo Merge’s commands such as /review, /describe or /improve.
|
Open a new merge request or add a MR comment with one of Qodo Merge’s commands such as /review, /describe or /improve.
|
||||||
|
|
||||||
### GitLab Server
|
### GitLab Server
|
||||||
|
|
||||||
For [limited free usage](https://qodo-merge-docs.qodo.ai/installation/qodo_merge/#cloud-users) on private GitLab Server, the same [installation steps](#gitlab-cloud) as for GitLab Cloud apply. For unlimited usage, you will need to [contact](https://www.qodo.ai/contact/#pricing) Qodo for moving to an Enterprise account.
|
For [limited free usage](https://qodo-merge-docs.qodo.ai/installation/qodo_merge/#cloud-users) on private GitLab Server, the same [installation steps](#gitlab-cloud) as for GitLab Cloud apply, aside from the [Host Address field mentioned in Step 2](#step-2-register-your-oauth-application) (where you fill in the hostname for your GitLab server, such as: https://gitlab.mycorp-inc.com). For unlimited usage, you will need to [contact](https://www.qodo.ai/contact/#pricing) Qodo for moving to an Enterprise account.
|
||||||
|
|
|
||||||
|
|
@ -3,7 +3,8 @@
|
||||||
[Qodo Merge](https://www.codium.ai/pricing/){:target="_blank"} is a hosted version of the open-source [PR-Agent](https://github.com/Codium-ai/pr-agent){:target="_blank"}.
|
[Qodo Merge](https://www.codium.ai/pricing/){:target="_blank"} is a hosted version of the open-source [PR-Agent](https://github.com/Codium-ai/pr-agent){:target="_blank"}.
|
||||||
It is designed for companies and teams that require additional features and capabilities.
|
It is designed for companies and teams that require additional features and capabilities.
|
||||||
|
|
||||||
Free users receive a monthly quota of 75 PR reviews per git organization, while unlimited usage requires a paid subscription. See [details](https://qodo-merge-docs.qodo.ai/installation/qodo_merge/#cloud-users).
|
Free users receive a quota of 75 monthly PR feedbacks per git organization. Unlimited usage requires a paid subscription. See [details](https://qodo-merge-docs.qodo.ai/installation/qodo_merge/#cloud-users).
|
||||||
|
|
||||||
|
|
||||||
Qodo Merge provides the following benefits:
|
Qodo Merge provides the following benefits:
|
||||||
|
|
||||||
|
|
@ -23,7 +24,7 @@ Here are some of the additional features and capabilities that Qodo Merge offers
|
||||||
|
|
||||||
| Feature | Description |
|
| Feature | Description |
|
||||||
| -------------------------------------------------------------------------------------------------------------------- |--------------------------------------------------------------------------------------------------------------------------------------------------------|
|
| -------------------------------------------------------------------------------------------------------------------- |--------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||||
| [**Model selection**](https://qodo-merge-docs.qodo.ai/usage-guide/PR_agent_pro_models/) | Choose the model that best fits your needs, among top models like `Claude Sonnet`, `o4-mini` |
|
| [**Model selection**](https://qodo-merge-docs.qodo.ai/usage-guide/PR_agent_pro_models/) | Choose the model that best fits your needs |
|
||||||
| [**Global and wiki configuration**](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/) | Control configurations for many repositories from a single location; <br>Edit configuration of a single repo without committing code |
|
| [**Global and wiki configuration**](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/) | Control configurations for many repositories from a single location; <br>Edit configuration of a single repo without committing code |
|
||||||
| [**Apply suggestions**](https://qodo-merge-docs.qodo.ai/tools/improve/#overview) | Generate committable code from the relevant suggestions interactively by clicking on a checkbox |
|
| [**Apply suggestions**](https://qodo-merge-docs.qodo.ai/tools/improve/#overview) | Generate committable code from the relevant suggestions interactively by clicking on a checkbox |
|
||||||
| [**Suggestions impact**](https://qodo-merge-docs.qodo.ai/tools/improve/#assessing-impact) | Automatically mark suggestions that were implemented by the user (either directly in GitHub, or indirectly in the IDE) to enable tracking of the impact of the suggestions |
|
| [**Suggestions impact**](https://qodo-merge-docs.qodo.ai/tools/improve/#assessing-impact) | Automatically mark suggestions that were implemented by the user (either directly in GitHub, or indirectly in the IDE) to enable tracking of the impact of the suggestions |
|
||||||
|
|
|
||||||
|
|
@ -3,15 +3,18 @@
|
||||||
## Methodology
|
## Methodology
|
||||||
|
|
||||||
Qodo Merge PR Benchmark evaluates and compares the performance of Large Language Models (LLMs) in analyzing pull request code and providing meaningful code suggestions.
|
Qodo Merge PR Benchmark evaluates and compares the performance of Large Language Models (LLMs) in analyzing pull request code and providing meaningful code suggestions.
|
||||||
Our diverse dataset comprises of 400 pull requests from over 100 repositories, spanning various programming languages and frameworks to reflect real-world scenarios.
|
Our diverse dataset contains 400 pull requests from over 100 repositories, spanning multiple [programming languages](#programming-languages) to reflect real-world scenarios.
|
||||||
|
|
||||||
- For each pull request, we have pre-generated suggestions from [11](https://qodo-merge-docs.qodo.ai/pr_benchmark/#models-used-for-generating-the-benchmark-baseline) different top-performing models using the Qodo Merge `improve` tool. The prompt for response generation can be found [here](https://github.com/qodo-ai/pr-agent/blob/main/pr_agent/settings/code_suggestions/pr_code_suggestions_prompts_not_decoupled.toml).
|
- For each pull request, we have pre-generated suggestions from eleven different top-performing models using the Qodo Merge `improve` tool. The prompt for response generation can be found [here](https://github.com/qodo-ai/pr-agent/blob/main/pr_agent/settings/code_suggestions/pr_code_suggestions_prompts_not_decoupled.toml).
|
||||||
|
|
||||||
- To benchmark a model, we generate its suggestions for the same pull requests and ask a high-performing judge model to **rank** the new model's output against the 11 pre-generated baseline suggestions. We utilize OpenAI's `o3` model as the judge, though other models have yielded consistent results. The prompt for this ranking judgment is available [here](https://github.com/Codium-ai/pr-agent-settings/tree/main/benchmark).
|
- To benchmark a model, we generate its suggestions for the same pull requests and ask a high-performing judge model to **rank** the new model's output against the pre-generated baseline suggestions. We utilize OpenAI's `o3` model as the judge, though other models have yielded consistent results. The prompt for this ranking judgment is available [here](https://github.com/Codium-ai/pr-agent-settings/tree/main/benchmark).
|
||||||
|
|
||||||
- We aggregate ranking outcomes across all pull requests, calculating performance metrics for the evaluated model. We also analyze the qualitative feedback from the judge to identify the model's comparative strengths and weaknesses against the established baselines.
|
- We aggregate ranking outcomes across all pull requests, calculating performance metrics for the evaluated model.
|
||||||
|
|
||||||
|
- We also analyze the qualitative feedback from the judge to identify the model's comparative strengths and weaknesses against the established baselines.
|
||||||
This approach provides not just a quantitative score but also a detailed analysis of each model's strengths and weaknesses.
|
This approach provides not just a quantitative score but also a detailed analysis of each model's strengths and weaknesses.
|
||||||
|
|
||||||
|
A list of the models used for generating the baseline suggestions, and example results, can be found in the [Appendix](#appendix-example-results).
|
||||||
|
|
||||||
[//]: # (Note that this benchmark focuses on quality: the ability of an LLM to process complex pull request with multiple files and nuanced task to produce high-quality code suggestions.)
|
[//]: # (Note that this benchmark focuses on quality: the ability of an LLM to process complex pull request with multiple files and nuanced task to produce high-quality code suggestions.)
|
||||||
|
|
||||||
|
|
@ -19,7 +22,7 @@ This approach provides not just a quantitative score but also a detailed analysi
|
||||||
|
|
||||||
[//]: # ()
|
[//]: # ()
|
||||||
|
|
||||||
## Results
|
## PR Benchmark Results
|
||||||
|
|
||||||
<table>
|
<table>
|
||||||
<thead>
|
<thead>
|
||||||
|
|
@ -31,6 +34,30 @@ This approach provides not just a quantitative score but also a detailed analysi
|
||||||
</tr>
|
</tr>
|
||||||
</thead>
|
</thead>
|
||||||
<tbody>
|
<tbody>
|
||||||
|
<tr>
|
||||||
|
<td style="text-align:left;">GPT-5-pro</td>
|
||||||
|
<td style="text-align:left;">2025-10-06</td>
|
||||||
|
<td style="text-align:left;"></td>
|
||||||
|
<td style="text-align:center;"><b>73.4</b></td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td style="text-align:left;">GPT-5</td>
|
||||||
|
<td style="text-align:left;">2025-08-07</td>
|
||||||
|
<td style="text-align:left;">medium</td>
|
||||||
|
<td style="text-align:center;"><b>72.2</b></td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td style="text-align:left;">GPT-5</td>
|
||||||
|
<td style="text-align:left;">2025-08-07</td>
|
||||||
|
<td style="text-align:left;">low</td>
|
||||||
|
<td style="text-align:center;"><b>67.8</b></td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td style="text-align:left;">GPT-5</td>
|
||||||
|
<td style="text-align:left;">2025-08-07</td>
|
||||||
|
<td style="text-align:left;">minimal</td>
|
||||||
|
<td style="text-align:center;"><b>62.7</b></td>
|
||||||
|
</tr>
|
||||||
<tr>
|
<tr>
|
||||||
<td style="text-align:left;">o3</td>
|
<td style="text-align:left;">o3</td>
|
||||||
<td style="text-align:left;">2025-04-16</td>
|
<td style="text-align:left;">2025-04-16</td>
|
||||||
|
|
@ -43,18 +70,60 @@ This approach provides not just a quantitative score but also a detailed analysi
|
||||||
<td style="text-align:left;">'medium' (<a href="https://ai.google.dev/gemini-api/docs/openai">8000</a>)</td>
|
<td style="text-align:left;">'medium' (<a href="https://ai.google.dev/gemini-api/docs/openai">8000</a>)</td>
|
||||||
<td style="text-align:center;"><b>57.7</b></td>
|
<td style="text-align:center;"><b>57.7</b></td>
|
||||||
</tr>
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td style="text-align:left;">Gemini-3-pro-review</td>
|
||||||
|
<td style="text-align:left;">2025-11-18</td>
|
||||||
|
<td style="text-align:left;">high</td>
|
||||||
|
<td style="text-align:center;"><b>57.3</b></td>
|
||||||
|
</tr>
|
||||||
<tr>
|
<tr>
|
||||||
<td style="text-align:left;">Gemini-2.5-pro</td>
|
<td style="text-align:left;">Gemini-2.5-pro</td>
|
||||||
<td style="text-align:left;">2025-06-05</td>
|
<td style="text-align:left;">2025-06-05</td>
|
||||||
<td style="text-align:left;">4096</td>
|
<td style="text-align:left;">4096</td>
|
||||||
<td style="text-align:center;"><b>56.3</b></td>
|
<td style="text-align:center;"><b>56.3</b></td>
|
||||||
</tr>
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td style="text-align:left;">Gemini-3-pro-review</td>
|
||||||
|
<td style="text-align:left;">2025-11-18</td>
|
||||||
|
<td style="text-align:left;">low</td>
|
||||||
|
<td style="text-align:center;"><b>55.6</b></td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td style="text-align:left;">Claude-haiku-4.5</td>
|
||||||
|
<td style="text-align:left;">2025-10-01</td>
|
||||||
|
<td style="text-align:left;">4096</td>
|
||||||
|
<td style="text-align:center;"><b>48.8</b></td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td style="text-align:left;">GPT-5.1</td>
|
||||||
|
<td style="text-align:left;">2025-11-13</td>
|
||||||
|
<td style="text-align:left;">medium</td>
|
||||||
|
<td style="text-align:center;"><b>44.9</b></td>
|
||||||
|
</tr>
|
||||||
<tr>
|
<tr>
|
||||||
<td style="text-align:left;">Gemini-2.5-pro</td>
|
<td style="text-align:left;">Gemini-2.5-pro</td>
|
||||||
<td style="text-align:left;">2025-06-05</td>
|
<td style="text-align:left;">2025-06-05</td>
|
||||||
<td style="text-align:left;">1024</td>
|
<td style="text-align:left;">1024</td>
|
||||||
<td style="text-align:center;"><b>44.3</b></td>
|
<td style="text-align:center;"><b>44.3</b></td>
|
||||||
</tr>
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td style="text-align:left;">Claude-sonnet-4.5</td>
|
||||||
|
<td style="text-align:left;">2025-09-29</td>
|
||||||
|
<td style="text-align:left;">4096</td>
|
||||||
|
<td style="text-align:center;"><b>44.2</b></td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td style="text-align:left;">Claude-haiku-4.5</td>
|
||||||
|
<td style="text-align:left;">2025-10-01</td>
|
||||||
|
<td style="text-align:left;"></td>
|
||||||
|
<td style="text-align:center;"><b>40.7</b></td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td style="text-align:left;">Claude-sonnet-4.5</td>
|
||||||
|
<td style="text-align:left;">2025-09-29</td>
|
||||||
|
<td style="text-align:left;"></td>
|
||||||
|
<td style="text-align:center;"><b>40.7</b></td>
|
||||||
|
</tr>
|
||||||
<tr>
|
<tr>
|
||||||
<td style="text-align:left;">Claude-4-sonnet</td>
|
<td style="text-align:left;">Claude-4-sonnet</td>
|
||||||
<td style="text-align:left;">2025-05-14</td>
|
<td style="text-align:left;">2025-05-14</td>
|
||||||
|
|
@ -67,18 +136,42 @@ This approach provides not just a quantitative score but also a detailed analysi
|
||||||
<td style="text-align:left;"></td>
|
<td style="text-align:left;"></td>
|
||||||
<td style="text-align:center;"><b>39.0</b></td>
|
<td style="text-align:center;"><b>39.0</b></td>
|
||||||
</tr>
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td style="text-align:left;">Codex-mini</td>
|
||||||
|
<td style="text-align:left;">2025-06-20</td>
|
||||||
|
<td style="text-align:left;"><a href="https://platform.openai.com/docs/models/codex-mini-latest">unknown</a></td>
|
||||||
|
<td style="text-align:center;"><b>37.2</b></td>
|
||||||
|
</tr>
|
||||||
<tr>
|
<tr>
|
||||||
<td style="text-align:left;">Gemini-2.5-flash</td>
|
<td style="text-align:left;">Gemini-2.5-flash</td>
|
||||||
<td style="text-align:left;">2025-04-17</td>
|
<td style="text-align:left;">2025-04-17</td>
|
||||||
<td style="text-align:left;"></td>
|
<td style="text-align:left;"></td>
|
||||||
<td style="text-align:center;"><b>33.5</b></td>
|
<td style="text-align:center;"><b>33.5</b></td>
|
||||||
</tr>
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td style="text-align:left;">Grok-4</td>
|
||||||
|
<td style="text-align:left;">2025-07-09</td>
|
||||||
|
<td style="text-align:left;">unknown</td>
|
||||||
|
<td style="text-align:center;"><b>32.8</b></td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td style="text-align:left;">Claude-4-opus-20250514</td>
|
||||||
|
<td style="text-align:left;">2025-05-14</td>
|
||||||
|
<td style="text-align:left;"></td>
|
||||||
|
<td style="text-align:center;"><b>32.8</b></td>
|
||||||
|
</tr>
|
||||||
<tr>
|
<tr>
|
||||||
<td style="text-align:left;">Claude-3.7-sonnet</td>
|
<td style="text-align:left;">Claude-3.7-sonnet</td>
|
||||||
<td style="text-align:left;">2025-02-19</td>
|
<td style="text-align:left;">2025-02-19</td>
|
||||||
<td style="text-align:left;"></td>
|
<td style="text-align:left;"></td>
|
||||||
<td style="text-align:center;"><b>32.4</b></td>
|
<td style="text-align:center;"><b>32.4</b></td>
|
||||||
</tr>
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td style="text-align:left;">Claude-opus-4.5</td>
|
||||||
|
<td style="text-align:left;">2025-11-01</td>
|
||||||
|
<td style="text-align:left;">high</td>
|
||||||
|
<td style="text-align:center;"><b>30.3</b></td>
|
||||||
|
</tr>
|
||||||
<tr>
|
<tr>
|
||||||
<td style="text-align:left;">GPT-4.1</td>
|
<td style="text-align:left;">GPT-4.1</td>
|
||||||
<td style="text-align:left;">2025-04-14</td>
|
<td style="text-align:left;">2025-04-14</td>
|
||||||
|
|
@ -88,20 +181,38 @@ This approach provides not just a quantitative score but also a detailed analysi
|
||||||
</tbody>
|
</tbody>
|
||||||
</table>
|
</table>
|
||||||
|
|
||||||
## Results Analysis
|
## Results Analysis (Latest Additions)
|
||||||
|
|
||||||
|
### GPT-5-pro
|
||||||
|
|
||||||
|
Final score: **73.4**
|
||||||
|
|
||||||
|
Strengths:
|
||||||
|
|
||||||
|
- **High bug‐finding accuracy and depth:** In many cases the model uncovers the core compile-time or run-time regression that other answers miss and frequently combines several distinct critical issues into one reply.
|
||||||
|
- **Actionable, minimal patches:** Suggestions almost always include clear before/after code blocks that touch only the added lines and respect the ≤3-suggestion limit, making them easy to apply.
|
||||||
|
- **Good guideline compliance:** The model generally honours the task rules—no edits to unchanged code, no version bumps, no more than three items—and shows solid judgment about when an empty list is appropriate.
|
||||||
|
- **Concise, impact-oriented reasoning:** Explanations focus on severity, crash potential and build breakage rather than style, helping reviewers prioritise fixes.
|
||||||
|
|
||||||
|
Weaknesses:
|
||||||
|
|
||||||
|
- **Coverage gaps:** In a noticeable minority of examples the model misses a higher-impact defect that several other answers catch, or returns an empty list despite clear bugs.
|
||||||
|
- **Occasional incorrect or harmful fixes:** A few replies introduce new errors or rest on wrong assumptions about functionality or language-specific behavior.
|
||||||
|
- **Formatting / guideline slips:** Sporadic duplication of suggestions, missing or empty `improved_code` blocks, or YAML mishaps undermine otherwise good answers.
|
||||||
|
- **Uneven criticality judgement:** Some suggestions drift into low-impact territory while overlooking more severe problems, indicating inconsistent prioritisation.
|
||||||
|
|
||||||
### O3
|
### O3
|
||||||
|
|
||||||
Final score: **62.5**
|
Final score: **62.5**
|
||||||
|
|
||||||
strengths:
|
Strengths:
|
||||||
|
|
||||||
- **High precision & compliance:** Generally respects task rules (limits, “added lines” scope, YAML schema) and avoids false-positive advice, often returning an empty list when appropriate.
|
- **High precision & compliance:** Generally respects task rules (limits, “added lines” scope, YAML schema) and avoids false-positive advice, often returning an empty list when appropriate.
|
||||||
- **Clear, actionable output:** Suggestions are concise, well-explained and include correct before/after patches, so reviewers can apply them directly.
|
- **Clear, actionable output:** Suggestions are concise, well-explained and include correct before/after patches, so reviewers can apply them directly.
|
||||||
- **Good critical-bug detection rate:** Frequently spots compile-breakers or obvious runtime faults (nil / NPE, overflow, race, wrong selector, etc.), putting it at least on par with many peers.
|
- **Good critical-bug detection rate:** Frequently spots compile-breakers or obvious runtime faults (nil / NPE, overflow, race, wrong selector, etc.), putting it at least on par with many peers.
|
||||||
- **Consistent formatting:** Produces syntactically valid YAML with correct labels, making automated consumption easy.
|
- **Consistent formatting:** Produces syntactically valid YAML with correct labels, making automated consumption easy.
|
||||||
|
|
||||||
weaknesses:
|
Weaknesses:
|
||||||
|
|
||||||
- **Narrow coverage:** Tends to stop after 1-2 issues; regularly misses additional critical defects that better answers catch, so it is seldom the top-ranked review.
|
- **Narrow coverage:** Tends to stop after 1-2 issues; regularly misses additional critical defects that better answers catch, so it is seldom the top-ranked review.
|
||||||
- **Occasional inaccuracies:** A few replies introduce new bugs, give partial/duplicate fixes, or (rarely) violate rules (e.g., import suggestions), hurting trust.
|
- **Occasional inaccuracies:** A few replies introduce new bugs, give partial/duplicate fixes, or (rarely) violate rules (e.g., import suggestions), hurting trust.
|
||||||
|
|
@ -112,121 +223,284 @@ weaknesses:
|
||||||
|
|
||||||
Final score: **57.7**
|
Final score: **57.7**
|
||||||
|
|
||||||
strengths:
|
Strengths:
|
||||||
|
|
||||||
- **Good rule adherence:** Most answers respect the “new-lines only”, 3-suggestion, and YAML-schema limits, and frequently choose the safe empty list when the diff truly adds no critical bug.
|
- **Good rule adherence:** Most answers respect the “new-lines only”, 3-suggestion, and YAML-schema limits, and frequently choose the safe empty list when the diff truly adds no critical bug.
|
||||||
- **Clear, minimal patches:** When the model does spot a defect it usually supplies terse, valid before/after snippets and short, targeted explanations, making fixes easy to read and apply.
|
- **Clear, minimal patches:** When the model does spot a defect it usually supplies terse, valid before/after snippets and short, targeted explanations, making fixes easy to read and apply.
|
||||||
- **Language & domain breadth:** Demonstrates competence across many ecosystems (C/C++, Java, TS/JS, Go, Rust, Python, Bash, Markdown, YAML, SQL, CSS, translation files, etc.) and can detect both compile-time and runtime mistakes.
|
- **Language & domain breadth:** Demonstrates competence across many ecosystems (C/C++, Java, TS/JS, Go, Rust, Python, Bash, Markdown, YAML, SQL, CSS, translation files, etc.) and can detect both compile-time and runtime mistakes.
|
||||||
- **Often competitive:** In a sizeable minority of cases the model ties for best or near-best answer, occasionally being the only response to catch a subtle crash or build blocker.
|
- **Often competitive:** In a sizeable minority of cases the model ties for best or near-best answer, occasionally being the only response to catch a subtle crash or build blocker.
|
||||||
|
|
||||||
weaknesses:
|
Weaknesses:
|
||||||
|
|
||||||
- **High miss rate:** A large share of examples show the model returning an empty list or only minor advice while other reviewers catch clear, high-impact bugs—indicative of weak defect-detection recall.
|
- **High miss rate:** A large share of examples show the model returning an empty list or only minor advice while other reviewers catch clear, high-impact bugs—indicative of weak defect-detection recall.
|
||||||
- **False or harmful fixes:** Several answers introduce new compilation errors, propose out-of-scope changes, or violate explicit rules (e.g., adding imports, version bumps, touching untouched lines), reducing trustworthiness.
|
- **False or harmful fixes:** Several answers introduce new compilation errors, propose out-of-scope changes, or violate explicit rules (e.g., adding imports, version bumps, touching untouched lines), reducing trustworthiness.
|
||||||
- **Shallow coverage:** Even when it identifies one real issue it often stops there, missing additional critical problems found by stronger peers; breadth and depth are inconsistent.
|
- **Shallow coverage:** Even when it identifies one real issue it often stops there, missing additional critical problems found by stronger peers; breadth and depth are inconsistent.
|
||||||
|
|
||||||
|
### Gemini-3-pro-review (high thinking budget)
|
||||||
|
|
||||||
|
Final score: **57.3**
|
||||||
|
|
||||||
|
Strengths:
|
||||||
|
|
||||||
|
- **Good schema & format discipline:** Consistently returns well-formed YAML with correct fields and respects the 3-suggestion limit; rarely breaks the required output structure.
|
||||||
|
- **Reasonable guideline awareness:** Often recognises when a diff contains only data / translations and properly emits an empty list, avoiding over-reporting.
|
||||||
|
- **Clear, actionable patches when correct:** When it does find a bug it usually supplies minimal-diff, compilable code snippets with concise explanations, and occasionally surfaces issues no other model spotted.
|
||||||
|
|
||||||
|
Weaknesses:
|
||||||
|
|
||||||
|
- **Spot-coverage gaps on critical defects:** In a large share of cases it overlooks the principal regression the tests were written for, while fixating on minor style or performance nits.
|
||||||
|
- **False or speculative fixes:** A noticeable number of answers invent non-existent problems or propose changes that would not compile or would re-introduce removed behaviour.
|
||||||
|
- **Guideline violations creep in:** Sometimes touches unchanged lines, adds forbidden imports / labels, or supplies more than "critical" advice, showing imperfect rule adherence.
|
||||||
|
- **High variance / inconsistency:** Quality swings from best-in-class to harmful within consecutive examples, indicating unstable defect-prioritisation and review depth.
|
||||||
|
|
||||||
### Gemini-2.5 Pro (4096 thinking tokens)
|
### Gemini-2.5 Pro (4096 thinking tokens)
|
||||||
|
|
||||||
Final score: **56.3**
|
Final score: **56.3**
|
||||||
|
|
||||||
strengths:
|
Strengths:
|
||||||
|
|
||||||
- **High formatting compliance:** The model almost always produces valid YAML, respects the three-suggestion limit, and supplies clear before/after code snippets and short rationales.
|
- **High formatting compliance:** The model almost always produces valid YAML, respects the three-suggestion limit, and supplies clear before/after code snippets and short rationales.
|
||||||
- **Good “first-bug” detection:** It frequently notices the single most obvious regression (crash, compile error, nil/NPE risk, wrong path, etc.) and gives a minimal, correct patch—often judged “on-par” with other solid answers.
|
- **Good “first-bug” detection:** It frequently notices the single most obvious regression (crash, compile error, nil/NPE risk, wrong path, etc.) and gives a minimal, correct patch—often judged “on-par” with other solid answers.
|
||||||
- **Clear, concise writing:** Explanations are brief yet understandable for reviewers; fixes are scoped to the changed lines and rarely include extraneous context.
|
- **Clear, concise writing:** Explanations are brief yet understandable for reviewers; fixes are scoped to the changed lines and rarely include extraneous context.
|
||||||
- **Low rate of harmful fixes:** Truly dangerous or build-breaking advice is rare; most mistakes are omissions rather than wrong code.
|
- **Low rate of harmful fixes:** Truly dangerous or build-breaking advice is rare; most mistakes are omissions rather than wrong code.
|
||||||
|
|
||||||
weaknesses:
|
Weaknesses:
|
||||||
|
|
||||||
- **Limited breadth of review:** The model regularly stops after the first or second issue, missing additional critical problems that stronger answers surface, so it is often out-ranked by more comprehensive peers.
|
- **Limited breadth of review:** The model regularly stops after the first or second issue, missing additional critical problems that stronger answers surface, so it is often out-ranked by more comprehensive peers.
|
||||||
- **Occasional guideline violations:** A noticeable minority of answers touch unchanged lines, exceed the 3-item cap, suggest adding imports, or drop the required YAML wrapper, leading to automatic downgrades.
|
- **Occasional guideline violations:** A noticeable minority of answers touch unchanged lines, exceed the 3-item cap, suggest adding imports, or drop the required YAML wrapper, leading to automatic downgrades.
|
||||||
- **False positives / speculative fixes:** In several cases it flags non-issues (style, performance, redundant code) or supplies debatable “improvements”, lowering precision and sometimes breaching the “critical bugs only” rule.
|
- **False positives / speculative fixes:** In several cases it flags non-issues (style, performance, redundant code) or supplies debatable “improvements”, lowering precision and sometimes breaching the “critical bugs only” rule.
|
||||||
- **Inconsistent error coverage:** For certain domains (build scripts, schema files, test code) it either returns an empty list when real regressions exist or proposes cosmetic edits, indicating gaps in specialised knowledge.
|
- **Inconsistent error coverage:** For certain domains (build scripts, schema files, test code) it either returns an empty list when real regressions exist or proposes cosmetic edits, indicating gaps in specialised knowledge.
|
||||||
|
|
||||||
### Claude-4 Sonnet (4096 thinking tokens)
|
### Gemini-3-pro-review (low thinking budget)
|
||||||
|
|
||||||
Final score: **39.7**
|
Final score: **55.6**
|
||||||
|
|
||||||
strengths:
|
Strengths:
|
||||||
|
|
||||||
- **High guideline & format compliance:** Almost always returns valid YAML, keeps ≤ 3 suggestions, avoids forbidden import/boiler-plate changes and provides clear before/after snippets.
|
- **Concise, well-structured patches:** Suggestions are usually expressed in short, self-contained YAML items with clear before/after code blocks and just enough rationale, making them easy for reviewers to apply.
|
||||||
- **Good pinpoint accuracy on single issues:** Frequently spots at least one real critical bug and proposes a concise, technically correct fix that compiles/runs.
|
- **Good eye for crash-level defects:** When the model does spot a problem it often focuses on high-impact issues such as compile-time errors, NPEs, nil-pointer races, buffer overflows, etc., and supplies a minimal, correct fix.
|
||||||
- **Clarity & brevity of patches:** Explanations are short, actionable, and focused on changed lines, making the advice easy for reviewers to apply.
|
- **High guideline compliance (format & scope):** In most cases it respects the 1-3-item limit and the "new lines only" rule, avoids changing imports, and keeps snippets syntactically valid.
|
||||||
|
|
||||||
weaknesses:
|
Weaknesses:
|
||||||
|
|
||||||
- **Low coverage / recall:** Regularly surfaces only one minor issue (or none) while missing other, often more severe, problems caught by peer models.
|
- **Coverage inconsistency:** Many answers miss other obvious or even more critical regressions spotted by peers; breadth fluctuates from excellent to empty, leaving reviewers with partial insight.
|
||||||
- **High “empty-list” rate:** In many diffs the model returns no suggestions even when clear critical bugs exist, offering zero reviewer value.
|
- **False positives & speculative advice:** A noticeable share of suggestions target stylistic or non-critical tweaks, or even introduce wrong changes, betraying occasional mis-reading of the diff and hurting trust.
|
||||||
- **Occasional incorrect or harmful fixes:** A non-trivial number of suggestions are speculative, contradict code intent, or would break compilation/runtime; sometimes duplicates or contradicts itself.
|
- **Rule violations still occur:** There are repeated instances of touching unchanged code, recommending version bumps/imports, mis-labelling severities, or outputting malformed snippets—showing lapses in instruction adherence.
|
||||||
- **Inconsistent severity labelling & duplication:** Repeats the same point in multiple slots, marks cosmetic edits as “critical”, or leaves `improved_code` identical to original.
|
- **Quality variance / empty outputs:** Some responses provide no suggestions despite real bugs, while others supply harmful fixes; this volatility lowers overall reliability.
|
||||||
|
|
||||||
|
### Claude-haiku-4.5 (4096 thinking tokens)
|
||||||
|
|
||||||
|
Final score: **48.8**
|
||||||
|
|
||||||
|
Strengths:
|
||||||
|
|
||||||
|
- **High precision on detected issues:** When the model does flag a problem it is usually a real, high-impact bug; many answers are judged equal or better than strong baselines because the proposed fix is correct, minimal and easy to apply.
|
||||||
|
- **Language- and domain-agnostic competence:** It successfully diagnoses defects across a wide range of languages (Python, Go, C/C++, Rust, JS/TS, CSS, SQL, Markdown, etc.) and domains (backend logic, build files, tests, docs).
|
||||||
|
- **Clear, actionable patches:** Suggested code is typically concise, well-explained and scoped exactly to the added lines, making it practical for reviewers to adopt.
|
||||||
|
|
||||||
|
Weaknesses:
|
||||||
|
|
||||||
|
- **Low recall / narrow coverage:** The model often stops after one or two findings, leaving other obvious critical bugs unmentioned; in many examples stronger answers simply covered more ground.
|
||||||
|
- **Occasional faulty or speculative fixes:** A non-trivial number of responses either mis-diagnose the issue or introduce new errors (e.g., wrong logic, undeclared imports), dropping them below baseline quality.
|
||||||
|
- **Inconsistent output robustness:** Several cases show truncated or malformed responses, reducing value despite correct analysis elsewhere.
|
||||||
|
- **Frequent false negatives:** The model sometimes returns an empty list even when clear regressions exist, indicating conservative behaviour that misses mandatory fixes.
|
||||||
|
|
||||||
|
### GPT-5.1 ('medium' thinking budget)
|
||||||
|
|
||||||
|
Final score: **44.9**
|
||||||
|
|
||||||
|
Strengths:
|
||||||
|
|
||||||
|
- **High precision & guideline compliance:** When the model does emit suggestions they are almost always technically sound, respect the "new-lines-only / ≤3 suggestions / no-imports" rules, and are formatted correctly. It rarely introduces harmful changes and often provides clear, runnable patches.
|
||||||
|
- **Ability to spot subtle or unique defects:** In several cases the model caught a critical issue that most or all baselines missed, showing good deep-code reasoning when it does engage.
|
||||||
|
- **Good judgment on noise-free diffs:** On purely data or documentation changes the model frequently (and correctly) returns an empty list, avoiding false-positive "nit" feedback.
|
||||||
|
|
||||||
|
Weaknesses:
|
||||||
|
|
||||||
|
- **Very low recall / over-conservatism:** In a large fraction of examples it outputs an empty suggestion list while clear critical bugs exist (well over 50 % of cases), making it inferior to almost every baseline answer that offered any fix.
|
||||||
|
- **Narrow coverage when it speaks:** Even when it flags one bug, it often stops there and ignores other equally critical problems present in the same diff, leaving reviewers with partial insight.
|
||||||
|
- **Occasional misdiagnosis or harmful fix:** A minority of suggestions are wrong or counter-productive, showing that precision, while good, is not perfect.
|
||||||
|
|
||||||
|
### Claude-sonnet-4.5 (4096 thinking tokens)
|
||||||
|
|
||||||
|
Final score: **44.2**
|
||||||
|
|
||||||
|
Strengths:
|
||||||
|
|
||||||
|
- **High precision / low noise:** When the model does offer fixes they are usually correct, concise and confined to the new '+' lines, rarely introducing spurious or off-scope changes.
|
||||||
|
- **Clear, actionable patches:** Suggestions come with well-explained reasoning and minimal but valid code snippets, making them easy for a reviewer to apply.
|
||||||
|
- **Good rule compliance:** It almost always respects the 1-3 suggestion limit, avoids touching unchanged code and seldom violates formatting or other task guidelines.
|
||||||
|
|
||||||
|
Weaknesses:
|
||||||
|
|
||||||
|
- **Low recall / frequent omissions:** In a large share of cases the model returns an empty list or only one minor tip while overlooking obvious, higher-impact regressions found by peers.
|
||||||
|
- **Narrow coverage when it does respond:** Even in non-empty outputs it typically fixes a single issue and ignores related defects in the same diff, indicating shallow analysis.
|
||||||
|
- **Occasional harmful or incomplete fixes:** A few suggestions introduce new errors (e.g., wrong logic, missing imports, malformed snippets) or mark non-critical style nits as "critical", reducing trust.
|
||||||
|
|
||||||
|
### Claude-sonnet-4.5
|
||||||
|
|
||||||
|
Final score: **40.7**
|
||||||
|
|
||||||
|
Strengths:
|
||||||
|
|
||||||
|
- **Concise & well-formatted output:** Most replies strictly follow the schema, stay within the 3-suggestion limit, and include clear, copy-paste-ready patches, making them easy to apply.
|
||||||
|
- **Can spot headline bugs:** When a single, obvious regression is present (e.g. duplicated regex block, missing null-check, wrong macro name) the model often detects it and proposes an accurate, minimal fix.
|
||||||
|
- **Scope discipline (usually):** It frequently restricts changes to newly-added lines and avoids broad refactors, so many answers comply with the “new code only / critical bugs only” rule.
|
||||||
|
- **Reasonable explanations:** The accompanying rationales are typically short but precise, helping reviewers understand why the change is needed.
|
||||||
|
|
||||||
|
Weaknesses:
|
||||||
|
|
||||||
|
- **Low recall of critical issues:** In a large fraction of examples the model misses the primary bug or flags nothing at all while other reviewers find clear problems. Coverage is therefore unreliable.
|
||||||
|
- **False or harmful fixes:** A notable number of suggestions mis-diagnose the code, touch unchanged lines, violate task rules, or would break compilation/runtime (wrong paths, bad types, guideline-forbidden advice).
|
||||||
|
- **Priority mistakes:** The model often downgrades severe defects to “general” or upgrades cosmetic nits to “critical”, showing weak bug-severity judgment.
|
||||||
|
- **Inconsistent quality:** Performance swings widely between excellent and poor; reviewers cannot predict whether a given answer will be thorough, partial, or incorrect.
|
||||||
|
|
||||||
|
### Claude-haiku-4.5
|
||||||
|
|
||||||
|
Final score: 40.7
|
||||||
|
|
||||||
|
Strengths:
|
||||||
|
|
||||||
|
- **Good format & clarity: Consistently produces valid YAML and readable, minimally-intrusive patches with clear before/after snippets, so its outputs are easy to apply.
|
||||||
|
- **Basic bug-spotting ability: Often detects the most obvious new-line defect (e.g., syntax error, missing guard, wrong constant) and supplies a correct, concise fix; rarely ranks last in the set.
|
||||||
|
- **Rule compliance in many cases: Usually stays within the 3-suggestion limit, touches only '+' lines, and avoids speculative refactors—returning an empty list when no code was added.
|
||||||
|
|
||||||
|
Weaknesses:
|
||||||
|
|
||||||
|
- **Shallow coverage: Frequently fixes just one surface-level issue and misses additional, higher-impact bugs that stronger reviewers catch, leaving regressions in place.
|
||||||
|
- **Occasional incorrect or no-op patches: A noticeable share of suggestions either leave code unchanged, contain invalid code, or introduce new errors, lowering trust.
|
||||||
|
- **Guideline slips: In several examples it edits unchanged lines, adds forbidden imports/version bumps, mis-labels severities, or supplies non-critical stylistic advice.
|
||||||
|
- **Inconsistent diligence: Roughly a quarter of the cases return an empty list despite real problems, while others duplicate existing PR changes, indicating weak diff comprehension.
|
||||||
|
|
||||||
|
|
||||||
### Claude-4 Sonnet
|
### OpenAI codex-mini
|
||||||
|
|
||||||
Final score: **39.0**
|
Final score: **37.2**
|
||||||
|
|
||||||
strengths:
|
Strengths:
|
||||||
|
|
||||||
- **Consistently well-formatted & rule-compliant output:** Almost every answer follows the required YAML schema, keeps within the 3-suggestion limit, and returns an empty list when no issues are found, showing good instruction following.
|
- **Can spot high-impact defects:** When it "locks on", codex-mini often identifies the main runtime or security regression (e.g., race-conditions, logic inversions, blocking I/O, resource leaks) and proposes a minimal, direct patch that compiles and respects neighbouring style.
|
||||||
|
- **Produces concise, scoped fixes:** Valid answers usually stay within the allowed 3-suggestion limit, reference only the added lines, and contain clear before/after snippets that reviewers can apply verbatim.
|
||||||
|
- **Occasional broad coverage:** In a minority of cases the model catches multiple independent issues (logic + tests + docs) and outperforms every baseline answer, showing good contextual understanding of heterogeneous diffs.
|
||||||
|
|
||||||
- **Actionable, code-level patches:** When it does spot a defect the model usually supplies clear, minimal diffs or replacement snippets that compile / run, making the fix easy to apply.
|
Weaknesses:
|
||||||
|
|
||||||
- **Decent hit-rate on “obvious” bugs:** The model reliably catches the most blatant syntax errors, null-checks, enum / cast problems, and other first-order issues, so it often ties or slightly beats weaker baseline replies.
|
|
||||||
|
|
||||||
weaknesses:
|
|
||||||
|
|
||||||
- **Shallow coverage:** It frequently stops after one easy bug and overlooks additional, equally-critical problems that stronger reviewers find, leaving significant risks unaddressed.
|
|
||||||
|
|
||||||
- **False positives & harmful fixes:** In a noticeable minority of cases it misdiagnoses code, suggests changes that break compilation or behaviour, or flags non-issues, sometimes making its output worse than doing nothing.
|
|
||||||
|
|
||||||
- **Drifts into non-critical or out-of-scope advice:** The model regularly proposes style tweaks, documentation edits, or changes to unchanged lines, violating the “critical new-code only” requirement.
|
|
||||||
|
|
||||||
|
- **Output instability / format errors:** A very large share of responses are unusable—plain refusals, shell commands, or malformed/empty YAML—indicating brittle adherence to the required schema and tanking overall usefulness.
|
||||||
|
- **Critical-miss rate:** Even when the format is correct the model frequently overlooks the single most serious bug the diff introduces, instead focusing on stylistic nits or speculative refactors.
|
||||||
|
- **Introduces new problems:** Several suggestions add unsupported APIs, undeclared variables, wrong types, or break compilation, hurting trust in the recommendations.
|
||||||
|
- **Rule violations:** It often edits lines outside the diff, exceeds the 3-suggestion cap, or labels cosmetic tweaks as "critical", showing inconsistent guideline compliance.
|
||||||
|
|
||||||
### Gemini-2.5 Flash
|
### Gemini-2.5 Flash
|
||||||
|
|
||||||
strengths:
|
Final score: **33.5**
|
||||||
|
|
||||||
|
Strengths:
|
||||||
|
|
||||||
- **High precision / low false-positive rate:** The model often stays silent or gives a single, well-justified fix, so when it does speak the suggestion is usually correct and seldom touches unchanged lines, keeping guideline compliance high.
|
- **High precision / low false-positive rate:** The model often stays silent or gives a single, well-justified fix, so when it does speak the suggestion is usually correct and seldom touches unchanged lines, keeping guideline compliance high.
|
||||||
- **Good guideline awareness:** YAML structure is consistently valid; suggestions rarely exceed the 3-item limit and generally restrict themselves to newly-added lines.
|
- **Good guideline awareness:** YAML structure is consistently valid; suggestions rarely exceed the 3-item limit and generally restrict themselves to newly-added lines.
|
||||||
- **Clear, concise patches:** When a defect is found, the model produces short rationales and tidy “improved_code” blocks that reviewers can apply directly.
|
- **Clear, concise patches:** When a defect is found, the model produces short rationales and tidy “improved_code” blocks that reviewers can apply directly.
|
||||||
- **Risk-averse behaviour pays off in “no-bug” PRs:** In examples where the diff truly contained no critical issue, the model’s empty output ranked above peers that offered speculative or stylistic advice.
|
- **Risk-averse behaviour pays off in “no-bug” PRs:** In examples where the diff truly contained no critical issue, the model’s empty output ranked above peers that offered speculative or stylistic advice.
|
||||||
|
|
||||||
weaknesses:
|
Weaknesses:
|
||||||
|
|
||||||
- **Very low recall / shallow coverage:** In a large majority of cases it gives 0-1 suggestions and misses other evident, critical bugs highlighted by peer models, leading to inferior rankings.
|
- **Very low recall / shallow coverage:** In a large majority of cases it gives 0-1 suggestions and misses other evident, critical bugs highlighted by peer models, leading to inferior rankings.
|
||||||
- **Occasional incorrect or harmful fixes:** A noticeable subset of answers propose changes that break functionality or misunderstand the code (e.g. bad constant, wrong header logic, speculative rollbacks).
|
- **Occasional incorrect or harmful fixes:** A noticeable subset of answers propose changes that break functionality or misunderstand the code (e.g. bad constant, wrong header logic, speculative rollbacks).
|
||||||
- **Non-actionable placeholders:** Some “improved_code” sections contain comments or “…” rather than real patches, reducing practical value.
|
- **Non-actionable placeholders:** Some “improved_code” sections contain comments or “…” rather than real patches, reducing practical value.
|
||||||
-
|
|
||||||
### GPT-4.1
|
|
||||||
|
|
||||||
Final score: **26.5**
|
### Claude-4 Opus
|
||||||
|
|
||||||
strengths:
|
Final score: **32.8**
|
||||||
|
|
||||||
- **Consistent format & guideline obedience:** Output is almost always valid YAML, within the 3-suggestion limit, and rarely touches lines not prefixed with “+”.
|
Strengths:
|
||||||
- **Low false-positive rate:** When no real defect exists, the model correctly returns an empty list instead of inventing speculative fixes, avoiding the “noise” many baseline answers add.
|
|
||||||
- **Clear, concise patches when it does act:** In the minority of cases where it detects a bug (e.g., ex-13, 46, 212), the fix is usually correct, minimal, and easy to apply.
|
|
||||||
|
|
||||||
weaknesses:
|
- **Format & rule adherence:** Almost always returns valid YAML, stays within the ≤3-suggestion limit, and usually restricts edits to newly-added lines, so its output is easy to apply automatically.
|
||||||
|
- **Concise, focused patches:** When it does find a real bug it gives short, well-scoped explanations plus minimal diff snippets, often outperforming verbose baselines in clarity.
|
||||||
|
- **Able to catch subtle edge-cases:** In several examples it detected overflow, race-condition or enum-mismatch issues that many other models missed, showing solid code‐analysis capability.
|
||||||
|
|
||||||
- **Very low recall / coverage:** In a large majority of examples it outputs an empty list or only 1 trivial suggestion while obvious critical issues remain unfixed; it systematically misses circular bugs, null-checks, schema errors, etc.
|
Weaknesses:
|
||||||
- **Shallow analysis:** Even when it finds one problem it seldom looks deeper, so more severe or additional bugs in the same diff are left unaddressed.
|
|
||||||
- **Occasional technical inaccuracies:** A noticeable subset of suggestions are wrong (mis-ordered assertions, harmful Bash `set` change, false dangling-reference claims) or carry metadata errors (mis-labeling files as “python”).
|
|
||||||
- **Repetitive / derivative fixes:** Many outputs duplicate earlier simplistic ideas (e.g., single null-check) without new insight, showing limited reasoning breadth.
|
|
||||||
|
|
||||||
|
- **Low recall / narrow coverage:** In a large share of the 399 examples the model produced an empty list or only one minor tip while more serious defects were present, causing it to be rated inferior to most baselines.
|
||||||
|
- **Frequent incorrect or no-op fixes:** It sometimes supplies identical “before/after” code, flags non-issues, or suggests changes that would break compilation or logic, reducing reviewer trust.
|
||||||
|
- **Shaky guideline consistency:** Although generally compliant, it still occasionally violates rules (touches unchanged lines, offers stylistic advice, adds imports) and duplicates suggestions, indicating unstable internal checks.
|
||||||
|
|
||||||
## Appendix - models used for generating the benchmark baseline
|
### Grok-4
|
||||||
|
|
||||||
- anthropic_sonnet_3.7_v1:0
|
Final score: **32.8**
|
||||||
- claude-4-opus-20250514
|
|
||||||
- claude-4-sonnet-20250514
|
|
||||||
- claude-4-sonnet-20250514_thinking_2048
|
|
||||||
- gemini-2.5-flash-preview-04-17
|
|
||||||
- gemini-2.5-pro-preview-05-06
|
|
||||||
- gemini-2.5-pro-preview-06-05_1024
|
|
||||||
- gemini-2.5-pro-preview-06-05_4096
|
|
||||||
- gpt-4.1
|
|
||||||
- o3
|
|
||||||
- o4-mini_medium
|
|
||||||
|
|
||||||
|
Strengths:
|
||||||
|
|
||||||
|
- **Focused and concise fixes:** When the model does detect a problem it usually proposes a minimal, well-scoped patch that compiles and directly addresses the defect without unnecessary noise.
|
||||||
|
- **Good critical-bug instinct:** It often prioritises show-stoppers (compile failures, crashes, security issues) over cosmetic matters and occasionally spots subtle issues that all other reviewers miss.
|
||||||
|
- **Clear explanations & snippets:** Explanations are short, readable and paired with ready-to-paste code, making the advice easy to apply.
|
||||||
|
|
||||||
|
Weaknesses:
|
||||||
|
|
||||||
|
- **High miss rate:** In a large fraction of examples the model returned an empty list or covered only one minor issue while overlooking more serious newly-introduced bugs.
|
||||||
|
- **Inconsistent accuracy:** A noticeable subset of answers contain wrong or even harmful fixes (e.g., removing valid flags, creating compile errors, re-introducing bugs).
|
||||||
|
- **Limited breadth:** Even when it finds a real defect it rarely reports additional related problems that peers catch, leading to partial reviews.
|
||||||
|
- **Occasional guideline slips:** A few replies modify unchanged lines, suggest new imports, or duplicate suggestions, showing imperfect compliance with instructions.
|
||||||
|
|
||||||
|
### Claude-Opus-4.5 (high thinking budget)
|
||||||
|
|
||||||
|
Final score: **30.3**
|
||||||
|
|
||||||
|
Strengths:
|
||||||
|
|
||||||
|
- **High rule compliance & formatting:** Consistently produces valid YAML, respects the ≤3-suggestion limit, and usually confines edits to added lines, avoiding many guideline violations seen in peers.
|
||||||
|
- **Low false-positive rate:** Tends to stay silent unless convinced of a real problem; when the diff is a pure version bump / docs tweak it often (correctly) returns an empty list, beating noisier baselines.
|
||||||
|
- **Clear, focused patches when it fires:** In the minority of cases where it does spot a bug, it explains the issue crisply and supplies concise, copy-paste-able code snippets.
|
||||||
|
|
||||||
|
Weaknesses:
|
||||||
|
|
||||||
|
- **Very low recall:** In the vast majority of examples it misses obvious critical issues or suggests only a subset, frequently returning an empty list; this places it below most baselines on overall usefulness.
|
||||||
|
- **Shallow coverage:** Even when it catches a defect it typically lists a single point and overlooks other high-impact problems present in the same diff.
|
||||||
|
- **Occasional incorrect or incomplete fixes:** A non-trivial number of suggestions are wrong, compile-breaking, duplicate unchanged code, or touch out-of-scope lines, reducing trust.
|
||||||
|
- **Inconsistent severity tagging & duplication:** Sometimes mis-labels critical vs general, repeats the same suggestion, or leaves `improved_code` blocks empty.
|
||||||
|
|
||||||
|
## Appendix - Example Results
|
||||||
|
|
||||||
|
Some examples of benchmarked PRs and their results:
|
||||||
|
|
||||||
|
- [Example 1](https://www.qodo.ai/images/qodo_merge_benchmark/example_results1.html)
|
||||||
|
- [Example 2](https://www.qodo.ai/images/qodo_merge_benchmark/example_results2.html)
|
||||||
|
- [Example 3](https://www.qodo.ai/images/qodo_merge_benchmark/example_results3.html)
|
||||||
|
- [Example 4](https://www.qodo.ai/images/qodo_merge_benchmark/example_results4.html)
|
||||||
|
|
||||||
|
### Models Used for Benchmarking
|
||||||
|
|
||||||
|
The following models were used for generating the benchmark baseline:
|
||||||
|
|
||||||
|
```markdown
|
||||||
|
(1) anthropic_sonnet_3.7_v1:0
|
||||||
|
|
||||||
|
(2) claude-4-opus-20250514
|
||||||
|
|
||||||
|
(3) claude-4-sonnet-20250514
|
||||||
|
|
||||||
|
(4) claude-4-sonnet-20250514_thinking_2048
|
||||||
|
|
||||||
|
(5) gemini-2.5-flash-preview-04-17
|
||||||
|
|
||||||
|
(6) gemini-2.5-pro-preview-05-06
|
||||||
|
|
||||||
|
(7) gemini-2.5-pro-preview-06-05_1024
|
||||||
|
|
||||||
|
(8) gemini-2.5-pro-preview-06-05_4096
|
||||||
|
|
||||||
|
(9) gpt-4.1
|
||||||
|
|
||||||
|
(10) o3
|
||||||
|
|
||||||
|
(11) o4-mini_medium
|
||||||
|
```
|
||||||
|
|
||||||
|
### Programming Languages
|
||||||
|
|
||||||
|
The PR benchmark dataset includes pull requests containing code in the following programming languages:
|
||||||
|
|
||||||
|
```markdown
|
||||||
|
["Python", "JavaScript", "TypeScript", "Java", "CSharp", "PHP", "C++", "Go", "Rust", "Swift", "Kotlin", "Ruby", "Dart", "Scala"
|
||||||
|
```
|
||||||
|
|
||||||
|
Pull requests may also include non-code files such as `YAML`, `JSON`, `Markdown`, `Dockerfile` ,`Shell`, etc.
|
||||||
|
The benchmarked models should also analyze these files, as they commonly appear in real-world pull requests.
|
||||||
|
|
|
||||||
34
docs/docs/qodo-merge-cli/index.md
Normal file
34
docs/docs/qodo-merge-cli/index.md
Normal file
|
|
@ -0,0 +1,34 @@
|
||||||
|
# Review and Implement AI Suggestions from Your Terminal
|
||||||
|
|
||||||
|
**Qodo Merge CLI** utilizes [Qodo Command](https://docs.qodo.ai/qodo-documentation/qodo-command) to bring AI-powered code suggestions directly to your terminal.
|
||||||
|
Review, implement, and manage Qodo Merge suggestions without leaving your development environment.
|
||||||
|
|
||||||
|
{width=768}
|
||||||
|
|
||||||
|
## Mission
|
||||||
|
|
||||||
|
The CLI can bridge the gap between Qodo Merge feedback and code implementation in your local enviroment:
|
||||||
|
|
||||||
|
- **Seamlessly generate and manage PR suggestions** without context switching
|
||||||
|
- Remote Suggestions: Fetches Qodo Merge suggestions from your Git Environment
|
||||||
|
- Local Suggestions: Get real-time suggestions against your local changes
|
||||||
|
- **Interactive review and implementation** of AI feedback directly in your terminal
|
||||||
|
- **Track implementation status** of each suggestion (pending/implemented/declined)
|
||||||
|
|
||||||
|
## Remote Suggestions Flow
|
||||||
|
1. Open a Pull Request on your Git environment and receive Qodo Merge feedback
|
||||||
|
2. Pull the remote suggestions into your terminal with Qodo Merge CLI
|
||||||
|
3. Explore, Review, and implement suggestions interactively
|
||||||
|
4. Commit changes back to your branch seamlessly
|
||||||
|
|
||||||
|
## Local Suggestions Flow
|
||||||
|
Work in progress - coming soon!
|
||||||
|
|
||||||
|
## Quick Start
|
||||||
|
|
||||||
|
1. **[Install](installation.md)** Qodo Merge CLI
|
||||||
|
2. **[Usage](usage.md)** - Navigate, explore, and implement suggestions
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
*Part of the Qodo Merge ecosystem - closing the loop between AI feedback and code implementation.*
|
||||||
70
docs/docs/qodo-merge-cli/installation.md
Normal file
70
docs/docs/qodo-merge-cli/installation.md
Normal file
|
|
@ -0,0 +1,70 @@
|
||||||
|
# Installation
|
||||||
|
|
||||||
|
> For remote suggestions, Qodo Merge needs to be installed and active on your Git repository (GitHub / GitLab), and provide code suggestions in a table format for your Pull Requests (PRs).
|
||||||
|
|
||||||
|
## Install Qodo Command
|
||||||
|
|
||||||
|
Qodo Merge CLI is a review tool within [Qodo Command](https://docs.qodo.ai/qodo-documentation/qodo-command), a command-line interface for running and managing AI agents.
|
||||||
|
|
||||||
|
To use Qodo Command, you'll need first Node.js and npm installed.
|
||||||
|
Then, to install Qodo Command, run:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
npm install -g @qodo/command
|
||||||
|
```
|
||||||
|
|
||||||
|
**Login and Setup**
|
||||||
|
|
||||||
|
To start using Qodo Command, you need to log in first:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
qodo login
|
||||||
|
```
|
||||||
|
|
||||||
|
Once login is completed, you'll receive an API key in the terminal.
|
||||||
|
The API key is also saved locally in the .qodo folder in your home directory, and can be reused (e.g., in CI).
|
||||||
|
The key is tied to your user account and subject to the same usage limits.
|
||||||
|
|
||||||
|
|
||||||
|
## Using Qodo Merge CLI
|
||||||
|
|
||||||
|
After you set up Qodo Command, you can start using Qodo Merge CLI by running:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
qodo merge
|
||||||
|
```
|
||||||
|
### Set Up Git Client
|
||||||
|
On first run, the CLI will check for your Git client (GitHub CLI or GitLab CLI).
|
||||||
|
If not found, it will guide you through the installation process.
|
||||||
|
|
||||||
|
{width=384}
|
||||||
|
|
||||||
|
|
||||||
|
## Quick Usage
|
||||||
|
|
||||||
|
There are two ways to specify which PR to review:
|
||||||
|
|
||||||
|
(1) **Auto Detect PR from current branch**
|
||||||
|
run this command in your CLI:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
qodo merge
|
||||||
|
```
|
||||||
|
|
||||||
|
(2) **Specify PR number or URL**
|
||||||
|
|
||||||
|
```bash
|
||||||
|
qodo merge 303
|
||||||
|
|
||||||
|
qodo merge https://github.com/owner/repo/pull/303
|
||||||
|
```
|
||||||
|
|
||||||
|
Then the tool will automatically fetch the suggestions from the PR and display them in an interactive table.
|
||||||
|
|
||||||
|
{width=768}
|
||||||
|
|
||||||
|
|
||||||
|
## Next Steps
|
||||||
|
|
||||||
|
**[Usage](usage.md)** - Navigate, explore, and implement suggestions
|
||||||
|
|
||||||
211
docs/docs/qodo-merge-cli/usage.md
Normal file
211
docs/docs/qodo-merge-cli/usage.md
Normal file
|
|
@ -0,0 +1,211 @@
|
||||||
|
# Usage Guide for Qodo Merge CLI
|
||||||
|
|
||||||
|
|
||||||
|
## Understanding the Interface
|
||||||
|
|
||||||
|
### Why a Structured Table?
|
||||||
|
|
||||||
|
The suggestions table serves as the core interface for reviewing and managing AI feedback.
|
||||||
|
|
||||||
|
The table provides a structured overview of all suggestions with key metadata.
|
||||||
|
Users can efficiently prioritize, explore, and implement suggestions through an intuitive workflow.
|
||||||
|
|
||||||
|
The interface guides you from high-level overviews to detailed implementation context.
|
||||||
|
This consistent user-friendly structure streamlines the review process, reducing time from feedback to implementation.
|
||||||
|
|
||||||
|
{width=768}
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### Navigation Instructions
|
||||||
|
Use `↑`/`↓` to navigate suggestions, `Enter` to implement, `Space` for multi-select, and `ESC` to exit.
|
||||||
|
|
||||||
|
The table includes:
|
||||||
|
|
||||||
|
- **Selection** (`○`/`◉`): Multi-selection mode
|
||||||
|
- **Category**: Security, Performance, General, etc.
|
||||||
|
- **Impact**: High, Medium, Low importance
|
||||||
|
- **Suggestion**: Brief description
|
||||||
|
- **Status**: `✓` implemented, `✗` declined, blank = pending
|
||||||
|
- **Detail Panel** (if wide enough): Full suggestion text, affected files, impact analysis
|
||||||
|
|
||||||
|
## Flow
|
||||||
|
|
||||||
|
### Explore the suggestions
|
||||||
|
|
||||||
|
You can explore the suggestions in detail before implementing them.
|
||||||
|
You can view the proposed code changes in a diff format, jump to the relevant code in your IDE, or chat about any suggestion for clarification.
|
||||||
|
|
||||||
|
!!! note "Exploring the suggestions"
|
||||||
|
|
||||||
|
[//]: # ( === "Details Panel")
|
||||||
|
|
||||||
|
[//]: # ()
|
||||||
|
[//]: # ( {width=768})
|
||||||
|
|
||||||
|
[//]: # ( )
|
||||||
|
[//]: # ( **Enhanced Layout (≥120 columns)**)
|
||||||
|
|
||||||
|
[//]: # ( )
|
||||||
|
[//]: # ( - **Detail Panel**: Extended information for selected suggestions)
|
||||||
|
|
||||||
|
[//]: # ( - **File Information**: Affected files and line ranges)
|
||||||
|
|
||||||
|
[//]: # ( - **Complete Description**: Full suggestion explanation)
|
||||||
|
|
||||||
|
[//]: # ( - **Impact Assessment**: Detailed importance analysis)
|
||||||
|
|
||||||
|
=== "Diff View (`D/S`)"
|
||||||
|
=== "Unified Diff View (`D`)"
|
||||||
|
|
||||||
|
{width=768}
|
||||||
|
|
||||||
|
- Press `D` to view proposed code changes
|
||||||
|
- Standard unified diff format with line numbers
|
||||||
|
- Syntax highlighting for additions/removals
|
||||||
|
- `↑`/`↓` to scroll through changes
|
||||||
|
|
||||||
|
=== "Side-by-Side View (`S`)"
|
||||||
|
|
||||||
|
{width=768}
|
||||||
|
|
||||||
|
- Press `S` for side-by-side diff view
|
||||||
|
- Enhanced layout for complex changes
|
||||||
|
- Better context understanding
|
||||||
|
- Clear before/after comparison
|
||||||
|
|
||||||
|
=== "Jump to Code (`O`)"
|
||||||
|
|
||||||
|
**IDE Integration**
|
||||||
|
|
||||||
|
- Press `O` to open the suggestion's source file in your IDE
|
||||||
|
- Supports all major IDEs when terminal is running inside them
|
||||||
|
- Direct navigation to relevant code location
|
||||||
|
- Seamless transition between CLI and editor
|
||||||
|
|
||||||
|
=== "Chat (`C`)"
|
||||||
|
|
||||||
|
**Suggestion-Specific Discussion**
|
||||||
|
|
||||||
|
{width=768}
|
||||||
|
|
||||||
|
- Press `C` to discuss the current suggestion
|
||||||
|
- Context automatically included (files, lines, description)
|
||||||
|
- Ask questions, request modifications
|
||||||
|
- `Ctrl+J` for new lines, `ESC` to return
|
||||||
|
|
||||||
|
|
||||||
|
### Implement
|
||||||
|
|
||||||
|
You can implement a single suggestion, multiple selected suggestions, or all suggestions at once. You can also chat about any suggestion before implementing it.
|
||||||
|
|
||||||
|
!!! note "Multiple implementation modes available"
|
||||||
|
|
||||||
|
=== "1. Single Suggestion"
|
||||||
|
{width=768}
|
||||||
|
|
||||||
|
**Direct individual implementation**
|
||||||
|
|
||||||
|
1. Navigate to any specific suggestion
|
||||||
|
2. Press `Enter` to implement just that suggestion
|
||||||
|
|
||||||
|
=== "2. Multi-Select"
|
||||||
|
{width=768}
|
||||||
|
|
||||||
|
**Select multiple related suggestions**
|
||||||
|
|
||||||
|
1. Use `Space` to select specific suggestions (◉)
|
||||||
|
2. Navigate and select multiple related suggestions
|
||||||
|
3. Press `Enter` on any selected suggestion to start implementation
|
||||||
|
4. AI implements selected suggestions together
|
||||||
|
|
||||||
|
=== "3. Address All"
|
||||||
|
{width=768}
|
||||||
|
|
||||||
|
**Reflect and address all suggestions (Always available as first row)**
|
||||||
|
|
||||||
|
1. Press `Enter` on the first row "Reflect and address all suggestions"
|
||||||
|
2. AI implements all suggestions simultaneously and intelligently
|
||||||
|
3. Handles conflicts and dependencies automatically
|
||||||
|
4. Review the comprehensive summary
|
||||||
|
|
||||||
|
=== "4. Chat then Implement"
|
||||||
|
|
||||||
|
{width=768}
|
||||||
|
|
||||||
|
**Discuss then implement**
|
||||||
|
|
||||||
|
1. Press `C` on any suggestion to start a chat
|
||||||
|
2. Ask questions, request modifications, get clarifications
|
||||||
|
3. Once satisfied, request implementation via chat
|
||||||
|
4. AI implements based on your discussion
|
||||||
|
|
||||||
|
___
|
||||||
|
|
||||||
|
#### Implementation Summary
|
||||||
|
|
||||||
|
After the AI completes the implementation, you receive a **structured output** showing detailed results for each suggestion:
|
||||||
|
|
||||||
|
- **Status**: `✓ IMPLEMENTED`, `SKIPPED`, or `✗ REJECTED`
|
||||||
|
- **Suggestion**: Brief description of what was addressed
|
||||||
|
- **Reasoning**: Explanation of the implementation approach
|
||||||
|
- **Changes**: Summary of code modifications made
|
||||||
|
|
||||||
|
{width=768}
|
||||||
|
|
||||||
|
Each suggestion gets its own implementation summary, providing full transparency into what was done and why.
|
||||||
|
|
||||||
|
### Finalize
|
||||||
|
|
||||||
|
After implementing the suggestions, you have several options to proceed:
|
||||||
|
|
||||||
|
!!! note "Post Implementation Actions"
|
||||||
|
=== "Return to Table (`ESC`)"
|
||||||
|
|
||||||
|
{width=768}
|
||||||
|
|
||||||
|
The first option returns you to the main table where you can see:
|
||||||
|
|
||||||
|
- **Updated Status**: Implemented suggestions now show `✓` green checkmark
|
||||||
|
- **Real-time Updates**: Status changes reflect immediately
|
||||||
|
- **Continue Workflow**: Handle remaining pending suggestions
|
||||||
|
|
||||||
|
=== "Continue Chatting (`C`)"
|
||||||
|
|
||||||
|
{width=768}
|
||||||
|
|
||||||
|
Discuss the implementation details:
|
||||||
|
|
||||||
|
- Review changes made by the AI
|
||||||
|
- Request refinements or modifications
|
||||||
|
- Get explanations of implementation approach
|
||||||
|
- Continuous improvement cycle
|
||||||
|
|
||||||
|
=== "Commit Changes (`M`)"
|
||||||
|
|
||||||
|
{width=512}
|
||||||
|
|
||||||
|
Auto-generate commit messages:
|
||||||
|
|
||||||
|
- AI-generated commit messages based on changes
|
||||||
|
- Editable before committing
|
||||||
|
- Standard git conventions
|
||||||
|
- Seamless workflow integration
|
||||||
|
|
||||||
|
=== "Open Edited File (`O`)"
|
||||||
|
|
||||||
|
Open the implemented code directly in your IDE:
|
||||||
|
|
||||||
|
- View the exact changes made
|
||||||
|
- See implementation in full context
|
||||||
|
- Continue development seamlessly
|
||||||
|
- Integrated with your existing workflow
|
||||||
|
|
||||||
|
## Tips for Success
|
||||||
|
|
||||||
|
- **Start with "Fix All"** to let AI handle everything intelligently
|
||||||
|
- **Use Chat liberally** - ask questions about unclear suggestions
|
||||||
|
- **Decline appropriately** - press `X` and provide reasons for inappropriate suggestions
|
||||||
|
- **Multi-select strategically** - group related suggestions together
|
||||||
|
|
||||||
|
---
|
||||||
|
|
@ -1,23 +1,24 @@
|
||||||
# Recent Updates and Future Roadmap
|
# Recent Updates and Future Roadmap
|
||||||
|
|
||||||
`Page last updated: 2025-06-01`
|
|
||||||
|
|
||||||
This page summarizes recent enhancements to Qodo Merge (last three months).
|
This page summarizes recent enhancements to Qodo Merge.
|
||||||
|
|
||||||
It also outlines our development roadmap for the upcoming three months. Please note that the roadmap is subject to change, and features may be adjusted, added, or reprioritized.
|
It also outlines our development roadmap for the upcoming three months. Please note that the roadmap is subject to change, and features may be adjusted, added, or reprioritized.
|
||||||
|
|
||||||
=== "Recent Updates"
|
=== "Recent Updates"
|
||||||
- **Simplified Free Tier**: Qodo Merge now offers a simplified free tier with a monthly limit of 75 PR reviews per organization, replacing the previous two-week trial. ([Learn more](https://qodo-merge-docs.qodo.ai/installation/qodo_merge/#cloud-users))
|
| Date | Feature | Description |
|
||||||
- **CLI Endpoint**: A new Qodo Merge endpoint that accepts a lists of before/after code changes, executes Qodo Merge commands, and return the results. Currently available for enterprise customers. Contact [Qodo](https://www.qodo.ai/contact/) for more information.
|
|---|---|---|
|
||||||
- **Linear tickets support**: Qodo Merge now supports Linear tickets. ([Learn more](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/#linear-integration))
|
| 2025-09-17 | **Qodo Merge CLI** | A new command-line interface for Qodo Merge, enabling developers to implement code suggestions directly in your terminal. ([Learn more](https://qodo-merge-docs.qodo.ai/qodo-merge-cli/)) |
|
||||||
- **Smart Update**: Upon PR updates, Qodo Merge will offer tailored code suggestions, addressing both the entire PR and the specific incremental changes since the last feedback ([Learn more](https://qodo-merge-docs.qodo.ai/core-abilities/incremental_update//))
|
| 2025-09-12 | **Repo Metadata** | You can now add metadata from files like `AGENTS.md`, which will be applied to all PRs in that repository. ([Learn more](https://qodo-merge-docs.qodo.ai/usage-guide/additional_configurations/#bringing-additional-repository-metadata-to-qodo-merge)) |
|
||||||
- **Qodo Merge Pull Request Benchmark** - evaluating the performance of LLMs in analyzing pull request code ([Learn more](https://qodo-merge-docs.qodo.ai/pr_benchmark/))
|
| 2025-08-11 | **RAG support for GitLab** | All Qodo Merge RAG features are now available in GitLab. ([Learn more](https://qodo-merge-docs.qodo.ai/core-abilities/rag_context_enrichment/)) |
|
||||||
- **Chat on Suggestions**: Users can now chat with code suggestions ([Learn more](https://qodo-merge-docs.qodo.ai/tools/improve/#chat-on-code-suggestions))
|
| 2025-07-29 | **High-level Suggestions** | Qodo Merge now also provides high-level code suggestion for PRs. ([Learn more](https://qodo-merge-docs.qodo.ai/core-abilities/high_level_suggestions/)) |
|
||||||
- **Scan Repo Discussions Tool**: A new tool that analyzes past code discussions to generate a `best_practices.md` file, distilling key insights and recommendations. ([Learn more](https://qodo-merge-docs.qodo.ai/tools/scan_repo_discussions/))
|
| 2025-07-20 | **PR to Ticket** | Generate tickets in your tracking systems based on PR content. ([Learn more](https://qodo-merge-docs.qodo.ai/tools/pr_to_ticket/)) |
|
||||||
|
| 2025-07-17 | **Compliance** | Comprehensive compliance checks for security, ticket requirements, and custom organizational rules. ([Learn more](https://qodo-merge-docs.qodo.ai/tools/compliance/)) |
|
||||||
|
| 2025-06-21 | **Mermaid Diagrams** | Qodo Merge now generates by default Mermaid diagrams for PRs, providing a visual representation of code changes. ([Learn more](https://qodo-merge-docs.qodo.ai/tools/describe/#sequence-diagram-support)) |
|
||||||
|
| 2025-06-11 | **Best Practices Hierarchy** | Introducing support for structured best practices, such as for folders in monorepos or a unified best practice file for a group of repositories. ([Learn more](https://qodo-merge-docs.qodo.ai/tools/improve/#global-hierarchical-best-practices)) |
|
||||||
|
| 2025-06-01 | **CLI Endpoint** | A new Qodo Merge endpoint that accepts a lists of before/after code changes, executes Qodo Merge commands, and return the results. Currently available for enterprise customers. Contact [Qodo](https://www.qodo.ai/contact/) for more information. |
|
||||||
|
|
||||||
=== "Future Roadmap"
|
=== "Future Roadmap"
|
||||||
- **Best Practices Hierarchy**: Introducing support for structured best practices, such as for folders in monorepos or a unified best practice file for a group of repositories.
|
- **`Compliance` tool to replace `review` as default**: Planning to make the `compliance` tool the default automatic command instead of the current `review` tool.
|
||||||
- **Enhanced `review` tool**: Enhancing the `review` tool validate compliance across multiple categories including security, tickets, and custom best practices.
|
|
||||||
- **Smarter context retrieval**: Leverage AST and LSP analysis to gather relevant context from across the entire repository.
|
- **Smarter context retrieval**: Leverage AST and LSP analysis to gather relevant context from across the entire repository.
|
||||||
- **Enhanced portal experience**: Improved user experience in the Qodo Merge portal with new options and capabilities.
|
- **Enhanced portal experience**: Improved user experience in the Qodo Merge portal with new options and capabilities.
|
||||||
|
|
|
||||||
84
docs/docs/summary.md
Normal file
84
docs/docs/summary.md
Normal file
|
|
@ -0,0 +1,84 @@
|
||||||
|
# Table of contents
|
||||||
|
|
||||||
|
* [Overview](index.md)
|
||||||
|
* [💎 Qodo Merge](overview/pr_agent_pro.md)
|
||||||
|
* [Data Privacy](overview/data_privacy.md)
|
||||||
|
|
||||||
|
## Installation
|
||||||
|
|
||||||
|
* [Installation](installation/index.md)
|
||||||
|
* [PR-Agent](installation/pr_agent.md)
|
||||||
|
* [💎 Qodo Merge](installation/qodo_merge.md)
|
||||||
|
|
||||||
|
## Usage Guide
|
||||||
|
|
||||||
|
* [Usage Guide](usage-guide/index.md)
|
||||||
|
* [Introduction](usage-guide/introduction.md)
|
||||||
|
* [Enabling a Wiki](usage-guide/enabling_a_wiki.md)
|
||||||
|
* [Configuration File](usage-guide/configuration_options.md)
|
||||||
|
* [Usage and Automation](usage-guide/automations_and_usage.md)
|
||||||
|
* [Managing Mail Notifications](usage-guide/mail_notifications.md)
|
||||||
|
* [Changing a Model](usage-guide/changing_a_model.md)
|
||||||
|
* [Additional Configurations](usage-guide/additional_configurations.md)
|
||||||
|
* [Frequently Asked Questions](faq/index.md)
|
||||||
|
* [Qodo Merge Models](usage-guide/qodo_merge_models.md)
|
||||||
|
|
||||||
|
## Tools
|
||||||
|
|
||||||
|
* [Tools](tools/index.md)
|
||||||
|
* [Describe](tools/describe.md)
|
||||||
|
* [Review](tools/review.md)
|
||||||
|
* [Improve](tools/improve.md)
|
||||||
|
* [Ask](tools/ask.md)
|
||||||
|
* [Help](tools/help.md)
|
||||||
|
* [Help Docs](tools/help_docs.md)
|
||||||
|
* [Update Changelog](tools/update_changelog.md)
|
||||||
|
* [💎 Add Documentation](tools/documentation.md)
|
||||||
|
* [💎 Analyze](tools/analyze.md)
|
||||||
|
* [💎 CI Feedback](tools/ci_feedback.md)
|
||||||
|
* [💎 Compliance](tools/compliance.md)
|
||||||
|
* [💎 Custom Prompt](tools/custom_prompt.md)
|
||||||
|
* [💎 Generate Labels](tools/custom_labels.md)
|
||||||
|
* [💎 Generate Tests](tools/test.md)
|
||||||
|
* [💎 Implement](tools/implement.md)
|
||||||
|
* [💎 Improve Components](tools/improve_component.md)
|
||||||
|
* [💎 PR to Ticket](tools/pr_to_ticket.md)
|
||||||
|
* [💎 Scan Repo Discussions](tools/scan_repo_discussions.md)
|
||||||
|
* [💎 Similar Code](tools/similar_code.md)
|
||||||
|
|
||||||
|
## Core Abilities
|
||||||
|
|
||||||
|
* [Core Abilities](core-abilities/index.md)
|
||||||
|
* [Auto approval](core-abilities/auto_approval.md)
|
||||||
|
* [Auto best practices](core-abilities/auto_best_practices.md)
|
||||||
|
* [Chat on code suggestions](core-abilities/chat_on_code_suggestions.md)
|
||||||
|
* [Chrome extension](chrome-extension/index.md)
|
||||||
|
* [Code validation](core-abilities/code_validation.md)
|
||||||
|
* [Dynamic context](core-abilities/dynamic_context.md)
|
||||||
|
* [Fetching ticket context](core-abilities/fetching_ticket_context.md)
|
||||||
|
* [High-level Suggestions](core-abilities/high_level_suggestions.md)
|
||||||
|
* [Impact evaluation](core-abilities/impact_evaluation.md)
|
||||||
|
* [Incremental Update](core-abilities/incremental_update.md)
|
||||||
|
* [Interactivity](core-abilities/interactivity.md)
|
||||||
|
* [Local and global metadata](core-abilities/metadata.md)
|
||||||
|
* [RAG context enrichment](core-abilities/rag_context_enrichment.md)
|
||||||
|
* [Self-reflection](core-abilities/self_reflection.md)
|
||||||
|
* [Static code analysis](core-abilities/static_code_analysis.md)
|
||||||
|
|
||||||
|
## Qodo Merge CLI
|
||||||
|
|
||||||
|
* [Overview](qodo-merge-cli/index.md)
|
||||||
|
* [Installation](qodo-merge-cli/installation.md)
|
||||||
|
* [Usage](qodo-merge-cli/usage.md)
|
||||||
|
|
||||||
|
## PR Benchmark
|
||||||
|
|
||||||
|
* [PR Benchmark](pr_benchmark/index.md)
|
||||||
|
|
||||||
|
## Recent Updates
|
||||||
|
|
||||||
|
* [Recent Updates](recent_updates/index.md)
|
||||||
|
|
||||||
|
## AI Docs Search
|
||||||
|
|
||||||
|
* [AI Docs Search](ai_search/index.md)
|
||||||
|
|
@ -16,5 +16,5 @@ An example result:
|
||||||
|
|
||||||
{width=750}
|
{width=750}
|
||||||
|
|
||||||
!!! note "Language that are currently supported:"
|
!!! note "Languages that are currently supported:"
|
||||||
Python, Java, C++, JavaScript, TypeScript, C#, Go.
|
Python, Java, C++, JavaScript, TypeScript, C#, Go, Kotlin
|
||||||
|
|
|
||||||
375
docs/docs/tools/compliance.md
Normal file
375
docs/docs/tools/compliance.md
Normal file
|
|
@ -0,0 +1,375 @@
|
||||||
|
`Platforms supported: GitHub, GitLab, Bitbucket`
|
||||||
|
|
||||||
|
## Overview
|
||||||
|
|
||||||
|
The `compliance` tool performs comprehensive compliance checks on PR code changes, validating them against security standards, ticket requirements, and custom organizational compliance checklists, thereby helping teams, enterprises, and agents maintain consistent code quality and security practices while ensuring that development work aligns with business requirements.
|
||||||
|
|
||||||
|
=== "Fully Compliant"
|
||||||
|
{width=512}
|
||||||
|
|
||||||
|
=== "Partially Compliant"
|
||||||
|
{width=512}
|
||||||
|
|
||||||
|
___
|
||||||
|
|
||||||
|
[//]: # (???+ note "The following features are available only for Qodo Merge 💎 users:")
|
||||||
|
|
||||||
|
[//]: # ( - Custom compliance checklists and hierarchical compliance checklists)
|
||||||
|
|
||||||
|
[//]: # ( - Ticket compliance validation with Jira/Linear integration)
|
||||||
|
|
||||||
|
[//]: # ( - Auto-approval based on compliance status)
|
||||||
|
|
||||||
|
[//]: # ( - Compliance labels and automated enforcement)
|
||||||
|
|
||||||
|
## Example Usage
|
||||||
|
|
||||||
|
### Manual Triggering
|
||||||
|
|
||||||
|
Invoke the tool manually by commenting `/compliance` on any PR. The compliance results are presented in a comprehensive table:
|
||||||
|
|
||||||
|
To edit [configurations](#configuration-options) related to the `compliance` tool, use the following template:
|
||||||
|
|
||||||
|
```toml
|
||||||
|
/compliance --pr_compliance.some_config1=... --pr_compliance.some_config2=...
|
||||||
|
```
|
||||||
|
|
||||||
|
For example, you can enable ticket compliance labels by running:
|
||||||
|
|
||||||
|
```toml
|
||||||
|
/compliance --pr_compliance.enable_ticket_labels=true
|
||||||
|
```
|
||||||
|
|
||||||
|
### Automatic Triggering
|
||||||
|
|
||||||
|
|
||||||
|
The tool can be triggered automatically every time a new PR is [opened](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#github-app-automatic-tools-when-a-new-pr-is-opened), or in a [push](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/?h=push#github-app-automatic-tools-for-push-actions-commits-to-an-open-pr) event to an existing PR.
|
||||||
|
|
||||||
|
To run the `compliance` tool automatically when a PR is opened, define the following in the [configuration file](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/):
|
||||||
|
|
||||||
|
```toml
|
||||||
|
[github_app] # for example
|
||||||
|
pr_commands = [
|
||||||
|
"/compliance",
|
||||||
|
...
|
||||||
|
]
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
## Compliance Categories
|
||||||
|
|
||||||
|
The compliance tool evaluates three main categories:
|
||||||
|
|
||||||
|
|
||||||
|
### 1. Security Compliance
|
||||||
|
|
||||||
|
Scans for security vulnerabilities and potential exploits in the PR code changes:
|
||||||
|
|
||||||
|
- **Verified Security Concerns** 🔴: Clear security vulnerabilities that require immediate attention
|
||||||
|
- **Possible Security Risks** ⚪: Potential security issues that need human verification
|
||||||
|
- **No Security Concerns** 🟢: No security vulnerabilities detected
|
||||||
|
|
||||||
|
Examples of security issues:
|
||||||
|
|
||||||
|
- Exposure of sensitive information (API keys, passwords, secrets)
|
||||||
|
- SQL injection vulnerabilities
|
||||||
|
- Cross-site scripting (XSS) risks
|
||||||
|
- Cross-site request forgery (CSRF) vulnerabilities
|
||||||
|
- Insecure data handling patterns
|
||||||
|
|
||||||
|
|
||||||
|
### 2. Ticket Compliance
|
||||||
|
|
||||||
|
???+ tip "How to set up ticket compliance"
|
||||||
|
Follow the guide on how to set up [ticket compliance](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/) with Qodo Merge.
|
||||||
|
|
||||||
|
???+ tip "Auto-create ticket"
|
||||||
|
Follow this [guide](https://qodo-merge-docs.qodo.ai/tools/pr_to_ticket/) to learn how to enable triggering `create tickets` based on PR content.
|
||||||
|
|
||||||
|
{width=256}
|
||||||
|
|
||||||
|
|
||||||
|
Validates that PR changes fulfill the requirements specified in linked tickets:
|
||||||
|
|
||||||
|
- **Fully Compliant** 🟢: All ticket requirements are satisfied
|
||||||
|
- **Partially Compliant** 🟡: Some requirements are met, others need attention
|
||||||
|
- **Not Compliant** 🔴: Clear violations of ticket requirements
|
||||||
|
- **Requires Verification** ⚪: Requirements that need human review
|
||||||
|
|
||||||
|
|
||||||
|
### 3. RAG Code Duplication Compliance
|
||||||
|
|
||||||
|
???+ tip "Learn more about RAG"
|
||||||
|
For detailed information about RAG context enrichment, see the [RAG Context Enrichment guide](../core-abilities/rag_context_enrichment.md).
|
||||||
|
|
||||||
|
Analyzes code changes using RAG endpoint to detect potential code duplication from the codebase:
|
||||||
|
|
||||||
|
- **Fully Compliant** 🟢: No code duplication found
|
||||||
|
- **Not Compliant** 🔴: Full code duplication found
|
||||||
|
- **Requires Verification** ⚪: Near code duplication
|
||||||
|
|
||||||
|
|
||||||
|
### 4. Custom Compliance
|
||||||
|
|
||||||
|
Validates against an organization-specific compliance checklist:
|
||||||
|
|
||||||
|
- **Fully Compliant** 🟢: All custom compliance are satisfied
|
||||||
|
- **Not Compliant** 🔴: Violations of custom compliance
|
||||||
|
- **Requires Verification** ⚪: Compliance that need human assessment
|
||||||
|
|
||||||
|
## Custom Compliance
|
||||||
|
|
||||||
|
### Setting Up Custom Compliance
|
||||||
|
|
||||||
|
Each compliance is defined in a YAML file as follows:
|
||||||
|
|
||||||
|
- `title` (required): A clear, descriptive title that identifies what is being checked
|
||||||
|
- `compliance_label` (required): Determines whether this compliance generates labels for non-compliance issues (set to `true` or `false`)
|
||||||
|
- `objective` (required): A detailed description of the goal or purpose this compliance aims to achieve
|
||||||
|
- `success_criteria` and `failure_criteria` (at least one required; both recommended): Define the conditions for compliance
|
||||||
|
|
||||||
|
|
||||||
|
???+ tip "Example of a compliance checklist"
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
# pr_compliance_checklist.yaml
|
||||||
|
pr_compliances:
|
||||||
|
- title: "Error Handling"
|
||||||
|
compliance_label: true
|
||||||
|
objective: "All external API calls must have proper error handling"
|
||||||
|
success_criteria: "Try-catch blocks around external calls with appropriate logging"
|
||||||
|
failure_criteria: "External API calls without error handling or logging"
|
||||||
|
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
???+ tip "Writing effective compliance checklists"
|
||||||
|
- Avoid overly complex or subjective compliances that are hard to verify
|
||||||
|
- Keep compliances focused on security, business requirements, and critical standards
|
||||||
|
- Use clear, actionable language that developers can understand
|
||||||
|
- Focus on meaningful compliance requirements, not style preferences
|
||||||
|
|
||||||
|
???+ tip "Ready-to-use compliance templates"
|
||||||
|
For production-ready compliance checklist templates organized by programming languages and technology stacks, check out the [PR Compliance Templates repository](https://github.com/qodo-ai/pr-compliance-templates).
|
||||||
|
|
||||||
|
### Local Compliance Checklists
|
||||||
|
|
||||||
|
For basic usage, create a `pr_compliance_checklist.yaml` file in your repository's root directory containing the compliance requirements specific to your repository.
|
||||||
|
|
||||||
|
The AI model will use this `pr_compliance_checklist.yaml` file as a reference, and if the PR code violates any of the compliance requirements, it will be shown in the compliance tool's comment.
|
||||||
|
|
||||||
|
### Global Hierarchical Compliance
|
||||||
|
|
||||||
|
Qodo Merge supports hierarchical compliance checklists using a dedicated global configuration repository.
|
||||||
|
|
||||||
|
#### Setting up global hierarchical compliance
|
||||||
|
|
||||||
|
1\. Create a new repository named `pr-agent-settings` in your organization or workspace.
|
||||||
|
|
||||||
|
2\. Build the folder hierarchy in your `pr-agent-settings` repository:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pr-agent-settings/
|
||||||
|
├── metadata.yaml # Maps repos/folders to compliance paths
|
||||||
|
└── codebase_standards/ # Root for all compliance definitions
|
||||||
|
├── global/ # Global compliance, inherited widely
|
||||||
|
│ └── pr_compliance_checklist.yaml
|
||||||
|
├── groups/ # For groups of repositories
|
||||||
|
│ ├── frontend_repos/
|
||||||
|
│ │ └── pr_compliance_checklist.yaml
|
||||||
|
│ ├── backend_repos/
|
||||||
|
│ │ └── pr_compliance_checklist.yaml
|
||||||
|
│ ├── python_repos/
|
||||||
|
│ │ └── pr_compliance_checklist.yaml
|
||||||
|
│ ├── cpp_repos/
|
||||||
|
│ │ └── pr_compliance_checklist.yaml
|
||||||
|
│ └── ...
|
||||||
|
├── repo_a/ # For standalone repositories
|
||||||
|
│ └── pr_compliance_checklist.yaml
|
||||||
|
├── monorepo-name/ # For monorepo-specific compliance
|
||||||
|
│ ├── pr_compliance_checklist.yaml # Root-level monorepo compliance
|
||||||
|
│ ├── service-a/ # Subproject compliance
|
||||||
|
│ │ └── pr_compliance_checklist.yaml
|
||||||
|
│ └── service-b/ # Another subproject
|
||||||
|
│ └── pr_compliance_checklist.yaml
|
||||||
|
└── ... # More repositories
|
||||||
|
```
|
||||||
|
|
||||||
|
> **Note:** In this structure, `pr-agent-settings`, `codebase_standards`, `global`, `groups`, `metadata.yaml`, and `pr_compliance_checklist.yaml` are hardcoded names that must be used exactly as shown. All other names (such as `frontend_repos`, `backend_repos`, `repo_a`, `monorepo-name`, `service-a`, etc.) are examples and should be replaced with your actual repository and service names.
|
||||||
|
|
||||||
|
???+ tip "Grouping and categorizing compliance checklists"
|
||||||
|
- Each folder (including the global folder) can contain a single `pr_compliance_checklist.yaml` file
|
||||||
|
- Organize repository compliance checklists by creating subfolders within the `groups` folder. Group them by purpose, programming languages, or other categories
|
||||||
|
|
||||||
|
3\. Define the metadata file `metadata.yaml` in the root of `pr-agent-settings`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
# Standalone repos
|
||||||
|
repo_a:
|
||||||
|
pr_compliance_checklist_paths:
|
||||||
|
- "repo_a"
|
||||||
|
|
||||||
|
# Group-associated repos
|
||||||
|
repo_b:
|
||||||
|
pr_compliance_checklist_paths:
|
||||||
|
- "groups/backend_repos"
|
||||||
|
|
||||||
|
# Multi-group repos
|
||||||
|
repo_c:
|
||||||
|
pr_compliance_checklist_paths:
|
||||||
|
- "groups/frontend_repos"
|
||||||
|
- "groups/backend_repos"
|
||||||
|
|
||||||
|
# Monorepo with subprojects
|
||||||
|
monorepo-name:
|
||||||
|
pr_compliance_checklist_paths:
|
||||||
|
- "monorepo-name"
|
||||||
|
monorepo_subprojects:
|
||||||
|
service-a:
|
||||||
|
pr_compliance_checklist_paths:
|
||||||
|
- "monorepo-name/service-a"
|
||||||
|
service-b:
|
||||||
|
pr_compliance_checklist_paths:
|
||||||
|
- "monorepo-name/service-b"
|
||||||
|
```
|
||||||
|
|
||||||
|
4\. Set the following configuration:
|
||||||
|
|
||||||
|
```toml
|
||||||
|
[pr_compliance]
|
||||||
|
enable_global_pr_compliance = true
|
||||||
|
```
|
||||||
|
|
||||||
|
???- info "Compliance checklist loading strategy"
|
||||||
|
|
||||||
|
1. **Global Checklists**: Hierarchical compliance from `pr-agent-settings` repository
|
||||||
|
|
||||||
|
1.1 If the repository is mapped in `metadata.yaml`, it uses the specified paths and the global compliance checklist
|
||||||
|
|
||||||
|
1.2 For monorepos, it automatically collects compliance checklists matching PR file paths
|
||||||
|
|
||||||
|
1.3 If the repository is not mapped in `metadata.yaml`, global checklists are not loaded
|
||||||
|
|
||||||
|
2. **Local Repository Checklist**: `pr_compliance_checklist.yaml` file in the repository
|
||||||
|
|
||||||
|
2.1 Loaded if present in the repository
|
||||||
|
|
||||||
|
2.2 Content is merged with global checklists (if loaded) to create the final compliance checklist
|
||||||
|
|
||||||
|
|
||||||
|
## Configuration Options
|
||||||
|
|
||||||
|
???+ example "General options"
|
||||||
|
|
||||||
|
<table>
|
||||||
|
<tr>
|
||||||
|
<td><b>extra_instructions</b></td>
|
||||||
|
<td>Optional extra instructions for the tool. For example: "Ensure that all error-handling paths in the code contain appropriate logging statements". Default is empty string.</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td><b>persistent_comment</b></td>
|
||||||
|
<td>If set to true, the compliance comment will be persistent, meaning that every new compliance request will edit the previous one. Default is true.</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td><b>enable_user_defined_compliance_labels</b></td>
|
||||||
|
<td>If set to true, the tool will add the label `Failed compliance check` for custom compliance violations. Default is true.</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td><b>enable_estimate_effort_to_review</b></td>
|
||||||
|
<td>If set to true, the tool will estimate the effort required to review the PR (1-5 scale) as a label. Default is true.</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td><b>enable_todo_scan</b></td>
|
||||||
|
<td>If set to true, the tool will scan for TODO comments in the PR code. Default is false.</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td><b>enable_update_pr_compliance_checkbox</b></td>
|
||||||
|
<td>If set to true, the tool will add an update checkbox to refresh compliance status following push events. Default is true.</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td><b>enable_help_text</b></td>
|
||||||
|
<td>If set to true, the tool will display help text in the comment. Default is false.</td>
|
||||||
|
</tr>
|
||||||
|
</table>
|
||||||
|
|
||||||
|
???+ example "Section visibility options"
|
||||||
|
|
||||||
|
<table>
|
||||||
|
<tr>
|
||||||
|
<td><b>enable_security_section</b></td>
|
||||||
|
<td>If set to true, the security compliance section will be displayed in the output. When false, the entire security section is hidden. Default is true.</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td><b>enable_ticket_section</b></td>
|
||||||
|
<td>If set to true, the ticket compliance section will be displayed in the output. When false, the entire ticket section is hidden. Default is true.</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td><b>enable_codebase_duplication_section</b></td>
|
||||||
|
<td>If set to true, the codebase duplication compliance section will be displayed in the output. When false, the entire codebase duplication section is hidden. Default is true.</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td><b>enable_custom_compliance_section</b></td>
|
||||||
|
<td>If set to true, the custom compliance section will be displayed in the output. When false, the entire custom section is hidden. Default is true.</td>
|
||||||
|
</tr>
|
||||||
|
</table>
|
||||||
|
|
||||||
|
???+ example "Security compliance options"
|
||||||
|
|
||||||
|
<table>
|
||||||
|
<tr>
|
||||||
|
<td><b>enable_security_compliance</b></td>
|
||||||
|
<td>If set to true, the tool will check for security vulnerabilities. Default is true.</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td><b>enable_compliance_labels_security</b></td>
|
||||||
|
<td>If set to true, the tool will add a `Possible security concern` label to the PR when security-related concerns are detected. Default is true.</td>
|
||||||
|
</tr>
|
||||||
|
</table>
|
||||||
|
|
||||||
|
???+ example "Ticket compliance options"
|
||||||
|
|
||||||
|
<table>
|
||||||
|
<tr>
|
||||||
|
<td><b>require_ticket_analysis_review</b></td>
|
||||||
|
<td>If set to true, the tool will fetch and analyze ticket context for compliance validation. Default is true.</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td><b>enable_ticket_labels</b></td>
|
||||||
|
<td>If set to true, the tool will add ticket compliance labels to the PR. Default is false.</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td><b>enable_no_ticket_labels</b></td>
|
||||||
|
<td>If set to true, the tool will add a label when no ticket is found. Default is false.</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td><b>check_pr_additional_content</b></td>
|
||||||
|
<td>If set to true, the tool will check if the PR contains content not related to the ticket. Default is false.</td>
|
||||||
|
</tr>
|
||||||
|
</table>
|
||||||
|
|
||||||
|
???+ example "Generic custom compliance checklist options"
|
||||||
|
|
||||||
|
<table>
|
||||||
|
<tr>
|
||||||
|
<td><b>enable_generic_custom_compliance_checklist</b></td>
|
||||||
|
<td>If set to true, the tool will apply generic custom compliance checklist rules. Default is true.</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td><b>persist_generic_custom_compliance_checklist</b></td>
|
||||||
|
<td>If set to false, generic compliance checklist will not be kept with custom compliance. Default is false.</td>
|
||||||
|
</tr>
|
||||||
|
</table>
|
||||||
|
|
||||||
|
|
||||||
|
## Usage Tips
|
||||||
|
|
||||||
|
### Blocking PRs Based on Compliance
|
||||||
|
|
||||||
|
!!! tip ""
|
||||||
|
You can configure CI/CD Actions to prevent merging PRs with specific compliance labels:
|
||||||
|
|
||||||
|
- `Possible security concern` - Block PRs with potential security issues
|
||||||
|
- `Failed compliance check` - Block PRs that violate custom compliance checklists
|
||||||
|
|
||||||
|
Implement a dedicated [GitHub Action](https://medium.com/sequra-tech/quick-tip-block-pull-request-merge-using-labels-6cc326936221) to enforce these checklists.
|
||||||
|
|
||||||
|
|
@ -1,3 +1,5 @@
|
||||||
|
`Platforms supported: GitHub, GitLab`
|
||||||
|
|
||||||
## Overview
|
## Overview
|
||||||
|
|
||||||
The `generate_labels` tool scans the PR code changes, and given a list of labels and their descriptions, it automatically suggests labels that match the PR code changes.
|
The `generate_labels` tool scans the PR code changes, and given a list of labels and their descriptions, it automatically suggests labels that match the PR code changes.
|
||||||
|
|
@ -66,3 +68,7 @@ description = "Description of when AI should suggest this label"
|
||||||
[custom_labels."Custom Label 2"]
|
[custom_labels."Custom Label 2"]
|
||||||
description = "Description of when AI should suggest this label 2"
|
description = "Description of when AI should suggest this label 2"
|
||||||
```
|
```
|
||||||
|
|
||||||
|
???+ tip "Auto-remove custom label when no longer relevant"
|
||||||
|
If the custom label is no longer relevant, it will be automatically removed from the PR by running the `generate_labels` tool or the `describe` tool.
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -47,29 +47,41 @@ publish_labels = true
|
||||||
|
|
||||||
## Preserving the original user description
|
## Preserving the original user description
|
||||||
|
|
||||||
By default, Qodo Merge preserves your original PR description by placing it above the generated content.
|
By default, Qodo Merge tries to preserve your original PR description by placing it above the generated content.
|
||||||
This requires including your description during the initial PR creation.
|
This requires including your description during the initial PR creation.
|
||||||
Be aware that if you edit the description while the automated tool is running, a race condition may occur, potentially causing your original description to be lost.
|
|
||||||
|
|
||||||
When updating PR descriptions, the `/describe` tool considers everything above the "PR Type" field as user content and will preserve it.
|
"Qodo removed the original description from the PR. Why"?
|
||||||
|
|
||||||
|
From our experience, there are two possible reasons:
|
||||||
|
|
||||||
|
- If you edit the description _while_ the automated tool is running, a race condition may occur, potentially causing your original description to be lost. Hence, create a description before launching the PR.
|
||||||
|
|
||||||
|
- When _updating_ PR descriptions, the `/describe` tool considers everything above the "PR Type" field as user content and will preserve it.
|
||||||
Everything below this marker is treated as previously auto-generated content and will be replaced.
|
Everything below this marker is treated as previously auto-generated content and will be replaced.
|
||||||
|
|
||||||
{width=512}
|
{width=512}
|
||||||
|
|
||||||
### Sequence Diagram Support
|
## Sequence Diagram Support
|
||||||
When the `enable_pr_diagram` option is enabled in your configuration, the `/describe` tool will include a `Mermaid` sequence diagram in the PR description.
|
The `/describe` tool includes a Mermaid sequence diagram showing component/function interactions.
|
||||||
|
|
||||||
This diagram represents interactions between components/functions based on the diff content.
|
This option is enabled by default via the `pr_description.enable_pr_diagram` param.
|
||||||
|
|
||||||
### How to enable
|
|
||||||
|
|
||||||
In your configuration:
|
[//]: # (### How to enable\disable)
|
||||||
|
|
||||||
```
|
[//]: # ()
|
||||||
toml
|
[//]: # (In your configuration:)
|
||||||
[pr_description]
|
|
||||||
enable_pr_diagram = true
|
[//]: # ()
|
||||||
```
|
[//]: # (```)
|
||||||
|
|
||||||
|
[//]: # (toml)
|
||||||
|
|
||||||
|
[//]: # ([pr_description])
|
||||||
|
|
||||||
|
[//]: # (enable_pr_diagram = true)
|
||||||
|
|
||||||
|
[//]: # (```)
|
||||||
|
|
||||||
## Configuration options
|
## Configuration options
|
||||||
|
|
||||||
|
|
@ -106,19 +118,23 @@ enable_pr_diagram = true
|
||||||
</tr>
|
</tr>
|
||||||
<tr>
|
<tr>
|
||||||
<td><b>final_update_message</b></td>
|
<td><b>final_update_message</b></td>
|
||||||
<td>If set to true, it will add a comment message [`PR Description updated to latest commit...`](https://github.com/Codium-ai/pr-agent/pull/499#issuecomment-1837412176) after finishing calling `/describe`. Default is false.</td>
|
<td>If set to true, it will add a comment message [`PR Description updated to latest commit...`](https://github.com/Codium-ai/pr-agent/pull/499#issuecomment-1837412176) after finishing calling `/describe`. Default is true.</td>
|
||||||
</tr>
|
</tr>
|
||||||
<tr>
|
<tr>
|
||||||
<td><b>enable_semantic_files_types</b></td>
|
<td><b>enable_semantic_files_types</b></td>
|
||||||
<td>If set to true, "Changes walkthrough" section will be generated. Default is true.</td>
|
<td>If set to true, "Changes walkthrough" section will be generated. Default is true.</td>
|
||||||
</tr>
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td><b>file_table_collapsible_open_by_default</b></td>
|
||||||
|
<td>If set to true, the file list in the "Changes walkthrough" section will be open by default. If set to false, it will be closed by default. Default is false.</td>
|
||||||
|
</tr>
|
||||||
<tr>
|
<tr>
|
||||||
<td><b>collapsible_file_list</b></td>
|
<td><b>collapsible_file_list</b></td>
|
||||||
<td>If set to true, the file list in the "Changes walkthrough" section will be collapsible. If set to "adaptive", the file list will be collapsible only if there are more than 8 files. Default is "adaptive".</td>
|
<td>If set to true, the file list in the "Changes walkthrough" section will be collapsible. If set to "adaptive", the file list will be collapsible only if there are more than 8 files. Default is "adaptive".</td>
|
||||||
</tr>
|
</tr>
|
||||||
<tr>
|
<tr>
|
||||||
<td><b>enable_large_pr_handling</b></td>
|
<td><b>enable_large_pr_handling 💎</b></td>
|
||||||
<td>Pro feature. If set to true, in case of a large PR the tool will make several calls to the AI and combine them to be able to cover more files. Default is true.</td>
|
<td>If set to true, in case of a large PR the tool will make several calls to the AI and combine them to be able to cover more files. Default is true.</td>
|
||||||
</tr>
|
</tr>
|
||||||
<tr>
|
<tr>
|
||||||
<td><b>enable_help_text</b></td>
|
<td><b>enable_help_text</b></td>
|
||||||
|
|
@ -126,7 +142,11 @@ enable_pr_diagram = true
|
||||||
</tr>
|
</tr>
|
||||||
<tr>
|
<tr>
|
||||||
<td><b>enable_pr_diagram</b></td>
|
<td><b>enable_pr_diagram</b></td>
|
||||||
<td>If set to true, the tool will generate a horizontal Mermaid flowchart summarizing the main pull request changes. This field remains empty if not applicable. Default is false.</td>
|
<td>If set to true, the tool will generate a horizontal Mermaid flowchart summarizing the main pull request changes. This field remains empty if not applicable. Default is true.</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td><b>auto_create_ticket</b></td>
|
||||||
|
<td>If set to true, this will <a href="https://qodo-merge-docs.qodo.ai/tools/pr_to_ticket/">automatically create a ticket</a> in the ticketing system when a PR is opened. Default is false.</td>
|
||||||
</tr>
|
</tr>
|
||||||
</table>
|
</table>
|
||||||
|
|
||||||
|
|
@ -170,9 +190,12 @@ pr_agent:summary
|
||||||
|
|
||||||
## PR Walkthrough:
|
## PR Walkthrough:
|
||||||
pr_agent:walkthrough
|
pr_agent:walkthrough
|
||||||
|
|
||||||
|
## PR Diagram:
|
||||||
|
pr_agent:diagram
|
||||||
```
|
```
|
||||||
|
|
||||||
The marker `pr_agent:type` will be replaced with the PR type, `pr_agent:summary` will be replaced with the PR summary, and `pr_agent:walkthrough` will be replaced with the PR walkthrough.
|
The marker `pr_agent:type` will be replaced with the PR type, `pr_agent:summary` will be replaced with the PR summary, `pr_agent:walkthrough` will be replaced with the PR walkthrough, and `pr_agent:diagram` will be replaced with the sequence diagram (if enabled).
|
||||||
|
|
||||||
{width=512}
|
{width=512}
|
||||||
|
|
||||||
|
|
@ -184,6 +207,7 @@ becomes
|
||||||
|
|
||||||
- `use_description_markers`: if set to true, the tool will use markers template. It replaces every marker of the form `pr_agent:marker_name` with the relevant content. Default is false.
|
- `use_description_markers`: if set to true, the tool will use markers template. It replaces every marker of the form `pr_agent:marker_name` with the relevant content. Default is false.
|
||||||
- `include_generated_by_header`: if set to true, the tool will add a dedicated header: 'Generated by PR Agent at ...' to any automatic content. Default is true.
|
- `include_generated_by_header`: if set to true, the tool will add a dedicated header: 'Generated by PR Agent at ...' to any automatic content. Default is true.
|
||||||
|
- `diagram`: if present as a marker, will be replaced by the PR sequence diagram (if enabled).
|
||||||
|
|
||||||
## Custom labels
|
## Custom labels
|
||||||
|
|
||||||
|
|
@ -195,6 +219,10 @@ Custom labels can be defined in a [configuration file](https://qodo-merge-docs.q
|
||||||
Make sure to provide proper title, and a detailed and well-phrased description for each label, so the tool will know when to suggest it.
|
Make sure to provide proper title, and a detailed and well-phrased description for each label, so the tool will know when to suggest it.
|
||||||
Each label description should be a **conditional statement**, that indicates if to add the label to the PR or not, according to the PR content.
|
Each label description should be a **conditional statement**, that indicates if to add the label to the PR or not, according to the PR content.
|
||||||
|
|
||||||
|
???+ tip "Auto-remove custom label when no longer relevant"
|
||||||
|
If the custom label is no longer relevant, it will be automatically removed from the PR by running the `generate_labels` tool or the `describe` tool.
|
||||||
|
|
||||||
|
|
||||||
### Handle custom labels from a configuration file
|
### Handle custom labels from a configuration file
|
||||||
|
|
||||||
Example for a custom labels configuration setup in a configuration file:
|
Example for a custom labels configuration setup in a configuration file:
|
||||||
|
|
|
||||||
|
|
@ -52,5 +52,5 @@ Since this is under the [github_app] section, it only applies when using the Qod
|
||||||
- `extra_instructions`: Optional extra instructions to the tool. For example: "focus on the changes in the file X. Ignore change in ...".
|
- `extra_instructions`: Optional extra instructions to the tool. For example: "focus on the changes in the file X. Ignore change in ...".
|
||||||
|
|
||||||
!!! note "Notes"
|
!!! note "Notes"
|
||||||
- The following languages are currently supported: Python, Java, C++, JavaScript, TypeScript, C#.
|
- The following languages are currently supported: `Python, Java, C++, JavaScript, TypeScript, C#, Go, Ruby, PHP, Rust, Kotlin, Scala`
|
||||||
- This tool can also be triggered interactively by using the [`analyze`](./analyze.md) tool.
|
- This tool can also be triggered interactively by using the [`analyze`](./analyze.md) tool.
|
||||||
|
|
|
||||||
|
|
@ -11,10 +11,11 @@ It can be invoked manually by commenting on any PR:
|
||||||
|
|
||||||
## Example usage
|
## Example usage
|
||||||
|
|
||||||
An example [result](https://github.com/Codium-ai/pr-agent/pull/546#issuecomment-1868524805):
|
Invoke the `help` tool by commenting on a PR with:
|
||||||
|
|
||||||
{width=750}
|
{width=750}
|
||||||
|
|
||||||
→
|
|
||||||
|
|
||||||
{width=750}
|
Response will include a list of available tools:
|
||||||
|
|
||||||
|
{width=750}
|
||||||
|
|
|
||||||
|
|
@ -86,10 +86,11 @@ jobs:
|
||||||
-c "cd /app && \
|
-c "cd /app && \
|
||||||
echo 'Running Issue Agent action step on ISSUE_URL=$ISSUE_URL' && \
|
echo 'Running Issue Agent action step on ISSUE_URL=$ISSUE_URL' && \
|
||||||
export config__git_provider='github' && \
|
export config__git_provider='github' && \
|
||||||
export github__user_token=$GITHUB_TOKEN && \
|
export github__user_token=$GITHUB_TOKEN && \
|
||||||
export github__base_url=$GITHUB_API_URL && \
|
export github__base_url=$GITHUB_API_URL && \
|
||||||
export openai__key=$OPENAI_KEY && \
|
export openai__key=$OPENAI_KEY && \
|
||||||
python -m pr_agent.cli --issue_url=$ISSUE_URL --pr_help_docs.repo_url="..." --pr_help_docs.docs_path="..." --pr_help_docs.openai_key=$OPENAI_KEY && \help_docs \"$ISSUE_BODY\""
|
python -m pr_agent.cli --issue_url=$ISSUE_URL --pr_help_docs.repo_url="..." --pr_help_docs.docs_path="..." --pr_help_docs.openai_key=$OPENAI_KEY && \
|
||||||
|
help_docs "$ISSUE_BODY"
|
||||||
```
|
```
|
||||||
|
|
||||||
3) Following completion of the remaining steps (such as adding secrets and relevant configurations, such as `repo_url` and `docs_path`) merge this change to your main branch.
|
3) Following completion of the remaining steps (such as adding secrets and relevant configurations, such as `repo_url` and `docs_path`) merge this change to your main branch.
|
||||||
|
|
|
||||||
|
|
@ -43,7 +43,7 @@ It leverages LLM technology to transform PR comments and review suggestions into
|
||||||
You can reference and implement changes from any comment by:
|
You can reference and implement changes from any comment by:
|
||||||
|
|
||||||
```
|
```
|
||||||
/implement <link-to-review-comment>
|
/implement <link-to-an-inline-comment>
|
||||||
```
|
```
|
||||||
|
|
||||||
{width=640}
|
{width=640}
|
||||||
|
|
@ -54,4 +54,4 @@ It leverages LLM technology to transform PR comments and review suggestions into
|
||||||
|
|
||||||
- Use `/implement` to implement code change within and based on the review discussion.
|
- Use `/implement` to implement code change within and based on the review discussion.
|
||||||
- Use `/implement <code-change-description>` inside a review discussion to implement specific instructions.
|
- Use `/implement <code-change-description>` inside a review discussion to implement specific instructions.
|
||||||
- Use `/implement <link-to-review-comment>` to indirectly call the tool from any comment.
|
- Use `/implement <link-to-an-inline-comment>` to respond to an inline comment by triggering the tool from anywhere in the thread.
|
||||||
|
|
|
||||||
|
|
@ -42,8 +42,6 @@ For example, you can choose to present all the suggestions as committable code c
|
||||||
|
|
||||||
{width=512}
|
{width=512}
|
||||||
|
|
||||||
As can be seen, a single table comment has a significantly smaller PR footprint. We recommend this mode for most cases.
|
|
||||||
Also note that collapsible are not supported in _Bitbucket_. Hence, the suggestions can only be presented in Bitbucket as code comments.
|
|
||||||
|
|
||||||
#### Manual more suggestions
|
#### Manual more suggestions
|
||||||
To generate more suggestions (distinct from the ones already generated), for git-providers that don't support interactive checkbox option, you can manually run:
|
To generate more suggestions (distinct from the ones already generated), for git-providers that don't support interactive checkbox option, you can manually run:
|
||||||
|
|
@ -71,6 +69,32 @@ num_code_suggestions_per_chunk = ...
|
||||||
- The `pr_commands` lists commands that will be executed automatically when a PR is opened.
|
- The `pr_commands` lists commands that will be executed automatically when a PR is opened.
|
||||||
- The `[pr_code_suggestions]` section contains the configurations for the `improve` tool you want to edit (if any)
|
- The `[pr_code_suggestions]` section contains the configurations for the `improve` tool you want to edit (if any)
|
||||||
|
|
||||||
|
### Table vs Committable code comments
|
||||||
|
|
||||||
|
Qodo Merge supports two modes for presenting code suggestions:
|
||||||
|
|
||||||
|
1) [Table](https://codium.ai/images/pr_agent/code_suggestions_as_comment_closed.png) mode
|
||||||
|
|
||||||
|
2) [Inline Committable](https://codium.ai/images/pr_agent/improve.png) code comments mode.
|
||||||
|
|
||||||
|
The table format offers several key advantages:
|
||||||
|
|
||||||
|
- **Reduced noise**: Creates a cleaner PR experience with less clutter
|
||||||
|
- **Quick overview and prioritization**: Enables quick review of one-liner summaries, impact levels, and easy prioritization
|
||||||
|
- **High-level suggestions**: High-level suggestions that aren't tied to specific code chunks are presented only in the table mode
|
||||||
|
- **Interactive features**: Provides 'more' and 'update' functionality via clickable buttons
|
||||||
|
- **Centralized tracking**: Shows suggestion implementation status in one place
|
||||||
|
- **IDE integration**: Allows applying suggestions directly in your IDE via [Qodo Command](https://github.com/qodo-ai/agents)
|
||||||
|
|
||||||
|
Table mode is the default of Qodo Merge, and is recommended approach for most users due to these benefits.
|
||||||
|
|
||||||
|
{width=512}
|
||||||
|
|
||||||
|
Teams with specific preferences can enable committable code comments mode in their local configuration, or use [dual publishing mode](#dual-publishing-mode).
|
||||||
|
|
||||||
|
> `Note - due to platform limitations, Bitbucket cloud and server supports only committable code comments mode.`
|
||||||
|
|
||||||
|
|
||||||
### Assessing Impact
|
### Assessing Impact
|
||||||
|
|
||||||
>`💎 feature`
|
>`💎 feature`
|
||||||
|
|
@ -156,6 +180,7 @@ Qodo Merge supports both simple and hierarchical best practices configurations t
|
||||||
- Keep each file relatively short, under 800 lines, since:
|
- Keep each file relatively short, under 800 lines, since:
|
||||||
- AI models may not process effectively very long documents
|
- AI models may not process effectively very long documents
|
||||||
- Long files tend to contain generic guidelines already known to AI
|
- Long files tend to contain generic guidelines already known to AI
|
||||||
|
- Maximum multiple file accumulated content is limited to 2000 lines.
|
||||||
- Use pattern-based structure rather than simple bullet points for better clarity
|
- Use pattern-based structure rather than simple bullet points for better clarity
|
||||||
|
|
||||||
???- tip "Example of a best practices file"
|
???- tip "Example of a best practices file"
|
||||||
|
|
@ -226,34 +251,44 @@ For organizations managing multiple repositories with different requirements, Qo
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
pr-agent-settings/
|
pr-agent-settings/
|
||||||
├── metadata.yaml # Maps repos/folders to best practice paths
|
├── metadata.yaml # Maps repos/folders to best practice paths
|
||||||
└── codebase_standards/ # Root for all best practice definitions
|
└── codebase_standards/ # Root for all best practice definitions
|
||||||
├── global/ # Global rules, inherited widely
|
├── global/ # Global rules, inherited widely
|
||||||
│ └── best_practices.md
|
│ └── best_practices.md
|
||||||
├── groups/ # For groups of repositories
|
├── groups/ # For groups of repositories
|
||||||
│ ├── frontend_repos/
|
│ ├── frontend_repos/
|
||||||
│ │ └── best_practices.md
|
│ │ └── best_practices.md
|
||||||
│ ├── backend_repos/
|
│ ├── backend_repos/
|
||||||
│ │ └── best_practices.md
|
│ │ └── best_practices.md
|
||||||
│ └── ...
|
│ ├── python_repos/
|
||||||
├── qodo-merge/ # For standalone repositories
|
|
||||||
│ └── best_practices.md
|
|
||||||
├── qodo-monorepo/ # For monorepo-specific rules
|
|
||||||
│ ├── best_practices.md # Root level monorepo rules
|
|
||||||
│ ├── qodo-github/ # Subproject best practices
|
|
||||||
│ │ └── best_practices.md
|
│ │ └── best_practices.md
|
||||||
│ └── qodo-gitlab/ # Another subproject
|
│ ├── cpp_repos/
|
||||||
|
│ │ └── best_practices.md
|
||||||
|
│ └── ...
|
||||||
|
├── repo_a/ # For standalone repositories
|
||||||
|
│ └── best_practices.md
|
||||||
|
├── monorepo-name/ # For monorepo-specific rules
|
||||||
|
│ ├── best_practices.md # Root level monorepo rules
|
||||||
|
│ ├── service-a/ # Subproject best practices
|
||||||
|
│ │ └── best_practices.md
|
||||||
|
│ └── service-b/ # Another subproject
|
||||||
│ └── best_practices.md
|
│ └── best_practices.md
|
||||||
└── ... # More repositories
|
└── ... # More repositories
|
||||||
```
|
```
|
||||||
|
|
||||||
|
> **Note:** In this structure, `pr-agent-settings`, `codebase_standards`, `global`, `groups`, `metadata.yaml`, and `best_practices.md` are hardcoded names that must be used exactly as shown. All other names (such as `frontend_repos`, `backend_repos`, `repo_a`, `monorepo-name`, `service-a`, etc.) are examples and should be replaced with your actual repository and service names.
|
||||||
|
|
||||||
|
???+ tip "Grouping and categorizing best practices"
|
||||||
|
- Each folder (including the global folder) can contain a single `best_practices.md` file
|
||||||
|
- Organize repository best practices by creating subfolders within the `groups` folder. Group them by purpose, programming languages, or other categories
|
||||||
|
|
||||||
3\. Define the metadata file `metadata.yaml` that maps your repositories to their relevant best practices paths, for example:
|
3\. Define the metadata file `metadata.yaml` that maps your repositories to their relevant best practices paths, for example:
|
||||||
|
|
||||||
```yaml
|
```yaml
|
||||||
# Standalone repos
|
# Standalone repos
|
||||||
qodo-merge:
|
repo_a:
|
||||||
best_practices_paths:
|
best_practices_paths:
|
||||||
- "qodo-merge"
|
- "repo_a"
|
||||||
|
|
||||||
# Group-associated repos
|
# Group-associated repos
|
||||||
repo_b:
|
repo_b:
|
||||||
|
|
@ -267,16 +302,16 @@ For organizations managing multiple repositories with different requirements, Qo
|
||||||
- "groups/backend_repos"
|
- "groups/backend_repos"
|
||||||
|
|
||||||
# Monorepo with subprojects
|
# Monorepo with subprojects
|
||||||
qodo-monorepo:
|
monorepo-name:
|
||||||
best_practices_paths:
|
best_practices_paths:
|
||||||
- "qodo-monorepo"
|
- "monorepo-name"
|
||||||
monorepo_subprojects:
|
monorepo_subprojects:
|
||||||
qodo-github:
|
service-a:
|
||||||
best_practices_paths:
|
best_practices_paths:
|
||||||
- "qodo-monorepo/qodo-github"
|
- "monorepo-name/service-a"
|
||||||
qodo-gitlab:
|
service-b:
|
||||||
best_practices_paths:
|
best_practices_paths:
|
||||||
- "qodo-monorepo/qodo-gitlab"
|
- "monorepo-name/service-b"
|
||||||
```
|
```
|
||||||
|
|
||||||
4\. Set the following configuration in your global configuration file:
|
4\. Set the following configuration in your global configuration file:
|
||||||
|
|
@ -437,9 +472,25 @@ dual_publishing_score_threshold = x
|
||||||
|
|
||||||
Where x represents the minimum score threshold (>=) for suggestions to be presented as committable PR comments in addition to the table. Default is -1 (disabled).
|
Where x represents the minimum score threshold (>=) for suggestions to be presented as committable PR comments in addition to the table. Default is -1 (disabled).
|
||||||
|
|
||||||
|
### Controlling suggestions depth
|
||||||
|
|
||||||
|
> `💎 feature`
|
||||||
|
|
||||||
|
You can control the depth and comprehensiveness of the code suggestions by using the `pr_code_suggestions.suggestions_depth` parameter.
|
||||||
|
|
||||||
|
Available options:
|
||||||
|
|
||||||
|
- `selective` - Shows only suggestions above a score threshold of 6
|
||||||
|
- `regular` - Default mode with balanced suggestion coverage
|
||||||
|
- `exhaustive` - Provides maximum suggestion comprehensiveness
|
||||||
|
|
||||||
|
(Alternatively, use numeric values: 1, 2, or 3 respectively)
|
||||||
|
|
||||||
|
We recommend starting with `regular` mode, then exploring `exhaustive` mode, which can provide more comprehensive suggestions and enhanced bug detection.
|
||||||
|
|
||||||
### Self-review
|
### Self-review
|
||||||
|
|
||||||
> `💎 feature` Platforms supported: GitHub, GitLab
|
> `💎 feature. Platforms supported: GitHub, GitLab`
|
||||||
|
|
||||||
If you set in a configuration file:
|
If you set in a configuration file:
|
||||||
|
|
||||||
|
|
@ -491,11 +542,11 @@ Qodo Merge uses a dynamic strategy to generate code suggestions based on the siz
|
||||||
#### 1. Chunking large PRs
|
#### 1. Chunking large PRs
|
||||||
|
|
||||||
- Qodo Merge divides large PRs into 'chunks'.
|
- Qodo Merge divides large PRs into 'chunks'.
|
||||||
- Each chunk contains up to `pr_code_suggestions.max_context_tokens` tokens (default: 24,000).
|
- Each chunk contains up to `config.max_model_tokens` tokens (default: 32,000).
|
||||||
|
|
||||||
#### 2. Generating suggestions
|
#### 2. Generating suggestions
|
||||||
|
|
||||||
- For each chunk, Qodo Merge generates up to `pr_code_suggestions.num_code_suggestions_per_chunk` suggestions (default: 4).
|
- For each chunk, Qodo Merge generates up to `pr_code_suggestions.num_code_suggestions_per_chunk` suggestions (default: 3).
|
||||||
|
|
||||||
This approach has two main benefits:
|
This approach has two main benefits:
|
||||||
|
|
||||||
|
|
@ -504,6 +555,36 @@ This approach has two main benefits:
|
||||||
|
|
||||||
Note: Chunking is primarily relevant for large PRs. For most PRs (up to 600 lines of code), Qodo Merge will be able to process the entire code in a single call.
|
Note: Chunking is primarily relevant for large PRs. For most PRs (up to 600 lines of code), Qodo Merge will be able to process the entire code in a single call.
|
||||||
|
|
||||||
|
#### Maximum coverage configuration
|
||||||
|
> `💎 feature`
|
||||||
|
|
||||||
|
For critical code reviews requiring maximum coverage, you can combine several settings to achieve a "super exhaustive" analysis. This is not a built-in mode, but a configuration recipe for advanced use cases.
|
||||||
|
|
||||||
|
```toml
|
||||||
|
# Recipe for maximum suggestion comprehensiveness
|
||||||
|
[pr_code_suggestions]
|
||||||
|
suggestions_depth = "exhaustive"
|
||||||
|
enable_suggestion_type_reuse = true
|
||||||
|
num_code_suggestions_per_chunk = 100
|
||||||
|
num_best_practice_suggestions = 100
|
||||||
|
```
|
||||||
|
|
||||||
|
This configuration is recommended for:
|
||||||
|
|
||||||
|
- Critical code reviews requiring maximum coverage
|
||||||
|
- Final reviews before major releases
|
||||||
|
- Code quality audits
|
||||||
|
|
||||||
|
???- warning "Performance considerations"
|
||||||
|
|
||||||
|
This configuration will significantly increase:
|
||||||
|
|
||||||
|
- Analysis time and API costs
|
||||||
|
- Number of suggestions generated (potentially overwhelming)
|
||||||
|
- Comment volume in your PR
|
||||||
|
|
||||||
|
Use this configuration judiciously and consider your team's review capacity.
|
||||||
|
|
||||||
## Configuration options
|
## Configuration options
|
||||||
|
|
||||||
???+ example "General options"
|
???+ example "General options"
|
||||||
|
|
@ -521,6 +602,10 @@ Note: Chunking is primarily relevant for large PRs. For most PRs (up to 600 line
|
||||||
<td><b>enable_chat_in_code_suggestions</b></td>
|
<td><b>enable_chat_in_code_suggestions</b></td>
|
||||||
<td>If set to true, QM bot will interact with comments made on code changes it has proposed. Default is true.</td>
|
<td>If set to true, QM bot will interact with comments made on code changes it has proposed. Default is true.</td>
|
||||||
</tr>
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td><b>suggestions_depth 💎</b></td>
|
||||||
|
<td> Controls the depth of the suggestions. Can be set to 'selective', 'regular', or 'exhaustive'. Default is 'regular'.</td>
|
||||||
|
</tr>
|
||||||
<tr>
|
<tr>
|
||||||
<td><b>dual_publishing_score_threshold</b></td>
|
<td><b>dual_publishing_score_threshold</b></td>
|
||||||
<td>Minimum score threshold for suggestions to be presented as committable PR comments in addition to the table. Default is -1 (disabled).</td>
|
<td>Minimum score threshold for suggestions to be presented as committable PR comments in addition to the table. Default is -1 (disabled).</td>
|
||||||
|
|
@ -547,11 +632,11 @@ Note: Chunking is primarily relevant for large PRs. For most PRs (up to 600 line
|
||||||
</tr>
|
</tr>
|
||||||
<tr>
|
<tr>
|
||||||
<td><b>enable_help_text</b></td>
|
<td><b>enable_help_text</b></td>
|
||||||
<td>If set to true, the tool will display a help text in the comment. Default is true.</td>
|
<td>If set to true, the tool will display a help text in the comment. Default is false.</td>
|
||||||
</tr>
|
</tr>
|
||||||
<tr>
|
<tr>
|
||||||
<td><b>enable_chat_text</b></td>
|
<td><b>enable_chat_text</b></td>
|
||||||
<td>If set to true, the tool will display a reference to the PR chat in the comment. Default is true.</td>
|
<td>If set to true, the tool will display a reference to the PR chat in the comment. Default is false.</td>
|
||||||
</tr>
|
</tr>
|
||||||
<tr>
|
<tr>
|
||||||
<td><b>publish_output_no_suggestions</b></td>
|
<td><b>publish_output_no_suggestions</b></td>
|
||||||
|
|
@ -577,6 +662,10 @@ Note: Chunking is primarily relevant for large PRs. For most PRs (up to 600 line
|
||||||
<td><b>num_code_suggestions_per_chunk</b></td>
|
<td><b>num_code_suggestions_per_chunk</b></td>
|
||||||
<td>Number of code suggestions provided by the 'improve' tool, per chunk. Default is 3.</td>
|
<td>Number of code suggestions provided by the 'improve' tool, per chunk. Default is 3.</td>
|
||||||
</tr>
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td><b>num_best_practice_suggestions 💎</b></td>
|
||||||
|
<td>Number of code suggestions provided by the 'improve' tool for best practices. Default is 1.</td>
|
||||||
|
</tr>
|
||||||
<tr>
|
<tr>
|
||||||
<td><b>max_number_of_calls</b></td>
|
<td><b>max_number_of_calls</b></td>
|
||||||
<td>Maximum number of chunks. Default is 3.</td>
|
<td>Maximum number of chunks. Default is 3.</td>
|
||||||
|
|
|
||||||
|
|
@ -1,6 +1,6 @@
|
||||||
## Overview
|
## Overview
|
||||||
|
|
||||||
The `improve_component` tool generates code suggestions for a specific code component that changed in the PR.
|
The `improve_component` tool generates code suggestions for a specific code component that has changed in the PR.
|
||||||
it can be invoked manually by commenting on any PR:
|
it can be invoked manually by commenting on any PR:
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
@ -20,7 +20,7 @@ The tool will generate code suggestions for the selected component (if no compon
|
||||||
{width=768}
|
{width=768}
|
||||||
|
|
||||||
!!! note "Notes"
|
!!! note "Notes"
|
||||||
- Language that are currently supported by the tool: Python, Java, C++, JavaScript, TypeScript, C#.
|
- Languages that are currently supported by the tool: `Python, Java, C++, JavaScript, TypeScript, C#, Go, Kotlin`
|
||||||
- This tool can also be triggered interactively by using the [`analyze`](./analyze.md) tool.
|
- This tool can also be triggered interactively by using the [`analyze`](./analyze.md) tool.
|
||||||
|
|
||||||
## Configuration options
|
## Configuration options
|
||||||
|
|
|
||||||
|
|
@ -14,11 +14,13 @@ Here is a list of Qodo Merge tools, each with a dedicated page that explains how
|
||||||
| **💎 [Add Documentation (`/add_docs`](./documentation.md))** | Generates documentation to methods/functions/classes that changed in the PR |
|
| **💎 [Add Documentation (`/add_docs`](./documentation.md))** | Generates documentation to methods/functions/classes that changed in the PR |
|
||||||
| **💎 [Analyze (`/analyze`](./analyze.md))** | Identify code components that changed in the PR, and enables to interactively generate tests, docs, and code suggestions for each component |
|
| **💎 [Analyze (`/analyze`](./analyze.md))** | Identify code components that changed in the PR, and enables to interactively generate tests, docs, and code suggestions for each component |
|
||||||
| **💎 [CI Feedback (`/checks ci_job`](./ci_feedback.md))** | Automatically generates feedback and analysis for a failed CI job |
|
| **💎 [CI Feedback (`/checks ci_job`](./ci_feedback.md))** | Automatically generates feedback and analysis for a failed CI job |
|
||||||
|
| **💎 [Compliance (`/compliance`](./compliance.md))** | Comprehensive compliance checks for security, ticket requirements, and custom organizational rules |
|
||||||
| **💎 [Custom Prompt (`/custom_prompt`](./custom_prompt.md))** | Automatically generates custom suggestions for improving the PR code, based on specific guidelines defined by the user |
|
| **💎 [Custom Prompt (`/custom_prompt`](./custom_prompt.md))** | Automatically generates custom suggestions for improving the PR code, based on specific guidelines defined by the user |
|
||||||
| **💎 [Generate Custom Labels (`/generate_labels`](./custom_labels.md))** | Generates custom labels for the PR, based on specific guidelines defined by the user |
|
| **💎 [Generate Custom Labels (`/generate_labels`](./custom_labels.md))** | Generates custom labels for the PR, based on specific guidelines defined by the user |
|
||||||
| **💎 [Generate Tests (`/test`](./test.md))** | Automatically generates unit tests for a selected component, based on the PR code changes |
|
| **💎 [Generate Tests (`/test`](./test.md))** | Automatically generates unit tests for a selected component, based on the PR code changes |
|
||||||
| **💎 [Implement (`/implement`](./implement.md))** | Generates implementation code from review suggestions |
|
| **💎 [Implement (`/implement`](./implement.md))** | Generates implementation code from review suggestions |
|
||||||
| **💎 [Improve Component (`/improve_component component_name`](./improve_component.md))** | Generates code suggestions for a specific code component that changed in the PR |
|
| **💎 [Improve Component (`/improve_component component_name`](./improve_component.md))** | Generates code suggestions for a specific code component that changed in the PR |
|
||||||
|
| **💎 [PR to Ticket (`/create_ticket`](./pr_to_ticket.md))** | Generates ticket in the ticket tracking systems (Jira, Linear, or Git provider issues) based on PR content |
|
||||||
| **💎 [Scan Repo Discussions (`/scan_repo_discussions`](./scan_repo_discussions.md))** | Generates `best_practices.md` file based on previous discussions in the repository |
|
| **💎 [Scan Repo Discussions (`/scan_repo_discussions`](./scan_repo_discussions.md))** | Generates `best_practices.md` file based on previous discussions in the repository |
|
||||||
| **💎 [Similar Code (`/similar_code`](./similar_code.md))** | Retrieves the most similar code components from inside the organization's codebase, or from open-source code. |
|
| **💎 [Similar Code (`/similar_code`](./similar_code.md))** | Retrieves the most similar code components from inside the organization's codebase, or from open-source code. |
|
||||||
|
|
||||||
|
|
|
||||||
89
docs/docs/tools/pr_to_ticket.md
Normal file
89
docs/docs/tools/pr_to_ticket.md
Normal file
|
|
@ -0,0 +1,89 @@
|
||||||
|
`Platforms supported: GitHub, GitLab, Bitbucket`
|
||||||
|
|
||||||
|
`Supported Ticket providers: Jira, Linear, GitHub Issues, Gitlab Issues`
|
||||||
|
|
||||||
|
## Overview
|
||||||
|
The `create_ticket` tool automatically generates tickets in ticket tracking systems (`Jira`, `Linear`, or `GitHub Issues` and `Gitlab issues`) based on PR content.
|
||||||
|
|
||||||
|
It analyzes the PR's data (code changes, commit messages, and description) to create well-structured tickets that capture the essence of the development work, helping teams maintain traceability between code changes and project management systems.
|
||||||
|
|
||||||
|
When a ticket is created, it appears in the PR description under an `Auto-created Ticket` section, complete with a link to the generated ticket.
|
||||||
|
|
||||||
|
{width=512}
|
||||||
|
|
||||||
|
!!! info "Pre-requisites"
|
||||||
|
- To use this tool you need to integrate your ticketing system with Qodo-merge, follow the [Ticket Compliance Documentation](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/).
|
||||||
|
- For Jira Cloud users, please re-integrate your connection through the [qodo merge integration page](https://app.qodo.ai/qodo-merge/integrations) to enable the `update` permission required for ticket creation
|
||||||
|
- You need to configure the project key in ticket corresponding to the repository where the PR is created. This is done by adding the `default_project_key`.
|
||||||
|
|
||||||
|
```toml
|
||||||
|
[pr_to_ticket]
|
||||||
|
default_project_key = "PROJECT_KEY" # e.g., "SCRUM"
|
||||||
|
```
|
||||||
|
|
||||||
|
## Usage
|
||||||
|
there are 3 ways to use the `create_ticket` tool:
|
||||||
|
|
||||||
|
1. [**Automatic Ticket Creation**](#automatic-ticket-creation)
|
||||||
|
2. [**Interactive Triggering via Compliance Tool**](#interactive-triggering-via-compliance-tool)
|
||||||
|
3. [**Manual Ticket Creation**](#manual-ticket-creation)
|
||||||
|
|
||||||
|
### Automatic Ticket Creation
|
||||||
|
The tool can be configured to automatically create tickets when a PR is opened or updated and the PR does not already have a ticket associated with it.
|
||||||
|
This ensures that every code change is documented in the ticketing system without manual intervention.
|
||||||
|
|
||||||
|
To configure automatic ticket creation, add the following to `.pr_agent.toml`:
|
||||||
|
|
||||||
|
```toml
|
||||||
|
[pr_description]
|
||||||
|
auto_create_ticket = true
|
||||||
|
```
|
||||||
|
|
||||||
|
### Interactive Triggering via Compliance Tool
|
||||||
|
`Supported only in Github and Gitlab`
|
||||||
|
|
||||||
|
The tool can be triggered interactively through a checkbox in the compliance tool. This allows users to create tickets as part of their PR Compliance Review workflow.
|
||||||
|
|
||||||
|
{width=512}
|
||||||
|
|
||||||
|
- After clicking the checkbox, the tool will create a ticket and will add/update the `PR Description` with a section called `Auto-created Ticket` with the link to the created ticket.
|
||||||
|
- Then you can click `update` in the `Ticket compliance` section in the `Compliance` tool
|
||||||
|
|
||||||
|
{width=512}
|
||||||
|
|
||||||
|
### Manual Ticket Creation
|
||||||
|
Users can manually trigger the ticket creation process from the PR interface.
|
||||||
|
|
||||||
|
To trigger ticket creation manually, the user can call this tool from the PR comment:
|
||||||
|
|
||||||
|
```
|
||||||
|
/create_ticket
|
||||||
|
```
|
||||||
|
|
||||||
|
After triggering, the tool will create a ticket and will add/update the `PR Description` with a section called `Auto-created Ticket` with the link to the created ticket.
|
||||||
|
|
||||||
|
|
||||||
|
## Configuration
|
||||||
|
|
||||||
|
## Configuration Options
|
||||||
|
|
||||||
|
???+ example "Configuration"
|
||||||
|
|
||||||
|
<table>
|
||||||
|
<tr>
|
||||||
|
<td><b>default_project_key</b></td>
|
||||||
|
<td>The default project key for your ticketing system (e.g., `SCRUM`). This is required unless `fallback_to_git_provider_issues` is set to `true`.</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td><b>default_base_url</b></td>
|
||||||
|
<td>If your organization have integrated to multiple ticketing systems, you can set the default base URL for the ticketing system. This will be used to create tickets in the default system. Example: `https://YOUR-ORG.atlassian.net`.</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td><b>fallback_to_git_provider_issues</b></td>
|
||||||
|
<td>If set to `true`, the tool will create issues in the Git provider's issue tracker (GitHub, Gitlab) if the `default_project_key` is not configured in the repository configuration. Default is `false`.</td>
|
||||||
|
</tr>
|
||||||
|
</table>
|
||||||
|
|
||||||
|
|
||||||
|
## Helping Your Organization Meet SOC-2 Requirements
|
||||||
|
The `create_ticket` tool helps your organization satisfy SOC-2 compliance. By automatically creating tickets from PRs and establishing bidirectional links between them, it ensures every code change is traceable to its corresponding business requirement or task.
|
||||||
|
|
@ -1,6 +1,6 @@
|
||||||
## Overview
|
## Overview
|
||||||
|
|
||||||
The `review` tool scans the PR code changes, and generates a list of feedbacks about the PR, aiming to aid the reviewing process.
|
The `review` tool scans the PR code changes, and generates feedback about the PR, aiming to aid the reviewing process.
|
||||||
<br>
|
<br>
|
||||||
The tool can be triggered automatically every time a new PR is [opened](../usage-guide/automations_and_usage.md#github-app-automatic-tools-when-a-new-pr-is-opened), or can be invoked manually by commenting on any PR:
|
The tool can be triggered automatically every time a new PR is [opened](../usage-guide/automations_and_usage.md#github-app-automatic-tools-when-a-new-pr-is-opened), or can be invoked manually by commenting on any PR:
|
||||||
|
|
||||||
|
|
@ -8,7 +8,7 @@ The tool can be triggered automatically every time a new PR is [opened](../usage
|
||||||
/review
|
/review
|
||||||
```
|
```
|
||||||
|
|
||||||
Note that the main purpose of the `review` tool is to provide the **PR reviewer** with useful feedbacks and insights. The PR author, in contrast, may prefer to save time and focus on the output of the [improve](./improve.md) tool, which provides actionable code suggestions.
|
Note that the main purpose of the `review` tool is to provide the **PR reviewer** with useful feedback and insights. The PR author, in contrast, may prefer to save time and focus on the output of the [improve](./improve.md) tool, which provides actionable code suggestions.
|
||||||
|
|
||||||
(Read more about the different personas in the PR process and how Qodo Merge aims to assist them in our [blog](https://www.codium.ai/blog/understanding-the-challenges-and-pain-points-of-the-pull-request-cycle/))
|
(Read more about the different personas in the PR process and how Qodo Merge aims to assist them in our [blog](https://www.codium.ai/blog/understanding-the-challenges-and-pain-points-of-the-pull-request-cycle/))
|
||||||
|
|
||||||
|
|
@ -68,7 +68,7 @@ extra_instructions = "..."
|
||||||
</tr>
|
</tr>
|
||||||
<tr>
|
<tr>
|
||||||
<td><b>enable_help_text</b></td>
|
<td><b>enable_help_text</b></td>
|
||||||
<td>If set to true, the tool will display a help text in the comment. Default is true.</td>
|
<td>If set to true, the tool will display a help text in the comment. Default is false.</td>
|
||||||
</tr>
|
</tr>
|
||||||
<tr>
|
<tr>
|
||||||
<td><b>num_max_findings</b></td>
|
<td><b>num_max_findings</b></td>
|
||||||
|
|
@ -91,6 +91,10 @@ extra_instructions = "..."
|
||||||
<td><b>require_estimate_effort_to_review</b></td>
|
<td><b>require_estimate_effort_to_review</b></td>
|
||||||
<td>If set to true, the tool will add a section that estimates the effort needed to review the PR. Default is true.</td>
|
<td>If set to true, the tool will add a section that estimates the effort needed to review the PR. Default is true.</td>
|
||||||
</tr>
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td><b>require_estimate_contribution_time_cost</b></td>
|
||||||
|
<td>If set to true, the tool will add a section that estimates the time required for a senior developer to create and submit such changes. Default is false.</td>
|
||||||
|
</tr>
|
||||||
<tr>
|
<tr>
|
||||||
<td><b>require_can_be_split_review</b></td>
|
<td><b>require_can_be_split_review</b></td>
|
||||||
<td>If set to true, the tool will add a section that checks if the PR contains several themes, and can be split into smaller PRs. Default is false.</td>
|
<td>If set to true, the tool will add a section that checks if the PR contains several themes, and can be split into smaller PRs. Default is false.</td>
|
||||||
|
|
|
||||||
|
|
@ -1,10 +1,12 @@
|
||||||
|
`Platforms supported: GitHub`
|
||||||
|
|
||||||
## Overview
|
## Overview
|
||||||
|
|
||||||
The similar code tool retrieves the most similar code components from inside the organization's codebase, or from open-source code.
|
The similar code tool retrieves the most similar code components from inside the organization's codebase, or from open-source code.
|
||||||
|
|
||||||
For example:
|
For example:
|
||||||
|
|
||||||
`Global Search` for a method called `chat_completion`:
|
A `Global Search` for a method called `chat_completion`:
|
||||||
|
|
||||||
{width=768}
|
{width=768}
|
||||||
|
|
||||||
|
|
@ -19,7 +21,7 @@ Search result link example:
|
||||||
|
|
||||||
{width=768}
|
{width=768}
|
||||||
|
|
||||||
`Organization Search`:
|
An `Organization Search`:
|
||||||
|
|
||||||
{width=768}
|
{width=768}
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -27,6 +27,7 @@ Choose from the following Vector Databases:
|
||||||
|
|
||||||
1. LanceDB
|
1. LanceDB
|
||||||
2. Pinecone
|
2. Pinecone
|
||||||
|
3. Qdrant
|
||||||
|
|
||||||
#### Pinecone Configuration
|
#### Pinecone Configuration
|
||||||
|
|
||||||
|
|
@ -40,6 +41,25 @@ environment = "..."
|
||||||
|
|
||||||
These parameters can be obtained by registering to [Pinecone](https://app.pinecone.io/?sessionType=signup/).
|
These parameters can be obtained by registering to [Pinecone](https://app.pinecone.io/?sessionType=signup/).
|
||||||
|
|
||||||
|
#### Qdrant Configuration
|
||||||
|
|
||||||
|
To use Qdrant with the `similar issue` tool, add these credentials to `.secrets.toml` (or set as environment variables):
|
||||||
|
|
||||||
|
```
|
||||||
|
[qdrant]
|
||||||
|
url = "https://YOUR-QDRANT-URL" # e.g., https://xxxxxxxx-xxxxxxxx.eu-central-1-0.aws.cloud.qdrant.io
|
||||||
|
api_key = "..."
|
||||||
|
```
|
||||||
|
|
||||||
|
Then select Qdrant in `configuration.toml`:
|
||||||
|
|
||||||
|
```
|
||||||
|
[pr_similar_issue]
|
||||||
|
vectordb = "qdrant"
|
||||||
|
```
|
||||||
|
|
||||||
|
You can get a free managed Qdrant instance from [Qdrant Cloud](https://cloud.qdrant.io/).
|
||||||
|
|
||||||
## How to use
|
## How to use
|
||||||
|
|
||||||
- To invoke the 'similar issue' tool from **CLI**, run:
|
- To invoke the 'similar issue' tool from **CLI**, run:
|
||||||
|
|
|
||||||
|
|
@ -1,6 +1,6 @@
|
||||||
## Overview
|
## Overview
|
||||||
|
|
||||||
By combining LLM abilities with static code analysis, the `test` tool generate tests for a selected component, based on the PR code changes.
|
By combining LLM abilities with static code analysis, the `test` tool generates tests for a selected component, based on the PR code changes.
|
||||||
It can be invoked manually by commenting on any PR:
|
It can be invoked manually by commenting on any PR:
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
@ -20,7 +20,7 @@ The tool will generate tests for the selected component (if no component is stat
|
||||||
(Example taken from [here](https://github.com/Codium-ai/pr-agent/pull/598#issuecomment-1913679429)):
|
(Example taken from [here](https://github.com/Codium-ai/pr-agent/pull/598#issuecomment-1913679429)):
|
||||||
|
|
||||||
!!! note "Notes"
|
!!! note "Notes"
|
||||||
- The following languages are currently supported: Python, Java, C++, JavaScript, TypeScript, C#.
|
- The following languages are currently supported: `Python, Java, C++, JavaScript, TypeScript, C#, Go, Kotlin`
|
||||||
- This tool can also be triggered interactively by using the [`analyze`](./analyze.md) tool.
|
- This tool can also be triggered interactively by using the [`analyze`](./analyze.md) tool.
|
||||||
|
|
||||||
## Configuration options
|
## Configuration options
|
||||||
|
|
|
||||||
|
|
@ -64,9 +64,9 @@ All Qodo Merge tools have a parameter called `extra_instructions`, that enables
|
||||||
|
|
||||||
## Language Settings
|
## Language Settings
|
||||||
|
|
||||||
The default response language for Qodo Merge is **U.S. English**. However, some development teams may prefer to display information in a different language. For example, your team's workflow might improve if PR descriptions and code suggestions are set to your country's native language.
|
The default response language for Qodo Merge is **U.S. English**. However, some development teams may prefer to display information in a different language. For example, your team's workflow might improve if PR descriptions and code suggestions are set to your country's native language.
|
||||||
|
|
||||||
To configure this, set the `response_language` parameter in the configuration file. This will prompt the model to respond in the specified language. Use a **standard locale code** based on [ISO 3166](https://en.wikipedia.org/wiki/ISO_3166) (country codes) and [ISO 639](https://en.wikipedia.org/wiki/ISO_639) (language codes) to define a language-country pair. See this [comprehensive list of locale codes](https://simplelocalize.io/data/locales/).
|
To configure this, set the `response_language` parameter in the configuration file. This will prompt the model to respond in the specified language. Use a **standard locale code** based on [ISO 3166](https://en.wikipedia.org/wiki/ISO_3166) (country codes) and [ISO 639](https://en.wikipedia.org/wiki/ISO_639) (language codes) to define a language-country pair. See this [comprehensive list of locale codes](https://simplelocalize.io/data/locales/).
|
||||||
|
|
||||||
Example:
|
Example:
|
||||||
|
|
||||||
|
|
@ -97,33 +97,17 @@ This will set the response language globally for all the commands to Italian.
|
||||||
|
|
||||||
[//]: # (which divides the PR into chunks, and processes each chunk separately. With this mode, regardless of the model, no compression will be done (but for large PRs, multiple model calls may occur))
|
[//]: # (which divides the PR into chunks, and processes each chunk separately. With this mode, regardless of the model, no compression will be done (but for large PRs, multiple model calls may occur))
|
||||||
|
|
||||||
## Patch Extra Lines
|
|
||||||
|
|
||||||
By default, around any change in your PR, git patch provides three lines of context above and below the change.
|
## Expand GitLab submodule diffs
|
||||||
|
|
||||||
```
|
By default, GitLab merge requests show submodule updates as `Subproject commit` lines. To include the actual file-level changes from those submodules in Qodo Merge analysis, enable:
|
||||||
@@ -12,5 +12,5 @@ def func1():
|
|
||||||
code line that already existed in the file...
|
```toml
|
||||||
code line that already existed in the file...
|
[gitlab]
|
||||||
code line that already existed in the file....
|
expand_submodule_diffs = true
|
||||||
-code line that was removed in the PR
|
|
||||||
+new code line added in the PR
|
|
||||||
code line that already existed in the file...
|
|
||||||
code line that already existed in the file...
|
|
||||||
code line that already existed in the file...
|
|
||||||
```
|
```
|
||||||
|
|
||||||
Qodo Merge will try to increase the number of lines of context, via the parameter:
|
When enabled, Qodo Merge will fetch and attach diffs from the submodule repositories. The default is `false` to avoid extra GitLab API calls.
|
||||||
|
|
||||||
```
|
|
||||||
[config]
|
|
||||||
patch_extra_lines_before=3
|
|
||||||
patch_extra_lines_after=1
|
|
||||||
```
|
|
||||||
|
|
||||||
Increasing this number provides more context to the model, but will also increase the token budget, and may overwhelm the model with too much information, unrelated to the actual PR code changes.
|
|
||||||
|
|
||||||
If the PR is too large (see [PR Compression strategy](https://github.com/Codium-ai/pr-agent/blob/main/PR_COMPRESSION.md)), Qodo Merge may automatically set this number to 0, and will use the original git patch.
|
|
||||||
|
|
||||||
## Log Level
|
## Log Level
|
||||||
|
|
||||||
|
|
@ -158,6 +142,27 @@ LANGSMITH_PROJECT=<project>
|
||||||
LANGSMITH_BASE_URL=<url>
|
LANGSMITH_BASE_URL=<url>
|
||||||
```
|
```
|
||||||
|
|
||||||
|
## Bringing additional repository metadata to Qodo Merge 💎
|
||||||
|
|
||||||
|
To provide Qodo Merge tools with additional context about your project, you can enable automatic repository metadata detection.
|
||||||
|
|
||||||
|
If you set:
|
||||||
|
|
||||||
|
```toml
|
||||||
|
[config]
|
||||||
|
add_repo_metadata = true
|
||||||
|
```
|
||||||
|
|
||||||
|
Qodo Merge automatically searches for repository metadata files in your PR's head branch root directory. By default, it looks for:
|
||||||
|
[AGENTS.MD](https://agents.md/), [QODO.MD](https://docs.qodo.ai/qodo-documentation/qodo-command/getting-started/setup-and-quickstart), [CLAUDE.MD](https://www.anthropic.com/engineering/claude-code-best-practices).
|
||||||
|
|
||||||
|
You can also specify custom filenames to search for:
|
||||||
|
|
||||||
|
```toml
|
||||||
|
[config]
|
||||||
|
add_repo_metadata_file_list= ["file1.md", "file2.md", ...]
|
||||||
|
```
|
||||||
|
|
||||||
## Ignoring automatic commands in PRs
|
## Ignoring automatic commands in PRs
|
||||||
|
|
||||||
Qodo Merge allows you to automatically ignore certain PRs based on various criteria:
|
Qodo Merge allows you to automatically ignore certain PRs based on various criteria:
|
||||||
|
|
@ -246,7 +251,32 @@ To supplement the automatic bot detection, you can manually specify users to ign
|
||||||
ignore_pr_authors = ["my-special-bot-user", ...]
|
ignore_pr_authors = ["my-special-bot-user", ...]
|
||||||
```
|
```
|
||||||
|
|
||||||
Where the `ignore_pr_authors` is a list of usernames that you want to ignore.
|
Where the `ignore_pr_authors` is a regex list of usernames that you want to ignore.
|
||||||
|
|
||||||
!!! note
|
!!! note
|
||||||
There is one specific case where bots will receive an automatic response - when they generated a PR with a _failed test_. In that case, the [`ci_feedback`](https://qodo-merge-docs.qodo.ai/tools/ci_feedback/) tool will be invoked.
|
There is one specific case where bots will receive an automatic response - when they generated a PR with a _failed test_. In that case, the [`ci_feedback`](https://qodo-merge-docs.qodo.ai/tools/ci_feedback/) tool will be invoked.
|
||||||
|
|
||||||
|
### Ignoring Generated Files by Language/Framework
|
||||||
|
|
||||||
|
To automatically exclude files generated by specific languages or frameworks, you can add the following to your `configuration.toml` file:
|
||||||
|
|
||||||
|
```
|
||||||
|
[config]
|
||||||
|
ignore_language_framework = ['protobuf', ...]
|
||||||
|
```
|
||||||
|
|
||||||
|
You can view the list of auto-generated file patterns in [`generated_code_ignore.toml`](https://github.com/qodo-ai/pr-agent/blob/main/pr_agent/settings/generated_code_ignore.toml).
|
||||||
|
Files matching these glob patterns will be automatically excluded from PR Agent analysis.
|
||||||
|
|
||||||
|
### Ignoring Tickets with Specific Labels
|
||||||
|
|
||||||
|
When Qodo Merge analyzes tickets (JIRA, GitHub Issues, GitLab Issues, etc.) referenced in your PR, you may want to exclude tickets that have certain labels from the analysis. This is useful for filtering out tickets marked as "ignore-compliance", "skip-review", or other labels that indicate the ticket should not be considered during PR review.
|
||||||
|
|
||||||
|
To ignore tickets with specific labels, add the following to your `configuration.toml` file:
|
||||||
|
|
||||||
|
```toml
|
||||||
|
[config]
|
||||||
|
ignore_ticket_labels = ["ignore-compliance", "skip-review", "wont-fix"]
|
||||||
|
```
|
||||||
|
|
||||||
|
Where `ignore_ticket_labels` is a list of label names that should be ignored during ticket analysis.
|
||||||
|
|
|
||||||
|
|
@ -30,7 +30,7 @@ verbosity_level=2
|
||||||
This is useful for debugging or experimenting with different tools.
|
This is useful for debugging or experimenting with different tools.
|
||||||
|
|
||||||
3. **git provider**: The [git_provider](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml#L5) field in a configuration file determines the GIT provider that will be used by Qodo Merge. Currently, the following providers are supported:
|
3. **git provider**: The [git_provider](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml#L5) field in a configuration file determines the GIT provider that will be used by Qodo Merge. Currently, the following providers are supported:
|
||||||
`github` **(default)**, `gitlab`, `bitbucket`, `azure`, `codecommit`, `local`,`gitea`, and `gerrit`.
|
`github` **(default)**, `gitlab`, `bitbucket`, `azure`, `codecommit`, `local`, and `gitea`.
|
||||||
|
|
||||||
### CLI Health Check
|
### CLI Health Check
|
||||||
|
|
||||||
|
|
@ -202,6 +202,39 @@ publish_labels = false
|
||||||
|
|
||||||
to prevent Qodo Merge from publishing labels when running the `describe` tool.
|
to prevent Qodo Merge from publishing labels when running the `describe` tool.
|
||||||
|
|
||||||
|
#### Enable using commands in PR
|
||||||
|
|
||||||
|
You can configure your GitHub Actions workflow to trigger on `issue_comment` [events](https://docs.github.com/en/actions/reference/workflows-and-actions/events-that-trigger-workflows#issue_comment) (`created` and `edited`).
|
||||||
|
|
||||||
|
Example GitHub Actions workflow configuration:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
on:
|
||||||
|
issue_comment:
|
||||||
|
types: [created, edited]
|
||||||
|
```
|
||||||
|
|
||||||
|
When this is configured, Qodo merge can be invoked by commenting on the PR.
|
||||||
|
|
||||||
|
#### Quick Reference: Model Configuration in GitHub Actions
|
||||||
|
|
||||||
|
For detailed step-by-step examples of configuring different models (Gemini, Claude, Azure OpenAI, etc.) in GitHub Actions, see the [Configuration Examples](../installation/github.md#configuration-examples) section in the installation guide.
|
||||||
|
|
||||||
|
**Common Model Configuration Patterns:**
|
||||||
|
|
||||||
|
- **OpenAI**: Set `config.model: "gpt-4o"` and `OPENAI_KEY`
|
||||||
|
- **Gemini**: Set `config.model: "gemini/gemini-1.5-flash"` and `GOOGLE_AI_STUDIO.GEMINI_API_KEY` (no `OPENAI_KEY` needed)
|
||||||
|
- **Claude**: Set `config.model: "anthropic/claude-3-opus-20240229"` and `ANTHROPIC.KEY` (no `OPENAI_KEY` needed)
|
||||||
|
- **Azure OpenAI**: Set `OPENAI.API_TYPE: "azure"`, `OPENAI.API_BASE`, and `OPENAI.DEPLOYMENT_ID`
|
||||||
|
- **Local Models**: Set `config.model: "ollama/model-name"` and `OLLAMA.API_BASE`
|
||||||
|
|
||||||
|
**Environment Variable Format:**
|
||||||
|
- Use dots (`.`) to separate sections and keys: `config.model`, `pr_reviewer.extra_instructions`
|
||||||
|
- Boolean values as strings: `"true"` or `"false"`
|
||||||
|
- Arrays as JSON strings: `'["item1", "item2"]'`
|
||||||
|
|
||||||
|
For complete model configuration details, see [Changing a model in PR-Agent](changing_a_model.md).
|
||||||
|
|
||||||
### GitLab Webhook
|
### GitLab Webhook
|
||||||
|
|
||||||
After setting up a GitLab webhook, to control which commands will run automatically when a new MR is opened, you can set the `pr_commands` parameter in the configuration file, similar to the GitHub App:
|
After setting up a GitLab webhook, to control which commands will run automatically when a new MR is opened, you can set the `pr_commands` parameter in the configuration file, similar to the GitHub App:
|
||||||
|
|
|
||||||
|
|
@ -1,7 +1,8 @@
|
||||||
## Changing a model in PR-Agent
|
## Changing a model in PR-Agent
|
||||||
|
|
||||||
See [here](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/algo/__init__.py) for a list of available models.
|
See [here](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/algo/__init__.py) for a list of supported models in PR-Agent.
|
||||||
To use a different model than the default (o4-mini), you need to edit in the [configuration file](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml#L2) the fields:
|
The default model of PR-Agent is `GPT-5` from OpenAI.
|
||||||
|
To use a different model than the default, you need to edit in the [configuration file](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml#L2) the fields:
|
||||||
|
|
||||||
```toml
|
```toml
|
||||||
[config]
|
[config]
|
||||||
|
|
@ -32,6 +33,16 @@ OPENAI__API_BASE=https://api.openai.com/v1
|
||||||
OPENAI__KEY=sk-...
|
OPENAI__KEY=sk-...
|
||||||
```
|
```
|
||||||
|
|
||||||
|
### OpenAI Flex Processing
|
||||||
|
|
||||||
|
To reduce costs for non-urgent/background tasks, enable Flex Processing:
|
||||||
|
|
||||||
|
```toml
|
||||||
|
[litellm]
|
||||||
|
extra_body='{"processing_mode": "flex"}'
|
||||||
|
```
|
||||||
|
|
||||||
|
See [OpenAI Flex Processing docs](https://platform.openai.com/docs/guides/flex-processing) for details.
|
||||||
|
|
||||||
### Azure
|
### Azure
|
||||||
|
|
||||||
|
|
@ -97,7 +108,7 @@ Please note that the `custom_model_max_tokens` setting should be configured in a
|
||||||
!!! note "Local models vs commercial models"
|
!!! note "Local models vs commercial models"
|
||||||
Qodo Merge is compatible with almost any AI model, but analyzing complex code repositories and pull requests requires a model specifically optimized for code analysis.
|
Qodo Merge is compatible with almost any AI model, but analyzing complex code repositories and pull requests requires a model specifically optimized for code analysis.
|
||||||
|
|
||||||
Commercial models such as GPT-4, Claude Sonnet, and Gemini have demonstrated robust capabilities in generating structured output for code analysis tasks with large input. In contrast, most open-source models currently available (as of January 2025) face challenges with these complex tasks.
|
Commercial models such as GPT-5, Claude Sonnet, and Gemini have demonstrated robust capabilities in generating structured output for code analysis tasks with large input. In contrast, most open-source models currently available (as of January 2025) face challenges with these complex tasks.
|
||||||
|
|
||||||
Based on our testing, local open-source models are suitable for experimentation and learning purposes (mainly for the `ask` command), but they are not suitable for production-level code analysis tasks.
|
Based on our testing, local open-source models are suitable for experimentation and learning purposes (mainly for the `ask` command), but they are not suitable for production-level code analysis tasks.
|
||||||
|
|
||||||
|
|
@ -232,6 +243,34 @@ AWS_SECRET_ACCESS_KEY="..."
|
||||||
AWS_REGION_NAME="..."
|
AWS_REGION_NAME="..."
|
||||||
```
|
```
|
||||||
|
|
||||||
|
You can also use the new Meta Llama 4 models available on Amazon Bedrock:
|
||||||
|
|
||||||
|
```toml
|
||||||
|
[config] # in configuration.toml
|
||||||
|
model="bedrock/us.meta.llama4-scout-17b-instruct-v1:0"
|
||||||
|
fallback_models=["bedrock/us.meta.llama4-maverick-17b-instruct-v1:0"]
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Custom Inference Profiles
|
||||||
|
|
||||||
|
To use a custom inference profile with Amazon Bedrock (for cost allocation tags and other configuration settings), add the `model_id` parameter to your configuration:
|
||||||
|
|
||||||
|
```toml
|
||||||
|
[config] # in configuration.toml
|
||||||
|
model="bedrock/anthropic.claude-3-5-sonnet-20240620-v1:0"
|
||||||
|
fallback_models=["bedrock/anthropic.claude-3-5-sonnet-20240620-v1:0"]
|
||||||
|
|
||||||
|
[aws]
|
||||||
|
AWS_ACCESS_KEY_ID="..."
|
||||||
|
AWS_SECRET_ACCESS_KEY="..."
|
||||||
|
AWS_REGION_NAME="..."
|
||||||
|
|
||||||
|
[litellm]
|
||||||
|
model_id = "your-custom-inference-profile-id"
|
||||||
|
```
|
||||||
|
|
||||||
|
The `model_id` parameter will be passed to all Bedrock completion calls, allowing you to use custom inference profiles for better cost allocation and reporting.
|
||||||
|
|
||||||
See [litellm](https://docs.litellm.ai/docs/providers/bedrock#usage) documentation for more information about the environment variables required for Amazon Bedrock.
|
See [litellm](https://docs.litellm.ai/docs/providers/bedrock#usage) documentation for more information about the environment variables required for Amazon Bedrock.
|
||||||
|
|
||||||
### DeepSeek
|
### DeepSeek
|
||||||
|
|
@ -341,7 +380,7 @@ To bypass chat templates and temperature controls, set `config.custom_reasoning_
|
||||||
|
|
||||||
```toml
|
```toml
|
||||||
[config]
|
[config]
|
||||||
reasoning_efffort= = "medium" # "low", "medium", "high"
|
reasoning_effort = "medium" # "low", "medium", "high"
|
||||||
```
|
```
|
||||||
|
|
||||||
With the OpenAI models that support reasoning effort (eg: o4-mini), you can specify its reasoning effort via `config` section. The default value is `medium`. You can change it to `high` or `low` based on your usage.
|
With the OpenAI models that support reasoning effort (eg: o4-mini), you can specify its reasoning effort via `config` section. The default value is `medium`. You can change it to `high` or `low` based on your usage.
|
||||||
|
|
|
||||||
|
|
@ -58,7 +58,7 @@ Then you can give a list of extra instructions to the `review` tool.
|
||||||
|
|
||||||
## Global configuration file 💎
|
## Global configuration file 💎
|
||||||
|
|
||||||
`Platforms supported: GitHub, GitLab, Bitbucket`
|
`Platforms supported: GitHub, GitLab (cloud), Bitbucket (cloud)`
|
||||||
|
|
||||||
If you create a repo called `pr-agent-settings` in your **organization**, its configuration file `.pr_agent.toml` will be used as a global configuration file for any other repo that belongs to the same organization.
|
If you create a repo called `pr-agent-settings` in your **organization**, its configuration file `.pr_agent.toml` will be used as a global configuration file for any other repo that belongs to the same organization.
|
||||||
Parameters from a local `.pr_agent.toml` file, in a specific repo, will override the global configuration parameters.
|
Parameters from a local `.pr_agent.toml` file, in a specific repo, will override the global configuration parameters.
|
||||||
|
|
@ -69,18 +69,21 @@ For example, in the GitHub organization `Codium-ai`:
|
||||||
|
|
||||||
- The repo [`https://github.com/Codium-ai/pr-agent`](https://github.com/Codium-ai/pr-agent/blob/main/.pr_agent.toml) inherits the global configuration file from `pr-agent-settings`.
|
- The repo [`https://github.com/Codium-ai/pr-agent`](https://github.com/Codium-ai/pr-agent/blob/main/.pr_agent.toml) inherits the global configuration file from `pr-agent-settings`.
|
||||||
|
|
||||||
### Bitbucket Organization level configuration file 💎
|
## Project/Group level configuration file 💎
|
||||||
|
|
||||||
|
`Platforms supported: GitLab, Bitbucket Data Center`
|
||||||
|
|
||||||
|
Create a repository named `pr-agent-settings` within a specific project (Bitbucket) or a group/subgroup (Gitlab).
|
||||||
|
The configuration file in this repository will apply to all repositories directly under the same project/group/subgroup.
|
||||||
|
|
||||||
|
!!! note "Note"
|
||||||
|
For Gitlab, in case of a repository nested in several sub groups, the lookup for a pr-agent-settings repo will be only on one level above such repository.
|
||||||
|
|
||||||
|
|
||||||
|
## Organization level configuration file 💎
|
||||||
|
|
||||||
`Relevant platforms: Bitbucket Data Center`
|
`Relevant platforms: Bitbucket Data Center`
|
||||||
|
|
||||||
In Bitbucket Data Center, there are two levels where you can define a global configuration file:
|
|
||||||
|
|
||||||
- Project-level global configuration:
|
|
||||||
|
|
||||||
Create a repository named `pr-agent-settings` within a specific project. The configuration file in this repository will apply to all repositories under the same project.
|
|
||||||
|
|
||||||
- Organization-level global configuration:
|
|
||||||
|
|
||||||
Create a dedicated project to hold a global configuration file that affects all repositories across all projects in your organization.
|
Create a dedicated project to hold a global configuration file that affects all repositories across all projects in your organization.
|
||||||
|
|
||||||
**Setting up organization-level global configuration:**
|
**Setting up organization-level global configuration:**
|
||||||
|
|
|
||||||
|
|
@ -22,6 +22,5 @@ It includes information on how to adjust Qodo Merge configurations, define which
|
||||||
- [Extra instructions](./additional_configurations.md#extra-instructions)
|
- [Extra instructions](./additional_configurations.md#extra-instructions)
|
||||||
- [Working with large PRs](./additional_configurations.md#working-with-large-prs)
|
- [Working with large PRs](./additional_configurations.md#working-with-large-prs)
|
||||||
- [Changing a model](https://qodo-merge-docs.qodo.ai/usage-guide/changing_a_model/)
|
- [Changing a model](https://qodo-merge-docs.qodo.ai/usage-guide/changing_a_model/)
|
||||||
- [Patch Extra Lines](./additional_configurations.md#patch-extra-lines)
|
|
||||||
- [FAQ](https://qodo-merge-docs.qodo.ai/faq/)
|
- [FAQ](https://qodo-merge-docs.qodo.ai/faq/)
|
||||||
- [Qodo Merge Models](./qodo_merge_models)
|
- [Qodo Merge Models](./qodo_merge_models)
|
||||||
|
|
|
||||||
|
|
@ -1,15 +1,15 @@
|
||||||
|
|
||||||
The default models used by Qodo Merge (June 2025) are a combination of Claude Sonnet 4 and Gemini 2.5 Pro.
|
The default models used by Qodo Merge 💎 (October 2025) are a combination of GPT-5, Haiku-4.5, and Gemini 2.5 Pro.
|
||||||
|
|
||||||
### Selecting a Specific Model
|
### Selecting a Specific Model
|
||||||
|
|
||||||
Users can configure Qodo Merge to use only a specific model by editing the [configuration](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/) file.
|
Users can configure Qodo Merge to use only a specific model by editing the [configuration](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/) file.
|
||||||
The models supported by Qodo Merge are:
|
The models supported by Qodo Merge are:
|
||||||
|
|
||||||
- `claude-4-sonnet`
|
- `gpt-5`
|
||||||
- `o4-mini`
|
- `claude-haiku-4.5`
|
||||||
- `gpt-4.1`
|
|
||||||
- `gemini-2.5-pro`
|
- `gemini-2.5-pro`
|
||||||
|
- `o4-mini`
|
||||||
- `deepseek/r1`
|
- `deepseek/r1`
|
||||||
|
|
||||||
To restrict Qodo Merge to using only `o4-mini`, add this setting:
|
To restrict Qodo Merge to using only `o4-mini`, add this setting:
|
||||||
|
|
@ -19,11 +19,11 @@ To restrict Qodo Merge to using only `o4-mini`, add this setting:
|
||||||
model="o4-mini"
|
model="o4-mini"
|
||||||
```
|
```
|
||||||
|
|
||||||
To restrict Qodo Merge to using only `GPT-4.1`, add this setting:
|
To restrict Qodo Merge to using only `GPT-5`, add this setting:
|
||||||
|
|
||||||
```toml
|
```toml
|
||||||
[config]
|
[config]
|
||||||
model="gpt-4.1"
|
model="gpt-5"
|
||||||
```
|
```
|
||||||
|
|
||||||
To restrict Qodo Merge to using only `gemini-2.5-pro`, add this setting:
|
To restrict Qodo Merge to using only `gemini-2.5-pro`, add this setting:
|
||||||
|
|
@ -33,10 +33,9 @@ To restrict Qodo Merge to using only `gemini-2.5-pro`, add this setting:
|
||||||
model="gemini-2.5-pro"
|
model="gemini-2.5-pro"
|
||||||
```
|
```
|
||||||
|
|
||||||
|
To restrict Qodo Merge to using only `claude-4-sonnet`, add this setting:
|
||||||
To restrict Qodo Merge to using only `deepseek-r1` us-hosted, add this setting:
|
|
||||||
|
|
||||||
```toml
|
```toml
|
||||||
[config]
|
[config]
|
||||||
model="deepseek/r1"
|
model="claude-4-sonnet"
|
||||||
```
|
```
|
||||||
|
|
|
||||||
|
|
@ -21,7 +21,7 @@ nav:
|
||||||
- Changing a Model: 'usage-guide/changing_a_model.md'
|
- Changing a Model: 'usage-guide/changing_a_model.md'
|
||||||
- Additional Configurations: 'usage-guide/additional_configurations.md'
|
- Additional Configurations: 'usage-guide/additional_configurations.md'
|
||||||
- Frequently Asked Questions: 'faq/index.md'
|
- Frequently Asked Questions: 'faq/index.md'
|
||||||
- 💎 Qodo Merge Models: 'usage-guide/qodo_merge_models.md'
|
- Qodo Merge Models: 'usage-guide/qodo_merge_models.md'
|
||||||
- Tools:
|
- Tools:
|
||||||
- 'tools/index.md'
|
- 'tools/index.md'
|
||||||
- Describe: 'tools/describe.md'
|
- Describe: 'tools/describe.md'
|
||||||
|
|
@ -34,11 +34,13 @@ nav:
|
||||||
- 💎 Add Documentation: 'tools/documentation.md'
|
- 💎 Add Documentation: 'tools/documentation.md'
|
||||||
- 💎 Analyze: 'tools/analyze.md'
|
- 💎 Analyze: 'tools/analyze.md'
|
||||||
- 💎 CI Feedback: 'tools/ci_feedback.md'
|
- 💎 CI Feedback: 'tools/ci_feedback.md'
|
||||||
|
- 💎 Compliance: 'tools/compliance.md'
|
||||||
- 💎 Custom Prompt: 'tools/custom_prompt.md'
|
- 💎 Custom Prompt: 'tools/custom_prompt.md'
|
||||||
- 💎 Generate Labels: 'tools/custom_labels.md'
|
- 💎 Generate Labels: 'tools/custom_labels.md'
|
||||||
- 💎 Generate Tests: 'tools/test.md'
|
- 💎 Generate Tests: 'tools/test.md'
|
||||||
- 💎 Implement: 'tools/implement.md'
|
- 💎 Implement: 'tools/implement.md'
|
||||||
- 💎 Improve Components: 'tools/improve_component.md'
|
- 💎 Improve Components: 'tools/improve_component.md'
|
||||||
|
- 💎 PR to Ticket: 'tools/pr_to_ticket.md'
|
||||||
- 💎 Scan Repo Discussions: 'tools/scan_repo_discussions.md'
|
- 💎 Scan Repo Discussions: 'tools/scan_repo_discussions.md'
|
||||||
- 💎 Similar Code: 'tools/similar_code.md'
|
- 💎 Similar Code: 'tools/similar_code.md'
|
||||||
- Core Abilities:
|
- Core Abilities:
|
||||||
|
|
@ -46,10 +48,12 @@ nav:
|
||||||
- Auto approval: 'core-abilities/auto_approval.md'
|
- Auto approval: 'core-abilities/auto_approval.md'
|
||||||
- Auto best practices: 'core-abilities/auto_best_practices.md'
|
- Auto best practices: 'core-abilities/auto_best_practices.md'
|
||||||
- Chat on code suggestions: 'core-abilities/chat_on_code_suggestions.md'
|
- Chat on code suggestions: 'core-abilities/chat_on_code_suggestions.md'
|
||||||
|
- Chrome extension: 'chrome-extension/index.md'
|
||||||
- Code validation: 'core-abilities/code_validation.md'
|
- Code validation: 'core-abilities/code_validation.md'
|
||||||
# - Compression strategy: 'core-abilities/compression_strategy.md'
|
# - Compression strategy: 'core-abilities/compression_strategy.md'
|
||||||
- Dynamic context: 'core-abilities/dynamic_context.md'
|
- Dynamic context: 'core-abilities/dynamic_context.md'
|
||||||
- Fetching ticket context: 'core-abilities/fetching_ticket_context.md'
|
- Fetching ticket context: 'core-abilities/fetching_ticket_context.md'
|
||||||
|
- High-level Suggestions: 'core-abilities/high_level_suggestions.md'
|
||||||
- Impact evaluation: 'core-abilities/impact_evaluation.md'
|
- Impact evaluation: 'core-abilities/impact_evaluation.md'
|
||||||
- Incremental Update: 'core-abilities/incremental_update.md'
|
- Incremental Update: 'core-abilities/incremental_update.md'
|
||||||
- Interactivity: 'core-abilities/interactivity.md'
|
- Interactivity: 'core-abilities/interactivity.md'
|
||||||
|
|
@ -57,16 +61,23 @@ nav:
|
||||||
- RAG context enrichment: 'core-abilities/rag_context_enrichment.md'
|
- RAG context enrichment: 'core-abilities/rag_context_enrichment.md'
|
||||||
- Self-reflection: 'core-abilities/self_reflection.md'
|
- Self-reflection: 'core-abilities/self_reflection.md'
|
||||||
- Static code analysis: 'core-abilities/static_code_analysis.md'
|
- Static code analysis: 'core-abilities/static_code_analysis.md'
|
||||||
- Chrome Extension:
|
# - Chrome Extension:
|
||||||
- Qodo Merge Chrome Extension: 'chrome-extension/index.md'
|
# - Qodo Merge Chrome Extension: 'chrome-extension/index.md'
|
||||||
- Features: 'chrome-extension/features.md'
|
# - Features: 'chrome-extension/features.md'
|
||||||
- Data Privacy: 'chrome-extension/data_privacy.md'
|
# - Data Privacy: 'chrome-extension/data_privacy.md'
|
||||||
- Options: 'chrome-extension/options.md'
|
# - Options: 'chrome-extension/options.md'
|
||||||
|
- Qodo Merge CLI:
|
||||||
|
- Overview: 'qodo-merge-cli/index.md'
|
||||||
|
- Installation: 'qodo-merge-cli/installation.md'
|
||||||
|
- Usage: 'qodo-merge-cli/usage.md'
|
||||||
|
#- Features & Usage: 'qodo-merge-cli/features.md'
|
||||||
|
# - Troubleshooting: 'qodo-merge-cli/troubleshooting.md'
|
||||||
- PR Benchmark:
|
- PR Benchmark:
|
||||||
- PR Benchmark: 'pr_benchmark/index.md'
|
- PR Benchmark: 'pr_benchmark/index.md'
|
||||||
- Recent Updates:
|
- Recent Updates:
|
||||||
- Recent Updates: 'recent_updates/index.md'
|
- Recent Updates: 'recent_updates/index.md'
|
||||||
- AI Docs Search: 'ai_search/index.md'
|
- AI Docs Search: 'ai_search/index.md'
|
||||||
|
|
||||||
# - Code Fine-tuning Benchmark: 'finetuning_benchmark/index.md'
|
# - Code Fine-tuning Benchmark: 'finetuning_benchmark/index.md'
|
||||||
|
|
||||||
theme:
|
theme:
|
||||||
|
|
|
||||||
|
|
@ -3,5 +3,5 @@
|
||||||
new Date().getTime(),event:'gtm.js'});var f=d.getElementsByTagName(s)[0],
|
new Date().getTime(),event:'gtm.js'});var f=d.getElementsByTagName(s)[0],
|
||||||
j=d.createElement(s),dl=l!='dataLayer'?'&l='+l:'';j.async=true;j.src=
|
j=d.createElement(s),dl=l!='dataLayer'?'&l='+l:'';j.async=true;j.src=
|
||||||
'https://www.googletagmanager.com/gtm.js?id='+i+dl;f.parentNode.insertBefore(j,f);
|
'https://www.googletagmanager.com/gtm.js?id='+i+dl;f.parentNode.insertBefore(j,f);
|
||||||
})(window,document,'script','dataLayer','GTM-M6PJSFV');</script>
|
})(window,document,'script','dataLayer','GTM-5C9KZBM3');</script>
|
||||||
<!-- End Google Tag Manager -->
|
<!-- End Google Tag Manager -->
|
||||||
|
|
|
||||||
|
|
@ -51,7 +51,7 @@ class PRAgent:
|
||||||
def __init__(self, ai_handler: partial[BaseAiHandler,] = LiteLLMAIHandler):
|
def __init__(self, ai_handler: partial[BaseAiHandler,] = LiteLLMAIHandler):
|
||||||
self.ai_handler = ai_handler # will be initialized in run_action
|
self.ai_handler = ai_handler # will be initialized in run_action
|
||||||
|
|
||||||
async def handle_request(self, pr_url, request, notify=None) -> bool:
|
async def _handle_request(self, pr_url, request, notify=None) -> bool:
|
||||||
# First, apply repo specific settings if exists
|
# First, apply repo specific settings if exists
|
||||||
apply_repo_settings(pr_url)
|
apply_repo_settings(pr_url)
|
||||||
|
|
||||||
|
|
@ -117,3 +117,10 @@ class PRAgent:
|
||||||
else:
|
else:
|
||||||
return False
|
return False
|
||||||
return True
|
return True
|
||||||
|
|
||||||
|
async def handle_request(self, pr_url, request, notify=None) -> bool:
|
||||||
|
try:
|
||||||
|
return await self._handle_request(pr_url, request, notify)
|
||||||
|
except:
|
||||||
|
get_logger().exception("Failed to process the command.")
|
||||||
|
return False
|
||||||
|
|
|
||||||
|
|
@ -28,6 +28,15 @@ MAX_TOKENS = {
|
||||||
'gpt-4.1-mini-2025-04-14': 1047576,
|
'gpt-4.1-mini-2025-04-14': 1047576,
|
||||||
'gpt-4.1-nano': 1047576,
|
'gpt-4.1-nano': 1047576,
|
||||||
'gpt-4.1-nano-2025-04-14': 1047576,
|
'gpt-4.1-nano-2025-04-14': 1047576,
|
||||||
|
'gpt-5-nano': 200000, # 200K, but may be limited by config.max_model_tokens
|
||||||
|
'gpt-5-mini': 200000, # 200K, but may be limited by config.max_model_tokens
|
||||||
|
'gpt-5': 200000,
|
||||||
|
'gpt-5-2025-08-07': 200000,
|
||||||
|
'gpt-5.1': 200000,
|
||||||
|
'gpt-5.1-2025-11-13': 200000,
|
||||||
|
'gpt-5.1-chat-latest': 200000,
|
||||||
|
'gpt-5.1-codex': 200000,
|
||||||
|
'gpt-5.1-codex-mini': 200000,
|
||||||
'o1-mini': 128000, # 128K, but may be limited by config.max_model_tokens
|
'o1-mini': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||||
'o1-mini-2024-09-12': 128000, # 128K, but may be limited by config.max_model_tokens
|
'o1-mini-2024-09-12': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||||
'o1-preview': 128000, # 128K, but may be limited by config.max_model_tokens
|
'o1-preview': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||||
|
|
@ -45,6 +54,7 @@ MAX_TOKENS = {
|
||||||
'command-nightly': 4096,
|
'command-nightly': 4096,
|
||||||
'deepseek/deepseek-chat': 128000, # 128K, but may be limited by config.max_model_tokens
|
'deepseek/deepseek-chat': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||||
'deepseek/deepseek-reasoner': 64000, # 64K, but may be limited by config.max_model_tokens
|
'deepseek/deepseek-reasoner': 64000, # 64K, but may be limited by config.max_model_tokens
|
||||||
|
'openai/qwq-plus': 131072, # 131K context length, but may be limited by config.max_model_tokens
|
||||||
'replicate/llama-2-70b-chat:2c1608e18606fad2812020dc541930f2d0495ce32eee50074220b87300bc16e1': 4096,
|
'replicate/llama-2-70b-chat:2c1608e18606fad2812020dc541930f2d0495ce32eee50074220b87300bc16e1': 4096,
|
||||||
'meta-llama/Llama-2-7b-chat-hf': 4096,
|
'meta-llama/Llama-2-7b-chat-hf': 4096,
|
||||||
'vertex_ai/codechat-bison': 6144,
|
'vertex_ai/codechat-bison': 6144,
|
||||||
|
|
@ -58,23 +68,28 @@ MAX_TOKENS = {
|
||||||
'vertex_ai/claude-3-5-sonnet-v2@20241022': 100000,
|
'vertex_ai/claude-3-5-sonnet-v2@20241022': 100000,
|
||||||
'vertex_ai/claude-3-7-sonnet@20250219': 200000,
|
'vertex_ai/claude-3-7-sonnet@20250219': 200000,
|
||||||
'vertex_ai/claude-sonnet-4@20250514': 200000,
|
'vertex_ai/claude-sonnet-4@20250514': 200000,
|
||||||
|
'vertex_ai/claude-sonnet-4-5@20250929': 200000,
|
||||||
'vertex_ai/gemini-1.5-pro': 1048576,
|
'vertex_ai/gemini-1.5-pro': 1048576,
|
||||||
'vertex_ai/gemini-2.5-pro-preview-03-25': 1048576,
|
'vertex_ai/gemini-2.5-pro-preview-03-25': 1048576,
|
||||||
'vertex_ai/gemini-2.5-pro-preview-05-06': 1048576,
|
'vertex_ai/gemini-2.5-pro-preview-05-06': 1048576,
|
||||||
'vertex_ai/gemini-2.5-pro-preview-06-05': 1048576,
|
'vertex_ai/gemini-2.5-pro-preview-06-05': 1048576,
|
||||||
|
'vertex_ai/gemini-2.5-pro': 1048576,
|
||||||
'vertex_ai/gemini-1.5-flash': 1048576,
|
'vertex_ai/gemini-1.5-flash': 1048576,
|
||||||
'vertex_ai/gemini-2.0-flash': 1048576,
|
'vertex_ai/gemini-2.0-flash': 1048576,
|
||||||
'vertex_ai/gemini-2.5-flash-preview-04-17': 1048576,
|
'vertex_ai/gemini-2.5-flash-preview-04-17': 1048576,
|
||||||
'vertex_ai/gemini-2.5-flash-preview-05-20': 1048576,
|
'vertex_ai/gemini-2.5-flash-preview-05-20': 1048576,
|
||||||
|
'vertex_ai/gemini-2.5-flash': 1048576,
|
||||||
'vertex_ai/gemma2': 8200,
|
'vertex_ai/gemma2': 8200,
|
||||||
'gemini/gemini-1.5-pro': 1048576,
|
'gemini/gemini-1.5-pro': 1048576,
|
||||||
'gemini/gemini-1.5-flash': 1048576,
|
'gemini/gemini-1.5-flash': 1048576,
|
||||||
'gemini/gemini-2.0-flash': 1048576,
|
'gemini/gemini-2.0-flash': 1048576,
|
||||||
'gemini/gemini-2.5-flash-preview-04-17': 1048576,
|
'gemini/gemini-2.5-flash-preview-04-17': 1048576,
|
||||||
'gemini/gemini-2.5-flash-preview-05-20': 1048576,
|
'gemini/gemini-2.5-flash-preview-05-20': 1048576,
|
||||||
|
'gemini/gemini-2.5-flash': 1048576,
|
||||||
'gemini/gemini-2.5-pro-preview-03-25': 1048576,
|
'gemini/gemini-2.5-pro-preview-03-25': 1048576,
|
||||||
'gemini/gemini-2.5-pro-preview-05-06': 1048576,
|
'gemini/gemini-2.5-pro-preview-05-06': 1048576,
|
||||||
'gemini/gemini-2.5-pro-preview-06-05': 1048576,
|
'gemini/gemini-2.5-pro-preview-06-05': 1048576,
|
||||||
|
'gemini/gemini-2.5-pro': 1048576,
|
||||||
'codechat-bison': 6144,
|
'codechat-bison': 6144,
|
||||||
'codechat-bison-32k': 32000,
|
'codechat-bison-32k': 32000,
|
||||||
'anthropic.claude-instant-v1': 100000,
|
'anthropic.claude-instant-v1': 100000,
|
||||||
|
|
@ -86,6 +101,7 @@ MAX_TOKENS = {
|
||||||
'anthropic/claude-3-5-sonnet-20241022': 100000,
|
'anthropic/claude-3-5-sonnet-20241022': 100000,
|
||||||
'anthropic/claude-3-7-sonnet-20250219': 200000,
|
'anthropic/claude-3-7-sonnet-20250219': 200000,
|
||||||
'anthropic/claude-sonnet-4-20250514': 200000,
|
'anthropic/claude-sonnet-4-20250514': 200000,
|
||||||
|
'anthropic/claude-sonnet-4-5-20250929': 200000,
|
||||||
'claude-3-7-sonnet-20250219': 200000,
|
'claude-3-7-sonnet-20250219': 200000,
|
||||||
'anthropic/claude-3-5-haiku-20241022': 100000,
|
'anthropic/claude-3-5-haiku-20241022': 100000,
|
||||||
'bedrock/anthropic.claude-instant-v1': 100000,
|
'bedrock/anthropic.claude-instant-v1': 100000,
|
||||||
|
|
@ -99,22 +115,29 @@ MAX_TOKENS = {
|
||||||
'bedrock/anthropic.claude-3-5-sonnet-20241022-v2:0': 100000,
|
'bedrock/anthropic.claude-3-5-sonnet-20241022-v2:0': 100000,
|
||||||
'bedrock/anthropic.claude-3-7-sonnet-20250219-v1:0': 200000,
|
'bedrock/anthropic.claude-3-7-sonnet-20250219-v1:0': 200000,
|
||||||
'bedrock/anthropic.claude-sonnet-4-20250514-v1:0': 200000,
|
'bedrock/anthropic.claude-sonnet-4-20250514-v1:0': 200000,
|
||||||
|
'bedrock/anthropic.claude-sonnet-4-5-20250929-v1:0': 200000,
|
||||||
"bedrock/us.anthropic.claude-opus-4-20250514-v1:0": 200000,
|
"bedrock/us.anthropic.claude-opus-4-20250514-v1:0": 200000,
|
||||||
"bedrock/us.anthropic.claude-3-5-sonnet-20241022-v2:0": 100000,
|
"bedrock/us.anthropic.claude-3-5-sonnet-20241022-v2:0": 100000,
|
||||||
"bedrock/us.anthropic.claude-3-7-sonnet-20250219-v1:0": 200000,
|
"bedrock/us.anthropic.claude-3-7-sonnet-20250219-v1:0": 200000,
|
||||||
"bedrock/us.anthropic.claude-sonnet-4-20250514-v1:0": 200000,
|
"bedrock/us.anthropic.claude-sonnet-4-20250514-v1:0": 200000,
|
||||||
|
"bedrock/us.anthropic.claude-sonnet-4-5-20250929-v1:0": 200000,
|
||||||
"bedrock/apac.anthropic.claude-3-5-sonnet-20241022-v2:0": 100000,
|
"bedrock/apac.anthropic.claude-3-5-sonnet-20241022-v2:0": 100000,
|
||||||
"bedrock/apac.anthropic.claude-3-7-sonnet-20250219-v1:0": 200000,
|
"bedrock/apac.anthropic.claude-3-7-sonnet-20250219-v1:0": 200000,
|
||||||
"bedrock/apac.anthropic.claude-sonnet-4-20250514-v1:0": 200000,
|
"bedrock/apac.anthropic.claude-sonnet-4-20250514-v1:0": 200000,
|
||||||
|
"bedrock/jp.anthropic.claude-sonnet-4-5-20250929-v1:0": 200000,
|
||||||
|
"bedrock/global.anthropic.claude-sonnet-4-5-20250929-v1:0": 200000,
|
||||||
'claude-3-5-sonnet': 100000,
|
'claude-3-5-sonnet': 100000,
|
||||||
'groq/meta-llama/llama-4-scout-17b-16e-instruct': 131072,
|
'bedrock/us.meta.llama4-scout-17b-instruct-v1:0': 128000,
|
||||||
|
'bedrock/us.meta.llama4-maverick-17b-instruct-v1:0': 128000,
|
||||||
|
'groq/openai/gpt-oss-120b': 131072,
|
||||||
|
'groq/openai/gpt-oss-20b': 131072,
|
||||||
|
'groq/qwen/qwen3-32b': 131000,
|
||||||
|
'groq/moonshotai/kimi-k2-instruct': 131072,
|
||||||
|
'groq/deepseek-r1-distill-llama-70b': 128000,
|
||||||
'groq/meta-llama/llama-4-maverick-17b-128e-instruct': 131072,
|
'groq/meta-llama/llama-4-maverick-17b-128e-instruct': 131072,
|
||||||
'groq/llama3-8b-8192': 8192,
|
'groq/meta-llama/llama-4-scout-17b-16e-instruct': 131072,
|
||||||
'groq/llama3-70b-8192': 8192,
|
|
||||||
'groq/llama-3.1-8b-instant': 8192,
|
|
||||||
'groq/llama-3.3-70b-versatile': 128000,
|
'groq/llama-3.3-70b-versatile': 128000,
|
||||||
'groq/mixtral-8x7b-32768': 32768,
|
'groq/llama-3.1-8b-instant': 128000,
|
||||||
'groq/gemma2-9b-it': 8192,
|
|
||||||
'xai/grok-2': 131072,
|
'xai/grok-2': 131072,
|
||||||
'xai/grok-2-1212': 131072,
|
'xai/grok-2-1212': 131072,
|
||||||
'xai/grok-2-latest': 131072,
|
'xai/grok-2-latest': 131072,
|
||||||
|
|
@ -187,3 +210,8 @@ CLAUDE_EXTENDED_THINKING_MODELS = [
|
||||||
"anthropic/claude-3-7-sonnet-20250219",
|
"anthropic/claude-3-7-sonnet-20250219",
|
||||||
"claude-3-7-sonnet-20250219"
|
"claude-3-7-sonnet-20250219"
|
||||||
]
|
]
|
||||||
|
|
||||||
|
# Models that require streaming mode
|
||||||
|
STREAMING_REQUIRED_MODELS = [
|
||||||
|
"openai/qwq-plus"
|
||||||
|
]
|
||||||
|
|
|
||||||
|
|
@ -5,14 +5,16 @@ import requests
|
||||||
from litellm import acompletion
|
from litellm import acompletion
|
||||||
from tenacity import retry, retry_if_exception_type, retry_if_not_exception_type, stop_after_attempt
|
from tenacity import retry, retry_if_exception_type, retry_if_not_exception_type, stop_after_attempt
|
||||||
|
|
||||||
from pr_agent.algo import CLAUDE_EXTENDED_THINKING_MODELS, NO_SUPPORT_TEMPERATURE_MODELS, SUPPORT_REASONING_EFFORT_MODELS, USER_MESSAGE_ONLY_MODELS
|
from pr_agent.algo import CLAUDE_EXTENDED_THINKING_MODELS, NO_SUPPORT_TEMPERATURE_MODELS, SUPPORT_REASONING_EFFORT_MODELS, USER_MESSAGE_ONLY_MODELS, STREAMING_REQUIRED_MODELS
|
||||||
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||||
|
from pr_agent.algo.ai_handlers.litellm_helpers import _handle_streaming_response, MockResponse, _get_azure_ad_token, \
|
||||||
|
_process_litellm_extra_body
|
||||||
from pr_agent.algo.utils import ReasoningEffort, get_version
|
from pr_agent.algo.utils import ReasoningEffort, get_version
|
||||||
from pr_agent.config_loader import get_settings
|
from pr_agent.config_loader import get_settings
|
||||||
from pr_agent.log import get_logger
|
from pr_agent.log import get_logger
|
||||||
import json
|
import json
|
||||||
|
|
||||||
OPENAI_RETRIES = 5
|
MODEL_RETRIES = 2
|
||||||
|
|
||||||
|
|
||||||
class LiteLLMAIHandler(BaseAiHandler):
|
class LiteLLMAIHandler(BaseAiHandler):
|
||||||
|
|
@ -30,7 +32,9 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||||
self.azure = False
|
self.azure = False
|
||||||
self.api_base = None
|
self.api_base = None
|
||||||
self.repetition_penalty = None
|
self.repetition_penalty = None
|
||||||
|
|
||||||
|
if get_settings().get("LITELLM.DISABLE_AIOHTTP", False):
|
||||||
|
litellm.disable_aiohttp_transport = True
|
||||||
if get_settings().get("OPENAI.KEY", None):
|
if get_settings().get("OPENAI.KEY", None):
|
||||||
openai.api_key = get_settings().openai.key
|
openai.api_key = get_settings().openai.key
|
||||||
litellm.openai_key = get_settings().openai.key
|
litellm.openai_key = get_settings().openai.key
|
||||||
|
|
@ -110,7 +114,7 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||||
if get_settings().get("AZURE_AD.CLIENT_ID", None):
|
if get_settings().get("AZURE_AD.CLIENT_ID", None):
|
||||||
self.azure = True
|
self.azure = True
|
||||||
# Generate access token using Azure AD credentials from settings
|
# Generate access token using Azure AD credentials from settings
|
||||||
access_token = self._get_azure_ad_token()
|
access_token = _get_azure_ad_token()
|
||||||
litellm.api_key = access_token
|
litellm.api_key = access_token
|
||||||
openai.api_key = access_token
|
openai.api_key = access_token
|
||||||
|
|
||||||
|
|
@ -143,25 +147,8 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||||
# Models that support extended thinking
|
# Models that support extended thinking
|
||||||
self.claude_extended_thinking_models = CLAUDE_EXTENDED_THINKING_MODELS
|
self.claude_extended_thinking_models = CLAUDE_EXTENDED_THINKING_MODELS
|
||||||
|
|
||||||
def _get_azure_ad_token(self):
|
# Models that require streaming
|
||||||
"""
|
self.streaming_required_models = STREAMING_REQUIRED_MODELS
|
||||||
Generates an access token using Azure AD credentials from settings.
|
|
||||||
Returns:
|
|
||||||
str: The access token
|
|
||||||
"""
|
|
||||||
from azure.identity import ClientSecretCredential
|
|
||||||
try:
|
|
||||||
credential = ClientSecretCredential(
|
|
||||||
tenant_id=get_settings().azure_ad.tenant_id,
|
|
||||||
client_id=get_settings().azure_ad.client_id,
|
|
||||||
client_secret=get_settings().azure_ad.client_secret
|
|
||||||
)
|
|
||||||
# Get token for Azure OpenAI service
|
|
||||||
token = credential.get_token("https://cognitiveservices.azure.com/.default")
|
|
||||||
return token.token
|
|
||||||
except Exception as e:
|
|
||||||
get_logger().error(f"Failed to get Azure AD token: {e}")
|
|
||||||
raise
|
|
||||||
|
|
||||||
def prepare_logs(self, response, system, user, resp, finish_reason):
|
def prepare_logs(self, response, system, user, resp, finish_reason):
|
||||||
response_log = response.dict().copy()
|
response_log = response.dict().copy()
|
||||||
|
|
@ -275,7 +262,7 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||||
|
|
||||||
@retry(
|
@retry(
|
||||||
retry=retry_if_exception_type(openai.APIError) & retry_if_not_exception_type(openai.RateLimitError),
|
retry=retry_if_exception_type(openai.APIError) & retry_if_not_exception_type(openai.RateLimitError),
|
||||||
stop=stop_after_attempt(OPENAI_RETRIES),
|
stop=stop_after_attempt(MODEL_RETRIES),
|
||||||
)
|
)
|
||||||
async def chat_completion(self, model: str, system: str, user: str, temperature: float = 0.2, img_path: str = None):
|
async def chat_completion(self, model: str, system: str, user: str, temperature: float = 0.2, img_path: str = None):
|
||||||
try:
|
try:
|
||||||
|
|
@ -303,6 +290,21 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||||
messages[1]["content"] = [{"type": "text", "text": messages[1]["content"]},
|
messages[1]["content"] = [{"type": "text", "text": messages[1]["content"]},
|
||||||
{"type": "image_url", "image_url": {"url": img_path}}]
|
{"type": "image_url", "image_url": {"url": img_path}}]
|
||||||
|
|
||||||
|
thinking_kwargs_gpt5 = None
|
||||||
|
if model.startswith('gpt-5'):
|
||||||
|
if model.endswith('_thinking'):
|
||||||
|
thinking_kwargs_gpt5 = {
|
||||||
|
"reasoning_effort": 'low',
|
||||||
|
"allowed_openai_params": ["reasoning_effort"],
|
||||||
|
}
|
||||||
|
else:
|
||||||
|
thinking_kwargs_gpt5 = {
|
||||||
|
"reasoning_effort": 'minimal',
|
||||||
|
"allowed_openai_params": ["reasoning_effort"],
|
||||||
|
}
|
||||||
|
model = 'openai/'+model.replace('_thinking', '') # remove _thinking suffix
|
||||||
|
|
||||||
|
|
||||||
# Currently, some models do not support a separate system and user prompts
|
# Currently, some models do not support a separate system and user prompts
|
||||||
if model in self.user_message_only_models or get_settings().config.custom_reasoning_model:
|
if model in self.user_message_only_models or get_settings().config.custom_reasoning_model:
|
||||||
user = f"{system}\n\n\n{user}"
|
user = f"{system}\n\n\n{user}"
|
||||||
|
|
@ -330,6 +332,11 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||||
# get_logger().info(f"Adding temperature with value {temperature} to model {model}.")
|
# get_logger().info(f"Adding temperature with value {temperature} to model {model}.")
|
||||||
kwargs["temperature"] = temperature
|
kwargs["temperature"] = temperature
|
||||||
|
|
||||||
|
if thinking_kwargs_gpt5:
|
||||||
|
kwargs.update(thinking_kwargs_gpt5)
|
||||||
|
if 'temperature' in kwargs:
|
||||||
|
del kwargs['temperature']
|
||||||
|
|
||||||
# Add reasoning_effort if model supports it
|
# Add reasoning_effort if model supports it
|
||||||
if (model in self.support_reasoning_models):
|
if (model in self.support_reasoning_models):
|
||||||
supported_reasoning_efforts = [ReasoningEffort.HIGH.value, ReasoningEffort.MEDIUM.value, ReasoningEffort.LOW.value]
|
supported_reasoning_efforts = [ReasoningEffort.HIGH.value, ReasoningEffort.MEDIUM.value, ReasoningEffort.LOW.value]
|
||||||
|
|
@ -364,13 +371,24 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||||
raise ValueError(f"LITELLM.EXTRA_HEADERS contains invalid JSON: {str(e)}")
|
raise ValueError(f"LITELLM.EXTRA_HEADERS contains invalid JSON: {str(e)}")
|
||||||
kwargs["extra_headers"] = litellm_extra_headers
|
kwargs["extra_headers"] = litellm_extra_headers
|
||||||
|
|
||||||
|
# Support for custom OpenAI body fields (e.g., Flex Processing)
|
||||||
|
kwargs = _process_litellm_extra_body(kwargs)
|
||||||
|
|
||||||
|
# Support for Bedrock custom inference profile via model_id
|
||||||
|
model_id = get_settings().get("litellm.model_id")
|
||||||
|
if model_id and 'bedrock/' in model:
|
||||||
|
kwargs["model_id"] = model_id
|
||||||
|
get_logger().info(f"Using Bedrock custom inference profile: {model_id}")
|
||||||
|
|
||||||
get_logger().debug("Prompts", artifact={"system": system, "user": user})
|
get_logger().debug("Prompts", artifact={"system": system, "user": user})
|
||||||
|
|
||||||
if get_settings().config.verbosity_level >= 2:
|
if get_settings().config.verbosity_level >= 2:
|
||||||
get_logger().info(f"\nSystem prompt:\n{system}")
|
get_logger().info(f"\nSystem prompt:\n{system}")
|
||||||
get_logger().info(f"\nUser prompt:\n{user}")
|
get_logger().info(f"\nUser prompt:\n{user}")
|
||||||
|
|
||||||
response = await acompletion(**kwargs)
|
# Get completion with automatic streaming detection
|
||||||
|
resp, finish_reason, response_obj = await self._get_completion(**kwargs)
|
||||||
|
|
||||||
except openai.RateLimitError as e:
|
except openai.RateLimitError as e:
|
||||||
get_logger().error(f"Rate limit error during LLM inference: {e}")
|
get_logger().error(f"Rate limit error during LLM inference: {e}")
|
||||||
raise
|
raise
|
||||||
|
|
@ -380,19 +398,36 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
get_logger().warning(f"Unknown error during LLM inference: {e}")
|
get_logger().warning(f"Unknown error during LLM inference: {e}")
|
||||||
raise openai.APIError from e
|
raise openai.APIError from e
|
||||||
if response is None or len(response["choices"]) == 0:
|
|
||||||
raise openai.APIError
|
|
||||||
else:
|
|
||||||
resp = response["choices"][0]['message']['content']
|
|
||||||
finish_reason = response["choices"][0]["finish_reason"]
|
|
||||||
get_logger().debug(f"\nAI response:\n{resp}")
|
|
||||||
|
|
||||||
# log the full response for debugging
|
get_logger().debug(f"\nAI response:\n{resp}")
|
||||||
response_log = self.prepare_logs(response, system, user, resp, finish_reason)
|
|
||||||
get_logger().debug("Full_response", artifact=response_log)
|
|
||||||
|
|
||||||
# for CLI debugging
|
# log the full response for debugging
|
||||||
if get_settings().config.verbosity_level >= 2:
|
response_log = self.prepare_logs(response_obj, system, user, resp, finish_reason)
|
||||||
get_logger().info(f"\nAI response:\n{resp}")
|
get_logger().debug("Full_response", artifact=response_log)
|
||||||
|
|
||||||
|
# for CLI debugging
|
||||||
|
if get_settings().config.verbosity_level >= 2:
|
||||||
|
get_logger().info(f"\nAI response:\n{resp}")
|
||||||
|
|
||||||
return resp, finish_reason
|
return resp, finish_reason
|
||||||
|
|
||||||
|
async def _get_completion(self, **kwargs):
|
||||||
|
"""
|
||||||
|
Wrapper that automatically handles streaming for required models.
|
||||||
|
"""
|
||||||
|
model = kwargs["model"]
|
||||||
|
if model in self.streaming_required_models:
|
||||||
|
kwargs["stream"] = True
|
||||||
|
get_logger().info(f"Using streaming mode for model {model}")
|
||||||
|
response = await acompletion(**kwargs)
|
||||||
|
resp, finish_reason = await _handle_streaming_response(response)
|
||||||
|
# Create MockResponse for streaming since we don't have the full response object
|
||||||
|
mock_response = MockResponse(resp, finish_reason)
|
||||||
|
return resp, finish_reason, mock_response
|
||||||
|
else:
|
||||||
|
response = await acompletion(**kwargs)
|
||||||
|
if response is None or len(response["choices"]) == 0:
|
||||||
|
raise openai.APIError
|
||||||
|
return (response["choices"][0]['message']['content'],
|
||||||
|
response["choices"][0]["finish_reason"],
|
||||||
|
response)
|
||||||
|
|
|
||||||
112
pr_agent/algo/ai_handlers/litellm_helpers.py
Normal file
112
pr_agent/algo/ai_handlers/litellm_helpers.py
Normal file
|
|
@ -0,0 +1,112 @@
|
||||||
|
import json
|
||||||
|
|
||||||
|
import openai
|
||||||
|
|
||||||
|
from pr_agent.config_loader import get_settings
|
||||||
|
from pr_agent.log import get_logger
|
||||||
|
|
||||||
|
|
||||||
|
async def _handle_streaming_response(response):
|
||||||
|
"""
|
||||||
|
Handle streaming response from acompletion and collect the full response.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
response: The streaming response object from acompletion
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
tuple: (full_response_content, finish_reason)
|
||||||
|
"""
|
||||||
|
full_response = ""
|
||||||
|
finish_reason = None
|
||||||
|
|
||||||
|
try:
|
||||||
|
async for chunk in response:
|
||||||
|
if chunk.choices and len(chunk.choices) > 0:
|
||||||
|
choice = chunk.choices[0]
|
||||||
|
delta = choice.delta
|
||||||
|
content = getattr(delta, 'content', None)
|
||||||
|
if content:
|
||||||
|
full_response += content
|
||||||
|
if choice.finish_reason:
|
||||||
|
finish_reason = choice.finish_reason
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().error(f"Error handling streaming response: {e}")
|
||||||
|
raise
|
||||||
|
|
||||||
|
if not full_response and finish_reason is None:
|
||||||
|
get_logger().warning("Streaming response resulted in empty content with no finish reason")
|
||||||
|
raise openai.APIError("Empty streaming response received without proper completion")
|
||||||
|
elif not full_response and finish_reason:
|
||||||
|
get_logger().debug(f"Streaming response resulted in empty content but completed with finish_reason: {finish_reason}")
|
||||||
|
raise openai.APIError(f"Streaming response completed with finish_reason '{finish_reason}' but no content received")
|
||||||
|
return full_response, finish_reason
|
||||||
|
|
||||||
|
|
||||||
|
class MockResponse:
|
||||||
|
"""Mock response object for streaming models to enable consistent logging."""
|
||||||
|
|
||||||
|
def __init__(self, resp, finish_reason):
|
||||||
|
self._data = {
|
||||||
|
"choices": [
|
||||||
|
{
|
||||||
|
"message": {"content": resp},
|
||||||
|
"finish_reason": finish_reason
|
||||||
|
}
|
||||||
|
]
|
||||||
|
}
|
||||||
|
|
||||||
|
def dict(self):
|
||||||
|
return self._data
|
||||||
|
|
||||||
|
|
||||||
|
def _get_azure_ad_token():
|
||||||
|
"""
|
||||||
|
Generates an access token using Azure AD credentials from settings.
|
||||||
|
Returns:
|
||||||
|
str: The access token
|
||||||
|
"""
|
||||||
|
from azure.identity import ClientSecretCredential
|
||||||
|
try:
|
||||||
|
credential = ClientSecretCredential(
|
||||||
|
tenant_id=get_settings().azure_ad.tenant_id,
|
||||||
|
client_id=get_settings().azure_ad.client_id,
|
||||||
|
client_secret=get_settings().azure_ad.client_secret
|
||||||
|
)
|
||||||
|
# Get token for Azure OpenAI service
|
||||||
|
token = credential.get_token("https://cognitiveservices.azure.com/.default")
|
||||||
|
return token.token
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().error(f"Failed to get Azure AD token: {e}")
|
||||||
|
raise
|
||||||
|
|
||||||
|
|
||||||
|
def _process_litellm_extra_body(kwargs: dict) -> dict:
|
||||||
|
"""
|
||||||
|
Process LITELLM.EXTRA_BODY configuration and update kwargs accordingly.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
kwargs: The current kwargs dictionary to update
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
Updated kwargs dictionary
|
||||||
|
|
||||||
|
Raises:
|
||||||
|
ValueError: If extra_body contains invalid JSON, unsupported keys, or colliding keys
|
||||||
|
"""
|
||||||
|
allowed_extra_body_keys = {"processing_mode", "service_tier"}
|
||||||
|
extra_body = getattr(getattr(get_settings(), "litellm", None), "extra_body", None)
|
||||||
|
if extra_body:
|
||||||
|
try:
|
||||||
|
litellm_extra_body = json.loads(extra_body)
|
||||||
|
if not isinstance(litellm_extra_body, dict):
|
||||||
|
raise ValueError("LITELLM.EXTRA_BODY must be a JSON object")
|
||||||
|
unsupported_keys = set(litellm_extra_body.keys()) - allowed_extra_body_keys
|
||||||
|
if unsupported_keys:
|
||||||
|
raise ValueError(f"LITELLM.EXTRA_BODY contains unsupported keys: {', '.join(unsupported_keys)}. Allowed keys: {', '.join(allowed_extra_body_keys)}")
|
||||||
|
colliding_keys = kwargs.keys() & litellm_extra_body.keys()
|
||||||
|
if colliding_keys:
|
||||||
|
raise ValueError(f"LITELLM.EXTRA_BODY cannot override existing parameters: {', '.join(colliding_keys)}")
|
||||||
|
kwargs.update(litellm_extra_body)
|
||||||
|
except json.JSONDecodeError as e:
|
||||||
|
raise ValueError(f"LITELLM.EXTRA_BODY contains invalid JSON: {str(e)}")
|
||||||
|
return kwargs
|
||||||
|
|
@ -2,6 +2,7 @@ import fnmatch
|
||||||
import re
|
import re
|
||||||
|
|
||||||
from pr_agent.config_loader import get_settings
|
from pr_agent.config_loader import get_settings
|
||||||
|
from pr_agent.log import get_logger
|
||||||
|
|
||||||
|
|
||||||
def filter_ignored(files, platform = 'github'):
|
def filter_ignored(files, platform = 'github'):
|
||||||
|
|
@ -17,7 +18,17 @@ def filter_ignored(files, platform = 'github'):
|
||||||
glob_setting = get_settings().ignore.glob
|
glob_setting = get_settings().ignore.glob
|
||||||
if isinstance(glob_setting, str): # --ignore.glob=[.*utils.py], --ignore.glob=.*utils.py
|
if isinstance(glob_setting, str): # --ignore.glob=[.*utils.py], --ignore.glob=.*utils.py
|
||||||
glob_setting = glob_setting.strip('[]').split(",")
|
glob_setting = glob_setting.strip('[]').split(",")
|
||||||
patterns += [fnmatch.translate(glob) for glob in glob_setting]
|
patterns += translate_globs_to_regexes(glob_setting)
|
||||||
|
|
||||||
|
code_generators = get_settings().config.get('ignore_language_framework', [])
|
||||||
|
if isinstance(code_generators, str):
|
||||||
|
get_logger().warning("'ignore_language_framework' should be a list. Skipping language framework filtering.")
|
||||||
|
code_generators = []
|
||||||
|
for cg in code_generators:
|
||||||
|
glob_patterns = get_settings().generated_code.get(cg, [])
|
||||||
|
if isinstance(glob_patterns, str):
|
||||||
|
glob_patterns = [glob_patterns]
|
||||||
|
patterns += translate_globs_to_regexes(glob_patterns)
|
||||||
|
|
||||||
# compile all valid patterns
|
# compile all valid patterns
|
||||||
compiled_patterns = []
|
compiled_patterns = []
|
||||||
|
|
@ -45,6 +56,8 @@ def filter_ignored(files, platform = 'github'):
|
||||||
files_o.append(f)
|
files_o.append(f)
|
||||||
continue
|
continue
|
||||||
files = files_o
|
files = files_o
|
||||||
|
elif platform == 'bitbucket_server':
|
||||||
|
files = [f for f in files if f.get('path', {}).get('toString') and not r.match(f['path']['toString'])]
|
||||||
elif platform == 'gitlab':
|
elif platform == 'gitlab':
|
||||||
# files = [f for f in files if (f['new_path'] and not r.match(f['new_path']))]
|
# files = [f for f in files if (f['new_path'] and not r.match(f['new_path']))]
|
||||||
files_o = []
|
files_o = []
|
||||||
|
|
@ -66,3 +79,11 @@ def filter_ignored(files, platform = 'github'):
|
||||||
print(f"Could not filter file list: {e}")
|
print(f"Could not filter file list: {e}")
|
||||||
|
|
||||||
return files
|
return files
|
||||||
|
|
||||||
|
def translate_globs_to_regexes(globs: list):
|
||||||
|
regexes = []
|
||||||
|
for pattern in globs:
|
||||||
|
regexes.append(fnmatch.translate(pattern))
|
||||||
|
if pattern.startswith("**/"): # cover root-level files
|
||||||
|
regexes.append(fnmatch.translate(pattern[3:]))
|
||||||
|
return regexes
|
||||||
|
|
|
||||||
|
|
@ -329,12 +329,13 @@ async def retry_with_fallback_models(f: Callable, model_type: ModelType = ModelT
|
||||||
)
|
)
|
||||||
get_settings().set("openai.deployment_id", deployment_id)
|
get_settings().set("openai.deployment_id", deployment_id)
|
||||||
return await f(model)
|
return await f(model)
|
||||||
except:
|
except Exception as e:
|
||||||
get_logger().warning(
|
get_logger().warning(
|
||||||
f"Failed to generate prediction with {model}"
|
f"Failed to generate prediction with {model}",
|
||||||
|
artifact={"error": e},
|
||||||
)
|
)
|
||||||
if i == len(all_models) - 1: # If it's the last iteration
|
if i == len(all_models) - 1: # If it's the last iteration
|
||||||
raise Exception(f"Failed to generate prediction with any model of {all_models}")
|
raise Exception(f"Failed to generate prediction with any model of {all_models}") from e
|
||||||
|
|
||||||
|
|
||||||
def _get_all_models(model_type: ModelType = ModelType.REGULAR) -> List[str]:
|
def _get_all_models(model_type: ModelType = ModelType.REGULAR) -> List[str]:
|
||||||
|
|
@ -398,11 +399,6 @@ def get_pr_multi_diffs(git_provider: GitProvider,
|
||||||
# Sort files by main language
|
# Sort files by main language
|
||||||
pr_languages = sort_files_by_main_languages(git_provider.get_languages(), diff_files)
|
pr_languages = sort_files_by_main_languages(git_provider.get_languages(), diff_files)
|
||||||
|
|
||||||
# Sort files within each language group by tokens in descending order
|
|
||||||
sorted_files = []
|
|
||||||
for lang in pr_languages:
|
|
||||||
sorted_files.extend(sorted(lang['files'], key=lambda x: x.tokens, reverse=True))
|
|
||||||
|
|
||||||
# Get the maximum number of extra lines before and after the patch
|
# Get the maximum number of extra lines before and after the patch
|
||||||
PATCH_EXTRA_LINES_BEFORE = get_settings().config.patch_extra_lines_before
|
PATCH_EXTRA_LINES_BEFORE = get_settings().config.patch_extra_lines_before
|
||||||
PATCH_EXTRA_LINES_AFTER = get_settings().config.patch_extra_lines_after
|
PATCH_EXTRA_LINES_AFTER = get_settings().config.patch_extra_lines_after
|
||||||
|
|
@ -420,6 +416,11 @@ def get_pr_multi_diffs(git_provider: GitProvider,
|
||||||
if total_tokens + OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD < get_max_tokens(model):
|
if total_tokens + OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD < get_max_tokens(model):
|
||||||
return ["\n".join(patches_extended)] if patches_extended else []
|
return ["\n".join(patches_extended)] if patches_extended else []
|
||||||
|
|
||||||
|
# Sort files within each language group by tokens in descending order
|
||||||
|
sorted_files = []
|
||||||
|
for lang in pr_languages:
|
||||||
|
sorted_files.extend(sorted(lang['files'], key=lambda x: x.tokens, reverse=True))
|
||||||
|
|
||||||
patches = []
|
patches = []
|
||||||
final_diff_list = []
|
final_diff_list = []
|
||||||
total_tokens = token_handler.prompt_tokens
|
total_tokens = token_handler.prompt_tokens
|
||||||
|
|
|
||||||
|
|
@ -70,7 +70,8 @@ class ReasoningEffort(str, Enum):
|
||||||
|
|
||||||
|
|
||||||
class PRDescriptionHeader(str, Enum):
|
class PRDescriptionHeader(str, Enum):
|
||||||
CHANGES_WALKTHROUGH = "### **Changes walkthrough** 📝"
|
DIAGRAM_WALKTHROUGH = "Diagram Walkthrough"
|
||||||
|
FILE_WALKTHROUGH = "File Walkthrough"
|
||||||
|
|
||||||
|
|
||||||
def get_setting(key: str) -> Any:
|
def get_setting(key: str) -> Any:
|
||||||
|
|
@ -147,6 +148,7 @@ def convert_to_markdown_v2(output_data: dict,
|
||||||
"Insights from user's answers": "📝",
|
"Insights from user's answers": "📝",
|
||||||
"Code feedback": "🤖",
|
"Code feedback": "🤖",
|
||||||
"Estimated effort to review [1-5]": "⏱️",
|
"Estimated effort to review [1-5]": "⏱️",
|
||||||
|
"Contribution time cost estimate": "⏳",
|
||||||
"Ticket compliance check": "🎫",
|
"Ticket compliance check": "🎫",
|
||||||
}
|
}
|
||||||
markdown_text = ""
|
markdown_text = ""
|
||||||
|
|
@ -206,6 +208,14 @@ def convert_to_markdown_v2(output_data: dict,
|
||||||
markdown_text += f"### {emoji} PR contains tests\n\n"
|
markdown_text += f"### {emoji} PR contains tests\n\n"
|
||||||
elif 'ticket compliance check' in key_nice.lower():
|
elif 'ticket compliance check' in key_nice.lower():
|
||||||
markdown_text = ticket_markdown_logic(emoji, markdown_text, value, gfm_supported)
|
markdown_text = ticket_markdown_logic(emoji, markdown_text, value, gfm_supported)
|
||||||
|
elif 'contribution time cost estimate' in key_nice.lower():
|
||||||
|
if gfm_supported:
|
||||||
|
markdown_text += f"<tr><td>{emoji} <strong>Contribution time estimate</strong> (best, average, worst case): "
|
||||||
|
markdown_text += f"{value['best_case'].replace('m', ' minutes')} | {value['average_case'].replace('m', ' minutes')} | {value['worst_case'].replace('m', ' minutes')}"
|
||||||
|
markdown_text += f"</td></tr>\n"
|
||||||
|
else:
|
||||||
|
markdown_text += f"### {emoji} Contribution time estimate (best, average, worst case): "
|
||||||
|
markdown_text += f"{value['best_case'].replace('m', ' minutes')} | {value['average_case'].replace('m', ' minutes')} | {value['worst_case'].replace('m', ' minutes')}\n\n"
|
||||||
elif 'security concerns' in key_nice.lower():
|
elif 'security concerns' in key_nice.lower():
|
||||||
if gfm_supported:
|
if gfm_supported:
|
||||||
markdown_text += f"<tr><td>"
|
markdown_text += f"<tr><td>"
|
||||||
|
|
@ -738,7 +748,7 @@ def _fix_key_value(key: str, value: str):
|
||||||
|
|
||||||
def load_yaml(response_text: str, keys_fix_yaml: List[str] = [], first_key="", last_key="") -> dict:
|
def load_yaml(response_text: str, keys_fix_yaml: List[str] = [], first_key="", last_key="") -> dict:
|
||||||
response_text_original = copy.deepcopy(response_text)
|
response_text_original = copy.deepcopy(response_text)
|
||||||
response_text = response_text.strip('\n').removeprefix('```yaml').rstrip().removesuffix('```')
|
response_text = response_text.strip('\n').removeprefix('yaml').removeprefix('```yaml').rstrip().removesuffix('```')
|
||||||
try:
|
try:
|
||||||
data = yaml.safe_load(response_text)
|
data = yaml.safe_load(response_text)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
|
|
@ -762,7 +772,8 @@ def try_fix_yaml(response_text: str,
|
||||||
response_text_original="") -> dict:
|
response_text_original="") -> dict:
|
||||||
response_text_lines = response_text.split('\n')
|
response_text_lines = response_text.split('\n')
|
||||||
|
|
||||||
keys_yaml = ['relevant line:', 'suggestion content:', 'relevant file:', 'existing code:', 'improved code:', 'label:']
|
keys_yaml = ['relevant line:', 'suggestion content:', 'relevant file:', 'existing code:',
|
||||||
|
'improved code:', 'label:', 'why:', 'suggestion_summary:']
|
||||||
keys_yaml = keys_yaml + keys_fix_yaml
|
keys_yaml = keys_yaml + keys_fix_yaml
|
||||||
|
|
||||||
# first fallback - try to convert 'relevant line: ...' to relevant line: |-\n ...'
|
# first fallback - try to convert 'relevant line: ...' to relevant line: |-\n ...'
|
||||||
|
|
@ -837,12 +848,13 @@ def try_fix_yaml(response_text: str,
|
||||||
if index_end == -1:
|
if index_end == -1:
|
||||||
index_end = len(response_text)
|
index_end = len(response_text)
|
||||||
response_text_copy = response_text[index_start:index_end].strip().strip('```yaml').strip('`').strip()
|
response_text_copy = response_text[index_start:index_end].strip().strip('```yaml').strip('`').strip()
|
||||||
try:
|
if response_text_copy:
|
||||||
data = yaml.safe_load(response_text_copy)
|
try:
|
||||||
get_logger().info(f"Successfully parsed AI prediction after extracting yaml snippet")
|
data = yaml.safe_load(response_text_copy)
|
||||||
return data
|
get_logger().info(f"Successfully parsed AI prediction after extracting yaml snippet")
|
||||||
except:
|
return data
|
||||||
pass
|
except:
|
||||||
|
pass
|
||||||
|
|
||||||
# fifth fallback - try to remove leading '+' (sometimes added by AI for 'existing code' and 'improved code')
|
# fifth fallback - try to remove leading '+' (sometimes added by AI for 'existing code' and 'improved code')
|
||||||
response_text_lines_copy = response_text_lines.copy()
|
response_text_lines_copy = response_text_lines.copy()
|
||||||
|
|
@ -871,14 +883,18 @@ def try_fix_yaml(response_text: str,
|
||||||
response_text_copy = copy.deepcopy(response_text)
|
response_text_copy = copy.deepcopy(response_text)
|
||||||
response_text_copy_lines = response_text_copy.split('\n')
|
response_text_copy_lines = response_text_copy.split('\n')
|
||||||
start_line = -1
|
start_line = -1
|
||||||
|
improve_sections = ['existing_code:', 'improved_code:', 'response:', 'why:']
|
||||||
|
describe_sections = ['description:', 'title:', 'changes_diagram:', 'pr_files:', 'pr_ticket:']
|
||||||
for i, line in enumerate(response_text_copy_lines):
|
for i, line in enumerate(response_text_copy_lines):
|
||||||
if 'existing_code:' in line or 'improved_code:' in line:
|
line_stripped = line.rstrip()
|
||||||
|
if any(key in line_stripped for key in (improve_sections+describe_sections)):
|
||||||
start_line = i
|
start_line = i
|
||||||
elif line.endswith(': |') or line.endswith(': |-') or line.endswith(': |2') or line.endswith(':'):
|
elif line_stripped.endswith(': |') or line_stripped.endswith(': |-') or line_stripped.endswith(': |2') or any(line_stripped.endswith(key) for key in keys_yaml):
|
||||||
start_line = -1
|
start_line = -1
|
||||||
elif start_line != -1:
|
elif start_line != -1:
|
||||||
response_text_copy_lines[i] = ' ' + line
|
response_text_copy_lines[i] = ' ' + line
|
||||||
response_text_copy = '\n'.join(response_text_copy_lines)
|
response_text_copy = '\n'.join(response_text_copy_lines)
|
||||||
|
response_text_copy = response_text_copy.replace(' |\n', ' |2\n')
|
||||||
try:
|
try:
|
||||||
data = yaml.safe_load(response_text_copy)
|
data = yaml.safe_load(response_text_copy)
|
||||||
get_logger().info(f"Successfully parsed AI prediction after adding indent for sections of code blocks")
|
get_logger().info(f"Successfully parsed AI prediction after adding indent for sections of code blocks")
|
||||||
|
|
@ -886,6 +902,27 @@ def try_fix_yaml(response_text: str,
|
||||||
except:
|
except:
|
||||||
pass
|
pass
|
||||||
|
|
||||||
|
# eighth fallback - try to remove pipe chars at the root-level dicts
|
||||||
|
response_text_copy = copy.deepcopy(response_text)
|
||||||
|
response_text_copy = response_text_copy.lstrip('|\n')
|
||||||
|
try:
|
||||||
|
data = yaml.safe_load(response_text_copy)
|
||||||
|
get_logger().info(f"Successfully parsed AI prediction after removing pipe chars")
|
||||||
|
return data
|
||||||
|
except:
|
||||||
|
pass
|
||||||
|
|
||||||
|
# ninth fallback - try to decode the response text with different encodings. GPT-5 can return text that is not utf-8 encoded.
|
||||||
|
encodings_to_try = ['latin-1', 'utf-16']
|
||||||
|
for encoding in encodings_to_try:
|
||||||
|
try:
|
||||||
|
data = yaml.safe_load(response_text.encode(encoding).decode("utf-8"))
|
||||||
|
if data:
|
||||||
|
get_logger().info(f"Successfully parsed AI prediction after decoding with {encoding} encoding")
|
||||||
|
return data
|
||||||
|
except:
|
||||||
|
pass
|
||||||
|
|
||||||
# # sixth fallback - try to remove last lines
|
# # sixth fallback - try to remove last lines
|
||||||
# for i in range(1, len(response_text_lines)):
|
# for i in range(1, len(response_text_lines)):
|
||||||
# response_text_lines_tmp = '\n'.join(response_text_lines[:-i])
|
# response_text_lines_tmp = '\n'.join(response_text_lines[:-i])
|
||||||
|
|
@ -1284,14 +1321,35 @@ def process_description(description_full: str) -> Tuple[str, List]:
|
||||||
if not description_full:
|
if not description_full:
|
||||||
return "", []
|
return "", []
|
||||||
|
|
||||||
description_split = description_full.split(PRDescriptionHeader.CHANGES_WALKTHROUGH.value)
|
# description_split = description_full.split(PRDescriptionHeader.FILE_WALKTHROUGH.value)
|
||||||
base_description_str = description_split[0]
|
if PRDescriptionHeader.FILE_WALKTHROUGH.value in description_full:
|
||||||
changes_walkthrough_str = ""
|
try:
|
||||||
files = []
|
# FILE_WALKTHROUGH are presented in a collapsible section in the description
|
||||||
if len(description_split) > 1:
|
regex_pattern = r'<details.*?>\s*<summary>\s*<h3>\s*' + re.escape(PRDescriptionHeader.FILE_WALKTHROUGH.value) + r'\s*</h3>\s*</summary>'
|
||||||
changes_walkthrough_str = description_split[1]
|
description_split = re.split(regex_pattern, description_full, maxsplit=1, flags=re.DOTALL)
|
||||||
|
|
||||||
|
# If the regex pattern is not found, fallback to the previous method
|
||||||
|
if len(description_split) == 1:
|
||||||
|
get_logger().debug("Could not find regex pattern for file walkthrough, falling back to simple split")
|
||||||
|
description_split = description_full.split(PRDescriptionHeader.FILE_WALKTHROUGH.value, 1)
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().warning(f"Failed to split description using regex, falling back to simple split: {e}")
|
||||||
|
description_split = description_full.split(PRDescriptionHeader.FILE_WALKTHROUGH.value, 1)
|
||||||
|
|
||||||
|
if len(description_split) < 2:
|
||||||
|
get_logger().error("Failed to split description into base and changes walkthrough", artifact={'description': description_full})
|
||||||
|
return description_full.strip(), []
|
||||||
|
|
||||||
|
base_description_str = description_split[0].strip()
|
||||||
|
changes_walkthrough_str = ""
|
||||||
|
files = []
|
||||||
|
if len(description_split) > 1:
|
||||||
|
changes_walkthrough_str = description_split[1]
|
||||||
|
else:
|
||||||
|
get_logger().debug("No changes walkthrough found")
|
||||||
else:
|
else:
|
||||||
get_logger().debug("No changes walkthrough found")
|
base_description_str = description_full.strip()
|
||||||
|
return base_description_str, []
|
||||||
|
|
||||||
try:
|
try:
|
||||||
if changes_walkthrough_str:
|
if changes_walkthrough_str:
|
||||||
|
|
@ -1314,18 +1372,20 @@ def process_description(description_full: str) -> Tuple[str, List]:
|
||||||
try:
|
try:
|
||||||
if isinstance(file_data, tuple):
|
if isinstance(file_data, tuple):
|
||||||
file_data = file_data[0]
|
file_data = file_data[0]
|
||||||
pattern = r'<details>\s*<summary><strong>(.*?)</strong>\s*<dd><code>(.*?)</code>.*?</summary>\s*<hr>\s*(.*?)\s*<li>(.*?)</details>'
|
pattern = r'<details>\s*<summary><strong>(.*?)</strong>\s*<dd><code>(.*?)</code>.*?</summary>\s*<hr>\s*(.*?)\s*(?:<li>|•)(.*?)</details>'
|
||||||
res = re.search(pattern, file_data, re.DOTALL)
|
res = re.search(pattern, file_data, re.DOTALL)
|
||||||
if not res or res.lastindex != 4:
|
if not res or res.lastindex != 4:
|
||||||
pattern_back = r'<details>\s*<summary><strong>(.*?)</strong><dd><code>(.*?)</code>.*?</summary>\s*<hr>\s*(.*?)\n\n\s*(.*?)</details>'
|
pattern_back = r'<details>\s*<summary><strong>(.*?)</strong><dd><code>(.*?)</code>.*?</summary>\s*<hr>\s*(.*?)\n\n\s*(.*?)</details>'
|
||||||
res = re.search(pattern_back, file_data, re.DOTALL)
|
res = re.search(pattern_back, file_data, re.DOTALL)
|
||||||
if not res or res.lastindex != 4:
|
if not res or res.lastindex != 4:
|
||||||
pattern_back = r'<details>\s*<summary><strong>(.*?)</strong>\s*<dd><code>(.*?)</code>.*?</summary>\s*<hr>\s*(.*?)\s*-\s*(.*?)\s*</details>' # looking for hyphen ('- ')
|
pattern_back = r'<details>\s*<summary><strong>(.*?)</strong>\s*<dd><code>(.*?)</code>.*?</summary>\s*<hr>\s*(.*?)\s*-\s*(.*?)\s*</details>' # looking for hypen ('- ')
|
||||||
res = re.search(pattern_back, file_data, re.DOTALL)
|
res = re.search(pattern_back, file_data, re.DOTALL)
|
||||||
if res and res.lastindex == 4:
|
if res and res.lastindex == 4:
|
||||||
short_filename = res.group(1).strip()
|
short_filename = res.group(1).strip()
|
||||||
short_summary = res.group(2).strip()
|
short_summary = res.group(2).strip()
|
||||||
long_filename = res.group(3).strip()
|
long_filename = res.group(3).strip()
|
||||||
|
if long_filename.endswith('<ul>'):
|
||||||
|
long_filename = long_filename[:-4].strip()
|
||||||
long_summary = res.group(4).strip()
|
long_summary = res.group(4).strip()
|
||||||
long_summary = long_summary.replace('<br> *', '\n*').replace('<br>','').replace('\n','<br>')
|
long_summary = long_summary.replace('<br> *', '\n*').replace('<br>','').replace('\n','<br>')
|
||||||
long_summary = h.handle(long_summary).strip()
|
long_summary = h.handle(long_summary).strip()
|
||||||
|
|
@ -1344,7 +1404,7 @@ def process_description(description_full: str) -> Tuple[str, List]:
|
||||||
if '<code>...</code>' in file_data:
|
if '<code>...</code>' in file_data:
|
||||||
pass # PR with many files. some did not get analyzed
|
pass # PR with many files. some did not get analyzed
|
||||||
else:
|
else:
|
||||||
get_logger().error(f"Failed to parse description", artifact={'description': file_data})
|
get_logger().warning(f"Failed to parse description", artifact={'description': file_data})
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
get_logger().exception(f"Failed to process description: {e}", artifact={'description': file_data})
|
get_logger().exception(f"Failed to process description: {e}", artifact={'description': file_data})
|
||||||
|
|
||||||
|
|
@ -1441,4 +1501,4 @@ def format_todo_items(value: list[TodoItem] | TodoItem, git_provider, gfm_suppor
|
||||||
markdown_text += f"- {format_todo_item(todo_item, git_provider, gfm_supported)}\n"
|
markdown_text += f"- {format_todo_item(todo_item, git_provider, gfm_supported)}\n"
|
||||||
else:
|
else:
|
||||||
markdown_text += f"- {format_todo_item(value, git_provider, gfm_supported)}\n"
|
markdown_text += f"- {format_todo_item(value, git_provider, gfm_supported)}\n"
|
||||||
return markdown_text
|
return markdown_text
|
||||||
|
|
|
||||||
|
|
@ -8,12 +8,19 @@ from starlette_context import context
|
||||||
PR_AGENT_TOML_KEY = 'pr-agent'
|
PR_AGENT_TOML_KEY = 'pr-agent'
|
||||||
|
|
||||||
current_dir = dirname(abspath(__file__))
|
current_dir = dirname(abspath(__file__))
|
||||||
|
|
||||||
|
dynconf_kwargs = {'core_loaders': [], # DISABLE default loaders, otherwise will load toml files more than once.
|
||||||
|
'loaders': ['pr_agent.custom_merge_loader', 'dynaconf.loaders.env_loader'], # Use a custom loader to merge sections, but overwrite their overlapping values. Also support ENV variables to take precedence.
|
||||||
|
'root_path': join(current_dir, "settings"), #Used for Dynaconf.find_file() - So that root path points to settings folder, since we disabled all core loaders.
|
||||||
|
'merge_enabled': True # In case more than one file is sent, merge them. Must be set to True, otherwise, a .toml file with section [XYZ] overwrites the entire section of a previous .toml file's [XYZ] and we want it to only overwrite the overlapping fields under such section
|
||||||
|
}
|
||||||
global_settings = Dynaconf(
|
global_settings = Dynaconf(
|
||||||
envvar_prefix=False,
|
envvar_prefix=False,
|
||||||
merge_enabled=True,
|
load_dotenv=False, # Security: Don't load .env files
|
||||||
settings_files=[join(current_dir, f) for f in [
|
settings_files=[join(current_dir, f) for f in [
|
||||||
"settings/configuration.toml",
|
"settings/configuration.toml",
|
||||||
"settings/ignore.toml",
|
"settings/ignore.toml",
|
||||||
|
"settings/generated_code_ignore.toml",
|
||||||
"settings/language_extensions.toml",
|
"settings/language_extensions.toml",
|
||||||
"settings/pr_reviewer_prompts.toml",
|
"settings/pr_reviewer_prompts.toml",
|
||||||
"settings/pr_questions_prompts.toml",
|
"settings/pr_questions_prompts.toml",
|
||||||
|
|
@ -32,7 +39,8 @@ global_settings = Dynaconf(
|
||||||
"settings/pr_help_docs_headings_prompts.toml",
|
"settings/pr_help_docs_headings_prompts.toml",
|
||||||
"settings/.secrets.toml",
|
"settings/.secrets.toml",
|
||||||
"settings_prod/.secrets.toml",
|
"settings_prod/.secrets.toml",
|
||||||
]]
|
]],
|
||||||
|
**dynconf_kwargs
|
||||||
)
|
)
|
||||||
|
|
||||||
|
|
||||||
|
|
|
||||||
167
pr_agent/custom_merge_loader.py
Normal file
167
pr_agent/custom_merge_loader.py
Normal file
|
|
@ -0,0 +1,167 @@
|
||||||
|
from pathlib import Path
|
||||||
|
import tomllib #tomllib should be used instead of Py toml for Python 3.11+
|
||||||
|
|
||||||
|
from jinja2.exceptions import SecurityError
|
||||||
|
|
||||||
|
from pr_agent.log import get_logger
|
||||||
|
|
||||||
|
def load(obj, env=None, silent=True, key=None, filename=None):
|
||||||
|
"""
|
||||||
|
Load and merge TOML configuration files into a Dynaconf settings object using a secure, in-house loader.
|
||||||
|
This loader:
|
||||||
|
- Replaces list and dict fields instead of appending/updating (non-default Dynaconf behavior).
|
||||||
|
- Enforces several security checks (e.g., disallows includes/preloads and enforces .toml files).
|
||||||
|
- Supports optional single-key loading.
|
||||||
|
Args:
|
||||||
|
obj: The Dynaconf settings instance to update.
|
||||||
|
env: The current environment name (upper case). Defaults to 'DEVELOPMENT'. Note: currently unused.
|
||||||
|
silent (bool): If True, suppress exceptions and log warnings/errors instead.
|
||||||
|
key (str | None): Load only this top-level key (section) if provided; otherwise, load all keys from the files.
|
||||||
|
filename (str | None): Custom filename for tests (not used when settings_files are provided).
|
||||||
|
Returns:
|
||||||
|
None
|
||||||
|
"""
|
||||||
|
|
||||||
|
MAX_TOML_SIZE_IN_BYTES = 100 * 1024 * 1024 # Prevent out of mem. exceptions by limiting to 100 MBs which is sufficient for upto 1M lines
|
||||||
|
|
||||||
|
# Get the list of files to load
|
||||||
|
# TODO: hasattr(obj, 'settings_files') for some reason returns False. Need to use 'settings_file'
|
||||||
|
settings_files = obj.settings_files if hasattr(obj, 'settings_files') else (
|
||||||
|
obj.settings_file) if hasattr(obj, 'settings_file') else []
|
||||||
|
if not settings_files or not isinstance(settings_files, list):
|
||||||
|
get_logger().warning("No settings files specified, or missing keys "
|
||||||
|
"(tried looking for 'settings_files' or 'settings_file'), or not a list. Skipping loading.",
|
||||||
|
artifact={'toml_obj_attributes_names': dir(obj)})
|
||||||
|
return
|
||||||
|
|
||||||
|
# Storage for all loaded data
|
||||||
|
accumulated_data = {}
|
||||||
|
|
||||||
|
# Security: Check for forbidden configuration options
|
||||||
|
if hasattr(obj, 'includes') and obj.includes:
|
||||||
|
if not silent:
|
||||||
|
raise SecurityError("Configuration includes forbidden option: 'includes'. Skipping loading.")
|
||||||
|
get_logger().error("Configuration includes forbidden option: 'includes'. Skipping loading.")
|
||||||
|
return
|
||||||
|
if hasattr(obj, 'preload') and obj.preload:
|
||||||
|
if not silent:
|
||||||
|
raise SecurityError("Configuration includes forbidden option: 'preload'. Skipping loading.")
|
||||||
|
get_logger().error("Configuration includes forbidden option: 'preload'. Skipping loading.")
|
||||||
|
return
|
||||||
|
|
||||||
|
for settings_file in settings_files:
|
||||||
|
try:
|
||||||
|
# Load the TOML file
|
||||||
|
file_path = Path(settings_file)
|
||||||
|
# Security: Only allow .toml files
|
||||||
|
if file_path.suffix.lower() != '.toml':
|
||||||
|
get_logger().warning(f"Only .toml files are allowed. Skipping: {settings_file}")
|
||||||
|
continue
|
||||||
|
|
||||||
|
if not file_path.exists():
|
||||||
|
get_logger().warning(f"Settings file not found: {settings_file}. Skipping it.")
|
||||||
|
continue
|
||||||
|
|
||||||
|
if file_path.stat().st_size > MAX_TOML_SIZE_IN_BYTES:
|
||||||
|
get_logger().warning(f"Settings file too large (> {MAX_TOML_SIZE_IN_BYTES} bytes): {settings_file}. Skipping it.")
|
||||||
|
continue
|
||||||
|
|
||||||
|
with open(file_path, 'rb') as f:
|
||||||
|
file_data = tomllib.load(f)
|
||||||
|
|
||||||
|
# Handle sections (like [config], [default], etc.)
|
||||||
|
if not isinstance(file_data, dict):
|
||||||
|
get_logger().warning(f"TOML root is not a table in '{settings_file}'. Skipping.")
|
||||||
|
continue
|
||||||
|
|
||||||
|
# Security: Check file contents for forbidden directives
|
||||||
|
validate_file_security(file_data, settings_file)
|
||||||
|
|
||||||
|
for section_name, section_data in file_data.items():
|
||||||
|
if not isinstance(section_data, dict):
|
||||||
|
get_logger().warning(f"Section '{section_name}' in '{settings_file}' is not a table. Skipping.")
|
||||||
|
continue
|
||||||
|
for field, field_value in section_data.items():
|
||||||
|
if section_name not in accumulated_data:
|
||||||
|
accumulated_data[section_name] = {}
|
||||||
|
accumulated_data[section_name][field] = field_value
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
if not silent:
|
||||||
|
raise e
|
||||||
|
get_logger().exception(f"Exception loading settings file: {settings_file}. Skipping.")
|
||||||
|
|
||||||
|
# Update the settings object
|
||||||
|
for k, v in accumulated_data.items():
|
||||||
|
if key is None or key == k:
|
||||||
|
obj.set(k, v)
|
||||||
|
|
||||||
|
def validate_file_security(file_data, filename):
|
||||||
|
"""
|
||||||
|
Validate that the config file does not contain security-sensitive directives.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
file_data: Parsed TOML data representing the configuration contents.
|
||||||
|
filename: The name or path of the file being validated (used for error messages).
|
||||||
|
|
||||||
|
Raises:
|
||||||
|
SecurityError: If forbidden directives are found within the configuration, or if data too nested.
|
||||||
|
"""
|
||||||
|
MAX_DEPTH = 50
|
||||||
|
|
||||||
|
# Check for forbidden keys
|
||||||
|
# Comprehensive list of forbidden keys with explanations
|
||||||
|
forbidden_keys_to_reasons = {
|
||||||
|
# Include mechanisms - allow loading arbitrary files
|
||||||
|
'dynaconf_include': 'allows including other config files dynamically',
|
||||||
|
'dynaconf_includes': 'allows including other config files dynamically',
|
||||||
|
'includes': 'allows including other config files dynamically',
|
||||||
|
|
||||||
|
# Preload mechanisms - allow loading files before main config
|
||||||
|
'preload': 'allows preloading files with potential code execution',
|
||||||
|
'preload_for_dynaconf': 'allows preloading files with potential code execution',
|
||||||
|
'preloads': 'allows preloading files with potential code execution',
|
||||||
|
|
||||||
|
# Merge controls - could be used to manipulate config behavior
|
||||||
|
'dynaconf_merge': 'allows manipulating merge behavior',
|
||||||
|
'dynaconf_merge_enabled': 'allows manipulating merge behavior',
|
||||||
|
'merge_enabled': 'allows manipulating merge behavior',
|
||||||
|
|
||||||
|
# Loader controls - allow changing how configs are loaded
|
||||||
|
'loaders_for_dynaconf': 'allows overriding loaders to execute arbitrary code',
|
||||||
|
'loaders': 'allows overriding loaders to execute arbitrary code',
|
||||||
|
'core_loaders': 'allows overriding core loaders',
|
||||||
|
'core_loaders_for_dynaconf': 'allows overriding core loaders',
|
||||||
|
|
||||||
|
# Settings module - allows loading Python modules
|
||||||
|
'settings_module': 'allows loading Python modules with code execution',
|
||||||
|
'settings_file_for_dynaconf': 'could override settings file location',
|
||||||
|
'settings_files_for_dynaconf': 'could override settings file location',
|
||||||
|
|
||||||
|
# Environment variable prefix manipulation
|
||||||
|
'envvar_prefix': 'allows changing environment variable prefix',
|
||||||
|
'envvar_prefix_for_dynaconf': 'allows changing environment variable prefix',
|
||||||
|
}
|
||||||
|
|
||||||
|
# Check at the top level and in all sections
|
||||||
|
def check_dict(data, path="", max_depth=MAX_DEPTH):
|
||||||
|
if max_depth <= 0:
|
||||||
|
raise SecurityError(
|
||||||
|
f"Maximum nesting depth exceeded at {path}. "
|
||||||
|
f"Possible attempt to cause stack overflow."
|
||||||
|
)
|
||||||
|
|
||||||
|
for key, value in data.items():
|
||||||
|
full_path = f"{path}.{key}" if path else key
|
||||||
|
|
||||||
|
if key.lower() in forbidden_keys_to_reasons:
|
||||||
|
raise SecurityError(
|
||||||
|
f"Security error in {filename}: "
|
||||||
|
f"Forbidden directive '{key}' found at {full_path}. Reason: {forbidden_keys_to_reasons[key.lower()]}"
|
||||||
|
)
|
||||||
|
|
||||||
|
# Recursively check nested dicts
|
||||||
|
if isinstance(value, dict):
|
||||||
|
check_dict(value, path=full_path, max_depth=(max_depth - 1))
|
||||||
|
|
||||||
|
check_dict(file_data, max_depth=MAX_DEPTH)
|
||||||
|
|
@ -22,6 +22,7 @@ try:
|
||||||
from azure.devops.connection import Connection
|
from azure.devops.connection import Connection
|
||||||
# noinspection PyUnresolvedReferences
|
# noinspection PyUnresolvedReferences
|
||||||
from azure.devops.released.git import (Comment, CommentThread, GitPullRequest, GitVersionDescriptor, GitClient, CommentThreadContext, CommentPosition)
|
from azure.devops.released.git import (Comment, CommentThread, GitPullRequest, GitVersionDescriptor, GitClient, CommentThreadContext, CommentPosition)
|
||||||
|
from azure.devops.released.work_item_tracking import WorkItemTrackingClient
|
||||||
# noinspection PyUnresolvedReferences
|
# noinspection PyUnresolvedReferences
|
||||||
from azure.identity import DefaultAzureCredential
|
from azure.identity import DefaultAzureCredential
|
||||||
from msrest.authentication import BasicAuthentication
|
from msrest.authentication import BasicAuthentication
|
||||||
|
|
@ -39,7 +40,7 @@ class AzureDevopsProvider(GitProvider):
|
||||||
"Azure DevOps provider is not available. Please install the required dependencies."
|
"Azure DevOps provider is not available. Please install the required dependencies."
|
||||||
)
|
)
|
||||||
|
|
||||||
self.azure_devops_client = self._get_azure_devops_client()
|
self.azure_devops_client, self.azure_devops_board_client = self._get_azure_devops_client()
|
||||||
self.diff_files = None
|
self.diff_files = None
|
||||||
self.workspace_slug = None
|
self.workspace_slug = None
|
||||||
self.repo_slug = None
|
self.repo_slug = None
|
||||||
|
|
@ -56,6 +57,7 @@ class AzureDevopsProvider(GitProvider):
|
||||||
Publishes code suggestions as comments on the PR.
|
Publishes code suggestions as comments on the PR.
|
||||||
"""
|
"""
|
||||||
post_parameters_list = []
|
post_parameters_list = []
|
||||||
|
status = get_settings().azure_devops.get("default_comment_status", "closed")
|
||||||
for suggestion in code_suggestions:
|
for suggestion in code_suggestions:
|
||||||
body = suggestion['body']
|
body = suggestion['body']
|
||||||
relevant_file = suggestion['relevant_file']
|
relevant_file = suggestion['relevant_file']
|
||||||
|
|
@ -78,7 +80,7 @@ class AzureDevopsProvider(GitProvider):
|
||||||
right_file_start=CommentPosition(offset=1, line=relevant_lines_start),
|
right_file_start=CommentPosition(offset=1, line=relevant_lines_start),
|
||||||
right_file_end=CommentPosition(offset=1, line=relevant_lines_end))
|
right_file_end=CommentPosition(offset=1, line=relevant_lines_end))
|
||||||
comment = Comment(content=body, comment_type=1)
|
comment = Comment(content=body, comment_type=1)
|
||||||
thread = CommentThread(comments=[comment], thread_context=thread_context)
|
thread = CommentThread(comments=[comment], thread_context=thread_context, status=status)
|
||||||
try:
|
try:
|
||||||
self.azure_devops_client.create_thread(
|
self.azure_devops_client.create_thread(
|
||||||
comment_thread=thread,
|
comment_thread=thread,
|
||||||
|
|
@ -194,7 +196,7 @@ class AzureDevopsProvider(GitProvider):
|
||||||
return self.diff_files
|
return self.diff_files
|
||||||
|
|
||||||
base_sha = self.pr.last_merge_target_commit
|
base_sha = self.pr.last_merge_target_commit
|
||||||
head_sha = self.pr.last_merge_source_commit
|
head_sha = self.pr.last_merge_commit
|
||||||
|
|
||||||
# Get PR iterations
|
# Get PR iterations
|
||||||
iterations = self.azure_devops_client.get_pull_request_iterations(
|
iterations = self.azure_devops_client.get_pull_request_iterations(
|
||||||
|
|
@ -350,7 +352,9 @@ class AzureDevopsProvider(GitProvider):
|
||||||
get_logger().debug(f"Skipping publish_comment for temporary comment: {pr_comment}")
|
get_logger().debug(f"Skipping publish_comment for temporary comment: {pr_comment}")
|
||||||
return None
|
return None
|
||||||
comment = Comment(content=pr_comment)
|
comment = Comment(content=pr_comment)
|
||||||
thread = CommentThread(comments=[comment], thread_context=thread_context, status="closed")
|
|
||||||
|
status = get_settings().azure_devops.get("default_comment_status", "closed")
|
||||||
|
thread = CommentThread(comments=[comment], thread_context=thread_context, status=status)
|
||||||
thread_response = self.azure_devops_client.create_thread(
|
thread_response = self.azure_devops_client.create_thread(
|
||||||
comment_thread=thread,
|
comment_thread=thread,
|
||||||
project=self.workspace_slug,
|
project=self.workspace_slug,
|
||||||
|
|
@ -379,7 +383,7 @@ class AzureDevopsProvider(GitProvider):
|
||||||
pr_body = pr_body[:ind]
|
pr_body = pr_body[:ind]
|
||||||
|
|
||||||
if len(pr_body) > MAX_PR_DESCRIPTION_AZURE_LENGTH:
|
if len(pr_body) > MAX_PR_DESCRIPTION_AZURE_LENGTH:
|
||||||
changes_walkthrough_text = PRDescriptionHeader.CHANGES_WALKTHROUGH.value
|
changes_walkthrough_text = PRDescriptionHeader.FILE_WALKTHROUGH.value
|
||||||
ind = pr_body.find(changes_walkthrough_text)
|
ind = pr_body.find(changes_walkthrough_text)
|
||||||
if ind != -1:
|
if ind != -1:
|
||||||
pr_body = pr_body[:ind]
|
pr_body = pr_body[:ind]
|
||||||
|
|
@ -566,7 +570,7 @@ class AzureDevopsProvider(GitProvider):
|
||||||
return workspace_slug, repo_slug, pr_number
|
return workspace_slug, repo_slug, pr_number
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def _get_azure_devops_client() -> GitClient:
|
def _get_azure_devops_client() -> Tuple[GitClient, WorkItemTrackingClient]:
|
||||||
org = get_settings().azure_devops.get("org", None)
|
org = get_settings().azure_devops.get("org", None)
|
||||||
pat = get_settings().azure_devops.get("pat", None)
|
pat = get_settings().azure_devops.get("pat", None)
|
||||||
|
|
||||||
|
|
@ -588,13 +592,12 @@ class AzureDevopsProvider(GitProvider):
|
||||||
get_logger().error(f"No PAT found in settings, and Azure Default Authentication failed, error: {e}")
|
get_logger().error(f"No PAT found in settings, and Azure Default Authentication failed, error: {e}")
|
||||||
raise
|
raise
|
||||||
|
|
||||||
credentials = BasicAuthentication("", auth_token)
|
|
||||||
|
|
||||||
credentials = BasicAuthentication("", auth_token)
|
credentials = BasicAuthentication("", auth_token)
|
||||||
azure_devops_connection = Connection(base_url=org, creds=credentials)
|
azure_devops_connection = Connection(base_url=org, creds=credentials)
|
||||||
azure_devops_client = azure_devops_connection.clients.get_git_client()
|
azure_devops_client = azure_devops_connection.clients.get_git_client()
|
||||||
|
azure_devops_board_client = azure_devops_connection.clients.get_work_item_tracking_client()
|
||||||
|
|
||||||
return azure_devops_client
|
return azure_devops_client, azure_devops_board_client
|
||||||
|
|
||||||
def _get_repo(self):
|
def _get_repo(self):
|
||||||
if self.repo is None:
|
if self.repo is None:
|
||||||
|
|
@ -635,4 +638,50 @@ class AzureDevopsProvider(GitProvider):
|
||||||
last = commits[0]
|
last = commits[0]
|
||||||
url = self.azure_devops_client.normalized_url + "/" + self.workspace_slug + "/_git/" + self.repo_slug + "/commit/" + last.commit_id
|
url = self.azure_devops_client.normalized_url + "/" + self.workspace_slug + "/_git/" + self.repo_slug + "/commit/" + last.commit_id
|
||||||
return url
|
return url
|
||||||
|
|
||||||
|
def get_linked_work_items(self) -> list:
|
||||||
|
"""
|
||||||
|
Get linked work items from the PR.
|
||||||
|
"""
|
||||||
|
try:
|
||||||
|
work_items = self.azure_devops_client.get_pull_request_work_item_refs(
|
||||||
|
project=self.workspace_slug,
|
||||||
|
repository_id=self.repo_slug,
|
||||||
|
pull_request_id=self.pr_num,
|
||||||
|
)
|
||||||
|
ids = [work_item.id for work_item in work_items]
|
||||||
|
if not work_items:
|
||||||
|
return []
|
||||||
|
items = self.get_work_items(ids)
|
||||||
|
return items
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().exception(f"Failed to get linked work items, error: {e}")
|
||||||
|
return []
|
||||||
|
|
||||||
|
def get_work_items(self, work_item_ids: list) -> list:
|
||||||
|
"""
|
||||||
|
Get work items by their IDs.
|
||||||
|
"""
|
||||||
|
try:
|
||||||
|
raw_work_items = self.azure_devops_board_client.get_work_items(
|
||||||
|
project=self.workspace_slug,
|
||||||
|
ids=work_item_ids,
|
||||||
|
)
|
||||||
|
work_items = []
|
||||||
|
for item in raw_work_items:
|
||||||
|
work_items.append(
|
||||||
|
{
|
||||||
|
"id": item.id,
|
||||||
|
"title": item.fields.get("System.Title", ""),
|
||||||
|
"url": item.url,
|
||||||
|
"body": item.fields.get("System.Description", ""),
|
||||||
|
"acceptance_criteria": item.fields.get(
|
||||||
|
"Microsoft.VSTS.Common.AcceptanceCriteria", ""
|
||||||
|
),
|
||||||
|
"tags": item.fields.get("System.Tags", "").split("; ") if item.fields.get("System.Tags") else [],
|
||||||
|
}
|
||||||
|
)
|
||||||
|
return work_items
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().exception(f"Failed to get work items, error: {e}")
|
||||||
|
return []
|
||||||
|
|
|
||||||
|
|
@ -10,6 +10,7 @@ from requests.exceptions import HTTPError
|
||||||
import shlex
|
import shlex
|
||||||
import subprocess
|
import subprocess
|
||||||
|
|
||||||
|
from ..algo.file_filter import filter_ignored
|
||||||
from ..algo.git_patch_processing import decode_if_bytes
|
from ..algo.git_patch_processing import decode_if_bytes
|
||||||
from ..algo.language_handler import is_valid_file
|
from ..algo.language_handler import is_valid_file
|
||||||
from ..algo.types import EDIT_TYPE, FilePatchInfo
|
from ..algo.types import EDIT_TYPE, FilePatchInfo
|
||||||
|
|
@ -17,7 +18,7 @@ from ..algo.utils import (find_line_number_of_relevant_line_in_file,
|
||||||
load_large_diff)
|
load_large_diff)
|
||||||
from ..config_loader import get_settings
|
from ..config_loader import get_settings
|
||||||
from ..log import get_logger
|
from ..log import get_logger
|
||||||
from .git_provider import GitProvider
|
from .git_provider import GitProvider, get_git_ssl_env
|
||||||
|
|
||||||
|
|
||||||
class BitbucketServerProvider(GitProvider):
|
class BitbucketServerProvider(GitProvider):
|
||||||
|
|
@ -37,10 +38,28 @@ class BitbucketServerProvider(GitProvider):
|
||||||
self.diff_files = None
|
self.diff_files = None
|
||||||
self.bitbucket_pull_request_api_url = pr_url
|
self.bitbucket_pull_request_api_url = pr_url
|
||||||
self.bearer_token = get_settings().get("BITBUCKET_SERVER.BEARER_TOKEN", None)
|
self.bearer_token = get_settings().get("BITBUCKET_SERVER.BEARER_TOKEN", None)
|
||||||
self.bitbucket_server_url = self._parse_bitbucket_server(url=pr_url)
|
# Get username and password from settings
|
||||||
self.bitbucket_client = bitbucket_client or Bitbucket(url=self.bitbucket_server_url,
|
username = get_settings().get("BITBUCKET_SERVER.USERNAME", None)
|
||||||
token=get_settings().get("BITBUCKET_SERVER.BEARER_TOKEN",
|
password = get_settings().get("BITBUCKET_SERVER.PASSWORD", None)
|
||||||
None))
|
if bitbucket_client: # if Bitbucket client is provided, use it
|
||||||
|
self.bitbucket_client = bitbucket_client
|
||||||
|
self.bitbucket_server_url = getattr(bitbucket_client, 'url', None) or self._parse_bitbucket_server(pr_url)
|
||||||
|
else:
|
||||||
|
self.bitbucket_server_url = self._parse_bitbucket_server(pr_url)
|
||||||
|
if not self.bitbucket_server_url:
|
||||||
|
raise ValueError("Invalid or missing Bitbucket Server URL parsed from PR URL.")
|
||||||
|
|
||||||
|
if self.bearer_token: # if bearer token is provided, use it
|
||||||
|
self.bitbucket_client = Bitbucket(
|
||||||
|
url=self.bitbucket_server_url,
|
||||||
|
token=self.bearer_token
|
||||||
|
)
|
||||||
|
else: # otherwise use username and password
|
||||||
|
self.bitbucket_client = Bitbucket(
|
||||||
|
url=self.bitbucket_server_url,
|
||||||
|
username=username,
|
||||||
|
password=password
|
||||||
|
)
|
||||||
try:
|
try:
|
||||||
self.bitbucket_api_version = parse_version(self.bitbucket_client.get("rest/api/1.0/application-properties").get('version'))
|
self.bitbucket_api_version = parse_version(self.bitbucket_client.get("rest/api/1.0/application-properties").get('version'))
|
||||||
except Exception:
|
except Exception:
|
||||||
|
|
@ -244,7 +263,8 @@ class BitbucketServerProvider(GitProvider):
|
||||||
original_file_content_str = ""
|
original_file_content_str = ""
|
||||||
new_file_content_str = ""
|
new_file_content_str = ""
|
||||||
|
|
||||||
changes = self.bitbucket_client.get_pull_requests_changes(self.workspace_slug, self.repo_slug, self.pr_num)
|
changes_original = list(self.bitbucket_client.get_pull_requests_changes(self.workspace_slug, self.repo_slug, self.pr_num))
|
||||||
|
changes = filter_ignored(changes_original, 'bitbucket_server')
|
||||||
for change in changes:
|
for change in changes:
|
||||||
file_path = change['path']['toString']
|
file_path = change['path']['toString']
|
||||||
if not is_valid_file(file_path.split("/")[-1]):
|
if not is_valid_file(file_path.split("/")[-1]):
|
||||||
|
|
@ -541,5 +561,7 @@ class BitbucketServerProvider(GitProvider):
|
||||||
cli_args = shlex.split(f"git clone -c http.extraHeader='Authorization: Bearer {bearer_token}' "
|
cli_args = shlex.split(f"git clone -c http.extraHeader='Authorization: Bearer {bearer_token}' "
|
||||||
f"--filter=blob:none --depth 1 {repo_url} {dest_folder}")
|
f"--filter=blob:none --depth 1 {repo_url} {dest_folder}")
|
||||||
|
|
||||||
subprocess.run(cli_args, check=True, # check=True will raise an exception if the command fails
|
ssl_env = get_git_ssl_env()
|
||||||
|
|
||||||
|
subprocess.run(cli_args, env=ssl_env, check=True, # check=True will raise an exception if the command fails
|
||||||
stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL, timeout=operation_timeout_in_seconds)
|
stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL, timeout=operation_timeout_in_seconds)
|
||||||
|
|
|
||||||
|
|
@ -103,7 +103,7 @@ def prepare_repo(url: urllib3.util.Url, project, refspec):
|
||||||
repo_url = (f"{url.scheme}://{url.auth}@{url.host}:{url.port}/{project}")
|
repo_url = (f"{url.scheme}://{url.auth}@{url.host}:{url.port}/{project}")
|
||||||
|
|
||||||
directory = pathlib.Path(mkdtemp())
|
directory = pathlib.Path(mkdtemp())
|
||||||
clone(repo_url, directory),
|
clone(repo_url, directory)
|
||||||
fetch(repo_url, refspec, cwd=directory)
|
fetch(repo_url, refspec, cwd=directory)
|
||||||
checkout(cwd=directory)
|
checkout(cwd=directory)
|
||||||
return directory
|
return directory
|
||||||
|
|
|
||||||
|
|
@ -12,6 +12,65 @@ from pr_agent.log import get_logger
|
||||||
|
|
||||||
MAX_FILES_ALLOWED_FULL = 50
|
MAX_FILES_ALLOWED_FULL = 50
|
||||||
|
|
||||||
|
def get_git_ssl_env() -> dict[str, str]:
|
||||||
|
"""
|
||||||
|
Get git SSL configuration arguments for per-command use.
|
||||||
|
This fixes SSL certificate issues when cloning repos with self-signed certificates.
|
||||||
|
Returns the current environment with the addition of SSL config changes if any such SSL certificates exist.
|
||||||
|
"""
|
||||||
|
ssl_cert_file = os.environ.get('SSL_CERT_FILE')
|
||||||
|
requests_ca_bundle = os.environ.get('REQUESTS_CA_BUNDLE')
|
||||||
|
git_ssl_ca_info = os.environ.get('GIT_SSL_CAINFO')
|
||||||
|
|
||||||
|
chosen_cert_file = ""
|
||||||
|
|
||||||
|
# Try SSL_CERT_FILE first
|
||||||
|
if ssl_cert_file:
|
||||||
|
if os.path.exists(ssl_cert_file):
|
||||||
|
if ((requests_ca_bundle and requests_ca_bundle != ssl_cert_file)
|
||||||
|
or (git_ssl_ca_info and git_ssl_ca_info != ssl_cert_file)):
|
||||||
|
get_logger().warning(f"Found mismatch among: SSL_CERT_FILE, REQUESTS_CA_BUNDLE, GIT_SSL_CAINFO. "
|
||||||
|
f"Using the SSL_CERT_FILE to resolve ambiguity.",
|
||||||
|
artifact={"ssl_cert_file": ssl_cert_file, "requests_ca_bundle": requests_ca_bundle,
|
||||||
|
'git_ssl_ca_info': git_ssl_ca_info})
|
||||||
|
else:
|
||||||
|
get_logger().info(f"Using SSL certificate bundle for git operations", artifact={"ssl_cert_file": ssl_cert_file})
|
||||||
|
chosen_cert_file = ssl_cert_file
|
||||||
|
else:
|
||||||
|
get_logger().warning("SSL certificate bundle not found for git operations", artifact={"ssl_cert_file": ssl_cert_file})
|
||||||
|
|
||||||
|
# Fallback to REQUESTS_CA_BUNDLE
|
||||||
|
elif requests_ca_bundle:
|
||||||
|
if os.path.exists(requests_ca_bundle):
|
||||||
|
if (git_ssl_ca_info and git_ssl_ca_info != requests_ca_bundle):
|
||||||
|
get_logger().warning(f"Found mismatch between: REQUESTS_CA_BUNDLE, GIT_SSL_CAINFO. "
|
||||||
|
f"Using the REQUESTS_CA_BUNDLE to resolve ambiguity.",
|
||||||
|
artifact = {"requests_ca_bundle": requests_ca_bundle, 'git_ssl_ca_info': git_ssl_ca_info})
|
||||||
|
else:
|
||||||
|
get_logger().info("Using SSL certificate bundle from REQUESTS_CA_BUNDLE for git operations",
|
||||||
|
artifact={"requests_ca_bundle": requests_ca_bundle})
|
||||||
|
chosen_cert_file = requests_ca_bundle
|
||||||
|
else:
|
||||||
|
get_logger().warning("requests CA bundle not found for git operations", artifact={"requests_ca_bundle": requests_ca_bundle})
|
||||||
|
|
||||||
|
#Fallback to GIT CA:
|
||||||
|
elif git_ssl_ca_info:
|
||||||
|
if os.path.exists(git_ssl_ca_info):
|
||||||
|
get_logger().info("Using git SSL CA info from GIT_SSL_CAINFO for git operations",
|
||||||
|
artifact={"git_ssl_ca_info": git_ssl_ca_info})
|
||||||
|
chosen_cert_file = git_ssl_ca_info
|
||||||
|
else:
|
||||||
|
get_logger().warning("git SSL CA info not found for git operations", artifact={"git_ssl_ca_info": git_ssl_ca_info})
|
||||||
|
|
||||||
|
else:
|
||||||
|
get_logger().warning("Neither SSL_CERT_FILE nor REQUESTS_CA_BUNDLE nor GIT_SSL_CAINFO are defined, or they are defined but not found. Returning environment without SSL configuration")
|
||||||
|
|
||||||
|
returned_env = os.environ.copy()
|
||||||
|
if chosen_cert_file:
|
||||||
|
returned_env.update({"GIT_SSL_CAINFO": chosen_cert_file, "REQUESTS_CA_BUNDLE": chosen_cert_file})
|
||||||
|
return returned_env
|
||||||
|
|
||||||
|
|
||||||
class GitProvider(ABC):
|
class GitProvider(ABC):
|
||||||
@abstractmethod
|
@abstractmethod
|
||||||
def is_supported(self, capability: str) -> bool:
|
def is_supported(self, capability: str) -> bool:
|
||||||
|
|
@ -57,12 +116,21 @@ class GitProvider(ABC):
|
||||||
# #Repo.clone_from(repo_url, dest_folder)
|
# #Repo.clone_from(repo_url, dest_folder)
|
||||||
# , but with throwing an exception upon timeout.
|
# , but with throwing an exception upon timeout.
|
||||||
# Note: This can only be used in context that supports using pipes.
|
# Note: This can only be used in context that supports using pipes.
|
||||||
|
try:
|
||||||
|
ssl_env = get_git_ssl_env()
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().exception(
|
||||||
|
"Failed to prepare SSL environment for git operations, falling back to default env",
|
||||||
|
artifact={"error": e}
|
||||||
|
)
|
||||||
|
ssl_env = os.environ.copy()
|
||||||
|
|
||||||
subprocess.run([
|
subprocess.run([
|
||||||
"git", "clone",
|
"git", "clone",
|
||||||
"--filter=blob:none",
|
"--filter=blob:none",
|
||||||
"--depth", "1",
|
"--depth", "1",
|
||||||
repo_url, dest_folder
|
repo_url, dest_folder
|
||||||
], check=True, # check=True will raise an exception if the command fails
|
], env=ssl_env, check=True, # check=True will raise an exception if the command fails
|
||||||
stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL, timeout=operation_timeout_in_seconds)
|
stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL, timeout=operation_timeout_in_seconds)
|
||||||
|
|
||||||
CLONE_TIMEOUT_SEC = 20
|
CLONE_TIMEOUT_SEC = 20
|
||||||
|
|
@ -376,7 +444,6 @@ def get_main_pr_language(languages, files) -> str:
|
||||||
break
|
break
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
get_logger().exception(f"Failed to get main language: {e}")
|
get_logger().exception(f"Failed to get main language: {e}")
|
||||||
pass
|
|
||||||
|
|
||||||
## old approach:
|
## old approach:
|
||||||
# most_common_extension = max(set(extension_list), key=extension_list.count)
|
# most_common_extension = max(set(extension_list), key=extension_list.count)
|
||||||
|
|
@ -401,7 +468,6 @@ def get_main_pr_language(languages, files) -> str:
|
||||||
|
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
get_logger().exception(e)
|
get_logger().exception(e)
|
||||||
pass
|
|
||||||
|
|
||||||
return main_language_str
|
return main_language_str
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -1,4 +1,3 @@
|
||||||
import hashlib
|
|
||||||
import json
|
import json
|
||||||
from typing import Any, Dict, List, Optional, Set, Tuple
|
from typing import Any, Dict, List, Optional, Set, Tuple
|
||||||
from urllib.parse import urlparse
|
from urllib.parse import urlparse
|
||||||
|
|
@ -31,15 +30,15 @@ class GiteaProvider(GitProvider):
|
||||||
self.pr_url = ""
|
self.pr_url = ""
|
||||||
self.issue_url = ""
|
self.issue_url = ""
|
||||||
|
|
||||||
gitea_access_token = get_settings().get("GITEA.PERSONAL_ACCESS_TOKEN", None)
|
self.gitea_access_token = get_settings().get("GITEA.PERSONAL_ACCESS_TOKEN", None)
|
||||||
if not gitea_access_token:
|
if not self.gitea_access_token:
|
||||||
self.logger.error("Gitea access token not found in settings.")
|
self.logger.error("Gitea access token not found in settings.")
|
||||||
raise ValueError("Gitea access token not found in settings.")
|
raise ValueError("Gitea access token not found in settings.")
|
||||||
|
|
||||||
self.repo_settings = get_settings().get("GITEA.REPO_SETTING", None)
|
self.repo_settings = get_settings().get("GITEA.REPO_SETTING", None)
|
||||||
configuration = giteapy.Configuration()
|
configuration = giteapy.Configuration()
|
||||||
configuration.host = "{}/api/v1".format(self.base_url)
|
configuration.host = "{}/api/v1".format(self.base_url)
|
||||||
configuration.api_key['Authorization'] = f'token {gitea_access_token}'
|
configuration.api_key['Authorization'] = f'token {self.gitea_access_token}'
|
||||||
|
|
||||||
if get_settings().get("GITEA.SKIP_SSL_VERIFICATION", False):
|
if get_settings().get("GITEA.SKIP_SSL_VERIFICATION", False):
|
||||||
configuration.verify_ssl = False
|
configuration.verify_ssl = False
|
||||||
|
|
@ -223,6 +222,19 @@ class GiteaProvider(GitProvider):
|
||||||
def get_issue_url(self) -> str:
|
def get_issue_url(self) -> str:
|
||||||
return self.issue_url
|
return self.issue_url
|
||||||
|
|
||||||
|
def get_latest_commit_url(self) -> str:
|
||||||
|
return self.last_commit.html_url
|
||||||
|
|
||||||
|
def get_comment_url(self, comment) -> str:
|
||||||
|
return comment.html_url
|
||||||
|
|
||||||
|
def publish_persistent_comment(self, pr_comment: str,
|
||||||
|
initial_header: str,
|
||||||
|
update_header: bool = True,
|
||||||
|
name='review',
|
||||||
|
final_update_message=True):
|
||||||
|
self.publish_persistent_comment_full(pr_comment, initial_header, update_header, name, final_update_message)
|
||||||
|
|
||||||
def publish_comment(self, comment: str,is_temporary: bool = False) -> None:
|
def publish_comment(self, comment: str,is_temporary: bool = False) -> None:
|
||||||
"""Publish a comment to the pull request"""
|
"""Publish a comment to the pull request"""
|
||||||
if is_temporary and not get_settings().config.publish_output_progress:
|
if is_temporary and not get_settings().config.publish_output_progress:
|
||||||
|
|
@ -308,7 +320,7 @@ class GiteaProvider(GitProvider):
|
||||||
|
|
||||||
if not response:
|
if not response:
|
||||||
self.logger.error("Failed to publish inline comment")
|
self.logger.error("Failed to publish inline comment")
|
||||||
return None
|
return
|
||||||
|
|
||||||
self.logger.info("Inline comment published")
|
self.logger.info("Inline comment published")
|
||||||
|
|
||||||
|
|
@ -515,6 +527,13 @@ class GiteaProvider(GitProvider):
|
||||||
self.logger.info(f"Generated link: {link}")
|
self.logger.info(f"Generated link: {link}")
|
||||||
return link
|
return link
|
||||||
|
|
||||||
|
def get_pr_id(self):
|
||||||
|
try:
|
||||||
|
pr_id = f"{self.repo}/{self.pr_number}"
|
||||||
|
return pr_id
|
||||||
|
except:
|
||||||
|
return ""
|
||||||
|
|
||||||
def get_files(self) -> List[Dict[str, Any]]:
|
def get_files(self) -> List[Dict[str, Any]]:
|
||||||
"""Get all files in the PR"""
|
"""Get all files in the PR"""
|
||||||
return [file.get("filename","") for file in self.git_files]
|
return [file.get("filename","") for file in self.git_files]
|
||||||
|
|
@ -551,7 +570,7 @@ class GiteaProvider(GitProvider):
|
||||||
if not self.pr:
|
if not self.pr:
|
||||||
self.logger.error("Failed to get PR branch")
|
self.logger.error("Failed to get PR branch")
|
||||||
return ""
|
return ""
|
||||||
|
|
||||||
if not self.pr.head:
|
if not self.pr.head:
|
||||||
self.logger.error("PR head not found")
|
self.logger.error("PR head not found")
|
||||||
return ""
|
return ""
|
||||||
|
|
@ -611,6 +630,9 @@ class GiteaProvider(GitProvider):
|
||||||
"""Check if the provider is supported"""
|
"""Check if the provider is supported"""
|
||||||
return True
|
return True
|
||||||
|
|
||||||
|
def get_git_repo_url(self, issues_or_pr_url: str) -> str:
|
||||||
|
return f"{self.base_url}/{self.owner}/{self.repo}.git" #base_url / <OWNER>/<REPO>.git
|
||||||
|
|
||||||
def publish_description(self, pr_title: str, pr_body: str) -> None:
|
def publish_description(self, pr_title: str, pr_body: str) -> None:
|
||||||
"""Publish PR description"""
|
"""Publish PR description"""
|
||||||
response = self.repo_api.edit_pull_request(
|
response = self.repo_api.edit_pull_request(
|
||||||
|
|
@ -685,6 +707,35 @@ class GiteaProvider(GitProvider):
|
||||||
continue
|
continue
|
||||||
self.logger.info(f"Removed initial comment: {comment.get('comment_id')}")
|
self.logger.info(f"Removed initial comment: {comment.get('comment_id')}")
|
||||||
|
|
||||||
|
#Clone related
|
||||||
|
def _prepare_clone_url_with_token(self, repo_url_to_clone: str) -> str | None:
|
||||||
|
#For example, to clone:
|
||||||
|
#https://github.com/Codium-ai/pr-agent-pro.git
|
||||||
|
#Need to embed inside the github token:
|
||||||
|
#https://<token>@github.com/Codium-ai/pr-agent-pro.git
|
||||||
|
|
||||||
|
gitea_token = self.gitea_access_token
|
||||||
|
gitea_base_url = self.base_url
|
||||||
|
scheme = gitea_base_url.split("://")[0]
|
||||||
|
scheme += "://"
|
||||||
|
if not all([gitea_token, gitea_base_url]):
|
||||||
|
get_logger().error("Either missing auth token or missing base url")
|
||||||
|
return None
|
||||||
|
base_url = gitea_base_url.split(scheme)[1]
|
||||||
|
if not base_url:
|
||||||
|
get_logger().error(f"Base url: {gitea_base_url} has an empty base url")
|
||||||
|
return None
|
||||||
|
if base_url not in repo_url_to_clone:
|
||||||
|
get_logger().error(f"url to clone: {repo_url_to_clone} does not contain {base_url}")
|
||||||
|
return None
|
||||||
|
repo_full_name = repo_url_to_clone.split(base_url)[-1]
|
||||||
|
if not repo_full_name:
|
||||||
|
get_logger().error(f"url to clone: {repo_url_to_clone} is malformed")
|
||||||
|
return None
|
||||||
|
|
||||||
|
clone_url = scheme
|
||||||
|
clone_url += f"{gitea_token}@{base_url}{repo_full_name}"
|
||||||
|
return clone_url
|
||||||
|
|
||||||
class RepoApi(giteapy.RepositoryApi):
|
class RepoApi(giteapy.RepositoryApi):
|
||||||
def __init__(self, client: giteapy.ApiClient):
|
def __init__(self, client: giteapy.ApiClient):
|
||||||
|
|
@ -693,7 +744,7 @@ class RepoApi(giteapy.RepositoryApi):
|
||||||
self.logger = get_logger()
|
self.logger = get_logger()
|
||||||
super().__init__(client)
|
super().__init__(client)
|
||||||
|
|
||||||
def create_inline_comment(self, owner: str, repo: str, pr_number: int, body : str ,commit_id : str, comments: List[Dict[str, Any]]) -> None:
|
def create_inline_comment(self, owner: str, repo: str, pr_number: int, body : str ,commit_id : str, comments: List[Dict[str, Any]]):
|
||||||
body = {
|
body = {
|
||||||
"body": body,
|
"body": body,
|
||||||
"comments": comments,
|
"comments": comments,
|
||||||
|
|
|
||||||
|
|
@ -1,12 +1,14 @@
|
||||||
import difflib
|
import difflib
|
||||||
import hashlib
|
import hashlib
|
||||||
import re
|
import re
|
||||||
from typing import Optional, Tuple, Any, Union
|
import urllib.parse
|
||||||
from urllib.parse import urlparse, parse_qs
|
from typing import Any, Optional, Tuple, Union
|
||||||
|
from urllib.parse import parse_qs, urlparse
|
||||||
|
|
||||||
import gitlab
|
import gitlab
|
||||||
import requests
|
import requests
|
||||||
from gitlab import GitlabGetError, GitlabAuthenticationError, GitlabCreateError, GitlabUpdateError
|
from gitlab import (GitlabAuthenticationError, GitlabCreateError,
|
||||||
|
GitlabGetError, GitlabUpdateError)
|
||||||
|
|
||||||
from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
|
from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
|
||||||
|
|
||||||
|
|
@ -32,13 +34,34 @@ class GitLabProvider(GitProvider):
|
||||||
if not gitlab_url:
|
if not gitlab_url:
|
||||||
raise ValueError("GitLab URL is not set in the config file")
|
raise ValueError("GitLab URL is not set in the config file")
|
||||||
self.gitlab_url = gitlab_url
|
self.gitlab_url = gitlab_url
|
||||||
|
ssl_verify = get_settings().get("GITLAB.SSL_VERIFY", True)
|
||||||
gitlab_access_token = get_settings().get("GITLAB.PERSONAL_ACCESS_TOKEN", None)
|
gitlab_access_token = get_settings().get("GITLAB.PERSONAL_ACCESS_TOKEN", None)
|
||||||
if not gitlab_access_token:
|
if not gitlab_access_token:
|
||||||
raise ValueError("GitLab personal access token is not set in the config file")
|
raise ValueError("GitLab personal access token is not set in the config file")
|
||||||
self.gl = gitlab.Gitlab(
|
# Authentication method selection via configuration
|
||||||
url=gitlab_url,
|
auth_method = get_settings().get("GITLAB.AUTH_TYPE", "oauth_token")
|
||||||
oauth_token=gitlab_access_token
|
|
||||||
)
|
# Basic validation of authentication type
|
||||||
|
if auth_method not in ["oauth_token", "private_token"]:
|
||||||
|
raise ValueError(f"Unsupported GITLAB.AUTH_TYPE: '{auth_method}'. "
|
||||||
|
f"Must be 'oauth_token' or 'private_token'.")
|
||||||
|
|
||||||
|
# Create GitLab instance based on authentication method
|
||||||
|
try:
|
||||||
|
if auth_method == "oauth_token":
|
||||||
|
self.gl = gitlab.Gitlab(
|
||||||
|
url=gitlab_url,
|
||||||
|
oauth_token=gitlab_access_token,
|
||||||
|
ssl_verify=ssl_verify
|
||||||
|
)
|
||||||
|
else: # private_token
|
||||||
|
self.gl = gitlab.Gitlab(
|
||||||
|
url=gitlab_url,
|
||||||
|
private_token=gitlab_access_token
|
||||||
|
)
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().error(f"Failed to create GitLab instance: {e}")
|
||||||
|
raise ValueError(f"Unable to authenticate with GitLab: {e}")
|
||||||
self.max_comment_chars = 65000
|
self.max_comment_chars = 65000
|
||||||
self.id_project = None
|
self.id_project = None
|
||||||
self.id_mr = None
|
self.id_mr = None
|
||||||
|
|
@ -46,12 +69,222 @@ class GitLabProvider(GitProvider):
|
||||||
self.diff_files = None
|
self.diff_files = None
|
||||||
self.git_files = None
|
self.git_files = None
|
||||||
self.temp_comments = []
|
self.temp_comments = []
|
||||||
|
self._submodule_cache: dict[tuple[str, str, str], list[dict]] = {}
|
||||||
self.pr_url = merge_request_url
|
self.pr_url = merge_request_url
|
||||||
self._set_merge_request(merge_request_url)
|
self._set_merge_request(merge_request_url)
|
||||||
self.RE_HUNK_HEADER = re.compile(
|
self.RE_HUNK_HEADER = re.compile(
|
||||||
r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
|
r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
|
||||||
self.incremental = incremental
|
self.incremental = incremental
|
||||||
|
|
||||||
|
# --- submodule expansion helpers (opt-in) ---
|
||||||
|
def _get_gitmodules_map(self) -> dict[str, str]:
|
||||||
|
"""
|
||||||
|
Return {submodule_path -> repo_url} from '.gitmodules' (best effort).
|
||||||
|
Tries target branch first, then source branch. Always returns text.
|
||||||
|
"""
|
||||||
|
try:
|
||||||
|
proj = self.gl.projects.get(self.id_project)
|
||||||
|
except Exception:
|
||||||
|
return {}
|
||||||
|
|
||||||
|
import base64
|
||||||
|
|
||||||
|
def _read_text(ref: str | None) -> str | None:
|
||||||
|
if not ref:
|
||||||
|
return None
|
||||||
|
try:
|
||||||
|
f = proj.files.get(file_path=".gitmodules", ref=ref)
|
||||||
|
except Exception:
|
||||||
|
return None
|
||||||
|
|
||||||
|
# 1) python-gitlab File.decode() – usually returns BYTES
|
||||||
|
try:
|
||||||
|
raw = f.decode()
|
||||||
|
if isinstance(raw, (bytes, bytearray)):
|
||||||
|
return raw.decode("utf-8", "ignore")
|
||||||
|
if isinstance(raw, str):
|
||||||
|
return raw
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
|
|
||||||
|
# 2) fallback: base64 decode f.content
|
||||||
|
try:
|
||||||
|
c = getattr(f, "content", None)
|
||||||
|
if c:
|
||||||
|
return base64.b64decode(c).decode("utf-8", "ignore")
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
|
|
||||||
|
return None
|
||||||
|
|
||||||
|
content = (
|
||||||
|
_read_text(getattr(self.mr, "target_branch", None))
|
||||||
|
or _read_text(getattr(self.mr, "source_branch", None))
|
||||||
|
)
|
||||||
|
if not content:
|
||||||
|
return {}
|
||||||
|
|
||||||
|
import configparser
|
||||||
|
|
||||||
|
parser = configparser.ConfigParser(
|
||||||
|
delimiters=("=",),
|
||||||
|
interpolation=None,
|
||||||
|
inline_comment_prefixes=("#", ";"),
|
||||||
|
strict=False,
|
||||||
|
)
|
||||||
|
try:
|
||||||
|
parser.read_string(content)
|
||||||
|
except Exception:
|
||||||
|
return {}
|
||||||
|
|
||||||
|
out: dict[str, str] = {}
|
||||||
|
for section in parser.sections():
|
||||||
|
if not section.lower().startswith("submodule"):
|
||||||
|
continue
|
||||||
|
path = parser.get(section, "path", fallback=None)
|
||||||
|
url = parser.get(section, "url", fallback=None)
|
||||||
|
if path and url:
|
||||||
|
path = path.strip().strip('"').strip("'")
|
||||||
|
url = url.strip().strip('"').strip("'")
|
||||||
|
out[path] = url
|
||||||
|
return out
|
||||||
|
|
||||||
|
def _url_to_project_path(self, url: str) -> str | None:
|
||||||
|
"""
|
||||||
|
Convert ssh/https GitLab URL to 'group/subgroup/repo' project path.
|
||||||
|
"""
|
||||||
|
try:
|
||||||
|
if url.startswith("git@") and ":" in url:
|
||||||
|
path = url.split(":", 1)[1]
|
||||||
|
else:
|
||||||
|
path = urllib.parse.urlparse(url).path.lstrip("/")
|
||||||
|
if path.endswith(".git"):
|
||||||
|
path = path[:-4]
|
||||||
|
return path or None
|
||||||
|
except Exception:
|
||||||
|
return None
|
||||||
|
|
||||||
|
def _project_by_path(self, proj_path: str):
|
||||||
|
"""
|
||||||
|
Resolve a project by path with multiple strategies:
|
||||||
|
1) URL-encoded path_with_namespace
|
||||||
|
2) Raw path_with_namespace
|
||||||
|
3) Search fallback + exact match on path_with_namespace (case-insensitive)
|
||||||
|
Returns a project object or None.
|
||||||
|
"""
|
||||||
|
if not proj_path:
|
||||||
|
return None
|
||||||
|
|
||||||
|
# 1) Encoded
|
||||||
|
try:
|
||||||
|
enc = urllib.parse.quote_plus(proj_path)
|
||||||
|
return self.gl.projects.get(enc)
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
|
|
||||||
|
# 2) Raw
|
||||||
|
try:
|
||||||
|
return self.gl.projects.get(proj_path)
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
|
|
||||||
|
# 3) Search fallback
|
||||||
|
try:
|
||||||
|
name = proj_path.split("/")[-1]
|
||||||
|
# membership=True so we don't leak other people's repos
|
||||||
|
matches = self.gl.projects.list(search=name, simple=True, membership=True, per_page=100)
|
||||||
|
# prefer exact path_with_namespace match (case-insensitive)
|
||||||
|
for p in matches:
|
||||||
|
pwn = getattr(p, "path_with_namespace", "")
|
||||||
|
if pwn.lower() == proj_path.lower():
|
||||||
|
return self.gl.projects.get(p.id)
|
||||||
|
if matches:
|
||||||
|
get_logger().warning(f"[submodule] no exact match for {proj_path} (skip)")
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
|
|
||||||
|
return None
|
||||||
|
|
||||||
|
def _compare_submodule(self, proj_path: str, old_sha: str, new_sha: str) -> list[dict]:
|
||||||
|
"""
|
||||||
|
Call repository_compare on submodule project; return list of diffs.
|
||||||
|
"""
|
||||||
|
key = (proj_path, old_sha, new_sha)
|
||||||
|
if key in self._submodule_cache:
|
||||||
|
return self._submodule_cache[key]
|
||||||
|
try:
|
||||||
|
proj = self._project_by_path(proj_path)
|
||||||
|
if proj is None:
|
||||||
|
get_logger().warning(f"[submodule] resolve failed for {proj_path}")
|
||||||
|
self._submodule_cache[key] = []
|
||||||
|
return []
|
||||||
|
cmp = proj.repository_compare(old_sha, new_sha)
|
||||||
|
if isinstance(cmp, dict):
|
||||||
|
diffs = cmp.get("diffs", []) or []
|
||||||
|
else:
|
||||||
|
diffs = []
|
||||||
|
self._submodule_cache[key] = diffs
|
||||||
|
return diffs
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().warning(f"[submodule] compare failed for {proj_path} {old_sha}..{new_sha}: {e}")
|
||||||
|
self._submodule_cache[key] = []
|
||||||
|
return []
|
||||||
|
|
||||||
|
def _expand_submodule_changes(self, changes: list[dict]) -> list[dict]:
|
||||||
|
"""
|
||||||
|
If enabled, expand 'Subproject commit' bumps into real file diffs from the submodule.
|
||||||
|
Soft-fail on any issue.
|
||||||
|
"""
|
||||||
|
try:
|
||||||
|
if not bool(get_settings().get("GITLAB.EXPAND_SUBMODULE_DIFFS", False)):
|
||||||
|
return changes
|
||||||
|
except Exception:
|
||||||
|
return changes
|
||||||
|
|
||||||
|
gitmodules = self._get_gitmodules_map()
|
||||||
|
if not gitmodules:
|
||||||
|
return changes
|
||||||
|
|
||||||
|
out = list(changes)
|
||||||
|
for ch in changes:
|
||||||
|
patch = ch.get("diff") or ""
|
||||||
|
if "Subproject commit" not in patch:
|
||||||
|
continue
|
||||||
|
|
||||||
|
# Extract old/new SHAs from the hunk
|
||||||
|
old_m = re.search(r"^-Subproject commit ([0-9a-f]{7,40})", patch, re.M)
|
||||||
|
new_m = re.search(r"^\+Subproject commit ([0-9a-f]{7,40})", patch, re.M)
|
||||||
|
if not (old_m and new_m):
|
||||||
|
continue
|
||||||
|
old_sha, new_sha = old_m.group(1), new_m.group(1)
|
||||||
|
|
||||||
|
sub_path = ch.get("new_path") or ch.get("old_path") or ""
|
||||||
|
repo_url = gitmodules.get(sub_path)
|
||||||
|
if not repo_url:
|
||||||
|
get_logger().warning(f"[submodule] no url for '{sub_path}' in .gitmodules (skip)")
|
||||||
|
continue
|
||||||
|
|
||||||
|
proj_path = self._url_to_project_path(repo_url)
|
||||||
|
if not proj_path:
|
||||||
|
get_logger().warning(f"[submodule] cannot parse project path from url '{repo_url}' (skip)")
|
||||||
|
continue
|
||||||
|
|
||||||
|
get_logger().info(f"[submodule] {sub_path} url={repo_url} -> proj_path={proj_path}")
|
||||||
|
sub_diffs = self._compare_submodule(proj_path, old_sha, new_sha)
|
||||||
|
for sd in sub_diffs:
|
||||||
|
sd_diff = sd.get("diff") or ""
|
||||||
|
sd_old = sd.get("old_path") or sd.get("a_path") or ""
|
||||||
|
sd_new = sd.get("new_path") or sd.get("b_path") or sd_old
|
||||||
|
out.append({
|
||||||
|
"old_path": f"{sub_path}/{sd_old}" if sd_old else sub_path,
|
||||||
|
"new_path": f"{sub_path}/{sd_new}" if sd_new else sub_path,
|
||||||
|
"diff": sd_diff,
|
||||||
|
"new_file": sd.get("new_file", False),
|
||||||
|
"deleted_file": sd.get("deleted_file", False),
|
||||||
|
"renamed_file": sd.get("renamed_file", False),
|
||||||
|
})
|
||||||
|
return out
|
||||||
|
|
||||||
def is_supported(self, capability: str) -> bool:
|
def is_supported(self, capability: str) -> bool:
|
||||||
if capability in ['get_issue_comments', 'create_inline_comment', 'publish_inline_comments',
|
if capability in ['get_issue_comments', 'create_inline_comment', 'publish_inline_comments',
|
||||||
'publish_file_comments']: # gfm_markdown is supported in gitlab !
|
'publish_file_comments']: # gfm_markdown is supported in gitlab !
|
||||||
|
|
@ -130,11 +363,11 @@ class GitLabProvider(GitProvider):
|
||||||
"""Create or update a file in the GitLab repository."""
|
"""Create or update a file in the GitLab repository."""
|
||||||
try:
|
try:
|
||||||
project = self.gl.projects.get(self.id_project)
|
project = self.gl.projects.get(self.id_project)
|
||||||
|
|
||||||
if not message:
|
if not message:
|
||||||
action = "Update" if contents else "Create"
|
action = "Update" if contents else "Create"
|
||||||
message = f"{action} {file_path}"
|
message = f"{action} {file_path}"
|
||||||
|
|
||||||
try:
|
try:
|
||||||
existing_file = project.files.get(file_path, branch)
|
existing_file = project.files.get(file_path, branch)
|
||||||
existing_file.content = contents
|
existing_file.content = contents
|
||||||
|
|
@ -172,7 +405,9 @@ class GitLabProvider(GitProvider):
|
||||||
return self.diff_files
|
return self.diff_files
|
||||||
|
|
||||||
# filter files using [ignore] patterns
|
# filter files using [ignore] patterns
|
||||||
diffs_original = self.mr.changes()['changes']
|
raw_changes = self.mr.changes().get('changes', [])
|
||||||
|
raw_changes = self._expand_submodule_changes(raw_changes)
|
||||||
|
diffs_original = raw_changes
|
||||||
diffs = filter_ignored(diffs_original, 'gitlab')
|
diffs = filter_ignored(diffs_original, 'gitlab')
|
||||||
if diffs != diffs_original:
|
if diffs != diffs_original:
|
||||||
try:
|
try:
|
||||||
|
|
@ -242,7 +477,9 @@ class GitLabProvider(GitProvider):
|
||||||
|
|
||||||
def get_files(self) -> list:
|
def get_files(self) -> list:
|
||||||
if not self.git_files:
|
if not self.git_files:
|
||||||
self.git_files = [change['new_path'] for change in self.mr.changes()['changes']]
|
raw_changes = self.mr.changes().get('changes', [])
|
||||||
|
raw_changes = self._expand_submodule_changes(raw_changes)
|
||||||
|
self.git_files = [c.get('new_path') for c in raw_changes if c.get('new_path')]
|
||||||
return self.git_files
|
return self.git_files
|
||||||
|
|
||||||
def publish_description(self, pr_title: str, pr_body: str):
|
def publish_description(self, pr_title: str, pr_body: str):
|
||||||
|
|
@ -398,7 +635,9 @@ class GitLabProvider(GitProvider):
|
||||||
get_logger().exception(f"Failed to create comment in MR {self.id_mr}")
|
get_logger().exception(f"Failed to create comment in MR {self.id_mr}")
|
||||||
|
|
||||||
def get_relevant_diff(self, relevant_file: str, relevant_line_in_file: str) -> Optional[dict]:
|
def get_relevant_diff(self, relevant_file: str, relevant_line_in_file: str) -> Optional[dict]:
|
||||||
changes = self.mr.changes() # Retrieve the changes for the merge request once
|
_changes = self.mr.changes() # dict
|
||||||
|
_changes['changes'] = self._expand_submodule_changes(_changes.get('changes', []))
|
||||||
|
changes = _changes
|
||||||
if not changes:
|
if not changes:
|
||||||
get_logger().error('No changes found for the merge request.')
|
get_logger().error('No changes found for the merge request.')
|
||||||
return None
|
return None
|
||||||
|
|
@ -561,10 +800,52 @@ class GitLabProvider(GitProvider):
|
||||||
return self.id_project.split('/')[0]
|
return self.id_project.split('/')[0]
|
||||||
|
|
||||||
def add_eyes_reaction(self, issue_comment_id: int, disable_eyes: bool = False) -> Optional[int]:
|
def add_eyes_reaction(self, issue_comment_id: int, disable_eyes: bool = False) -> Optional[int]:
|
||||||
return True
|
if disable_eyes:
|
||||||
|
return None
|
||||||
|
try:
|
||||||
|
if not self.id_mr:
|
||||||
|
get_logger().warning("Cannot add eyes reaction: merge request ID is not set.")
|
||||||
|
return None
|
||||||
|
|
||||||
def remove_reaction(self, issue_comment_id: int, reaction_id: int) -> bool:
|
mr = self.gl.projects.get(self.id_project).mergerequests.get(self.id_mr)
|
||||||
return True
|
comment = mr.notes.get(issue_comment_id)
|
||||||
|
|
||||||
|
if not comment:
|
||||||
|
get_logger().warning(f"Comment with ID {issue_comment_id} not found in merge request {self.id_mr}.")
|
||||||
|
return None
|
||||||
|
|
||||||
|
award_emoji = comment.awardemojis.create({
|
||||||
|
'name': 'eyes'
|
||||||
|
})
|
||||||
|
return award_emoji.id
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().warning(f"Failed to add eyes reaction, error: {e}")
|
||||||
|
return None
|
||||||
|
|
||||||
|
def remove_reaction(self, issue_comment_id: int, reaction_id: str) -> bool:
|
||||||
|
try:
|
||||||
|
if not self.id_mr:
|
||||||
|
get_logger().warning("Cannot remove reaction: merge request ID is not set.")
|
||||||
|
return False
|
||||||
|
|
||||||
|
mr = self.gl.projects.get(self.id_project).mergerequests.get(self.id_mr)
|
||||||
|
comment = mr.notes.get(issue_comment_id)
|
||||||
|
|
||||||
|
if not comment:
|
||||||
|
get_logger().warning(f"Comment with ID {issue_comment_id} not found in merge request {self.id_mr}.")
|
||||||
|
return False
|
||||||
|
|
||||||
|
reactions = comment.awardemojis.list()
|
||||||
|
for reaction in reactions:
|
||||||
|
if reaction.name == reaction_id:
|
||||||
|
reaction.delete()
|
||||||
|
return True
|
||||||
|
|
||||||
|
get_logger().warning(f"Reaction '{reaction_id}' not found in comment {issue_comment_id}.")
|
||||||
|
return False
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().warning(f"Failed to remove reaction, error: {e}")
|
||||||
|
return False
|
||||||
|
|
||||||
def _parse_merge_request_url(self, merge_request_url: str) -> Tuple[str, int]:
|
def _parse_merge_request_url(self, merge_request_url: str) -> Tuple[str, int]:
|
||||||
parsed_url = urlparse(merge_request_url)
|
parsed_url = urlparse(merge_request_url)
|
||||||
|
|
@ -677,7 +958,7 @@ class GitLabProvider(GitProvider):
|
||||||
get_logger().error(f"Repo URL: {repo_url_to_clone} is not a valid gitlab URL.")
|
get_logger().error(f"Repo URL: {repo_url_to_clone} is not a valid gitlab URL.")
|
||||||
return None
|
return None
|
||||||
(scheme, base_url) = repo_url_to_clone.split("gitlab.")
|
(scheme, base_url) = repo_url_to_clone.split("gitlab.")
|
||||||
access_token = self.gl.oauth_token
|
access_token = getattr(self.gl, 'oauth_token', None) or getattr(self.gl, 'private_token', None)
|
||||||
if not all([scheme, access_token, base_url]):
|
if not all([scheme, access_token, base_url]):
|
||||||
get_logger().error(f"Either no access token found, or repo URL: {repo_url_to_clone} "
|
get_logger().error(f"Either no access token found, or repo URL: {repo_url_to_clone} "
|
||||||
f"is missing prefix: {scheme} and/or base URL: {base_url}.")
|
f"is missing prefix: {scheme} and/or base URL: {base_url}.")
|
||||||
|
|
|
||||||
|
|
@ -1,6 +1,7 @@
|
||||||
import copy
|
import copy
|
||||||
import os
|
import os
|
||||||
import tempfile
|
import tempfile
|
||||||
|
import traceback
|
||||||
|
|
||||||
from dynaconf import Dynaconf
|
from dynaconf import Dynaconf
|
||||||
from starlette_context import context
|
from starlette_context import context
|
||||||
|
|
@ -35,8 +36,34 @@ def apply_repo_settings(pr_url):
|
||||||
try:
|
try:
|
||||||
fd, repo_settings_file = tempfile.mkstemp(suffix='.toml')
|
fd, repo_settings_file = tempfile.mkstemp(suffix='.toml')
|
||||||
os.write(fd, repo_settings)
|
os.write(fd, repo_settings)
|
||||||
new_settings = Dynaconf(settings_files=[repo_settings_file])
|
|
||||||
|
try:
|
||||||
|
dynconf_kwargs = {'core_loaders': [], # DISABLE default loaders, otherwise will load toml files more than once.
|
||||||
|
'loaders': ['pr_agent.custom_merge_loader'],
|
||||||
|
# Use a custom loader to merge sections, but overwrite their overlapping values. Don't involve ENV variables.
|
||||||
|
'merge_enabled': True # Merge multiple files; ensures [XYZ] sections only overwrite overlapping keys, not whole sections.
|
||||||
|
}
|
||||||
|
|
||||||
|
new_settings = Dynaconf(settings_files=[repo_settings_file],
|
||||||
|
# Disable all dynamic loading features
|
||||||
|
load_dotenv=False, # Don't load .env files
|
||||||
|
envvar_prefix=False, # Drop DYNACONF for env. variables
|
||||||
|
**dynconf_kwargs
|
||||||
|
)
|
||||||
|
except TypeError as e:
|
||||||
|
# Fallback for older Dynaconf versions that don't support these parameters
|
||||||
|
get_logger().warning(
|
||||||
|
"Your Dynaconf version does not support disabled 'load_dotenv'/'merge_enabled' parameters. "
|
||||||
|
"Loading repo settings without these security features. "
|
||||||
|
"Please upgrade Dynaconf for better security.",
|
||||||
|
artifact={"error": e, "traceback": traceback.format_exc()})
|
||||||
|
new_settings = Dynaconf(settings_files=[repo_settings_file])
|
||||||
|
|
||||||
for section, contents in new_settings.as_dict().items():
|
for section, contents in new_settings.as_dict().items():
|
||||||
|
if not contents:
|
||||||
|
# Skip excluded items, such as forbidden to load env.
|
||||||
|
get_logger().debug(f"Skipping a section: {section} which is not allowed")
|
||||||
|
continue
|
||||||
section_dict = copy.deepcopy(get_settings().as_dict().get(section, {}))
|
section_dict = copy.deepcopy(get_settings().as_dict().get(section, {}))
|
||||||
for key, value in contents.items():
|
for key, value in contents.items():
|
||||||
section_dict[key] = value
|
section_dict[key] = value
|
||||||
|
|
|
||||||
38
pr_agent/servers/atlassian-connect-qodo-merge.json
Normal file
38
pr_agent/servers/atlassian-connect-qodo-merge.json
Normal file
|
|
@ -0,0 +1,38 @@
|
||||||
|
{
|
||||||
|
"name": "Qodo Merge",
|
||||||
|
"description": "Qodo Merge",
|
||||||
|
"key": "app_key",
|
||||||
|
"vendor": {
|
||||||
|
"name": "Qodo",
|
||||||
|
"url": "https://qodo.ai"
|
||||||
|
},
|
||||||
|
"authentication": {
|
||||||
|
"type": "jwt"
|
||||||
|
},
|
||||||
|
"baseUrl": "base_url",
|
||||||
|
"lifecycle": {
|
||||||
|
"installed": "/installed",
|
||||||
|
"uninstalled": "/uninstalled"
|
||||||
|
},
|
||||||
|
"scopes": [
|
||||||
|
"account",
|
||||||
|
"repository:write",
|
||||||
|
"pullrequest:write",
|
||||||
|
"wiki"
|
||||||
|
],
|
||||||
|
"contexts": [
|
||||||
|
"account"
|
||||||
|
],
|
||||||
|
"modules": {
|
||||||
|
"webhooks": [
|
||||||
|
{
|
||||||
|
"event": "*",
|
||||||
|
"url": "/webhook"
|
||||||
|
}
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"links": {
|
||||||
|
"privacy": "https://qodo.ai/privacy-policy",
|
||||||
|
"terms": "https://qodo.ai/terms"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
@ -83,16 +83,79 @@ def _get_username(data):
|
||||||
return ""
|
return ""
|
||||||
|
|
||||||
|
|
||||||
|
async def _validate_time_from_last_commit_to_pr_update(data: dict) -> bool:
|
||||||
|
is_valid_push = False
|
||||||
|
try:
|
||||||
|
data_inner = data.get('data', {})
|
||||||
|
if not data_inner:
|
||||||
|
get_logger().error("No data found in the webhook payload")
|
||||||
|
return True
|
||||||
|
pull_request = data_inner.get('pullrequest', {})
|
||||||
|
commits_api = pull_request.get('links', {}).get('commits', {}).get('href')
|
||||||
|
if not commits_api:
|
||||||
|
return False
|
||||||
|
if not pull_request.get('updated_on'):
|
||||||
|
return False
|
||||||
|
bearer_token = context.get('bitbucket_bearer_token')
|
||||||
|
headers = {
|
||||||
|
'Authorization': f'Bearer {bearer_token}',
|
||||||
|
'Accept': 'application/json'
|
||||||
|
}
|
||||||
|
response = requests.get(commits_api, headers=headers)
|
||||||
|
if response.status_code != 200:
|
||||||
|
get_logger().warning(f"Bitbucket commits API returned {response.status_code} for {commits_api}")
|
||||||
|
return False
|
||||||
|
|
||||||
|
username =_get_username(data)
|
||||||
|
commits_data = response.json() or {}
|
||||||
|
values = commits_data.get('values') or []
|
||||||
|
if (not values or not isinstance(values, list) or not values[0].get('author') or not values[0]['author'].get('user')
|
||||||
|
or not values[0]['author']['user'].get('display_name')):
|
||||||
|
get_logger().warning("No commits returned for pull request or one of the required fields missing; skipping push validation",
|
||||||
|
artifact={'values': values})
|
||||||
|
return False
|
||||||
|
commit_username = commits_data['values'][0]['author']['user']['display_name']
|
||||||
|
if username != commit_username:
|
||||||
|
get_logger().warning(f"Mismatch in username {username} vs. commit_username {commit_username}")
|
||||||
|
return False
|
||||||
|
|
||||||
|
time_pr_updated = pull_request['updated_on']
|
||||||
|
time_last_commit = commits_data['values'][0]['date']
|
||||||
|
from datetime import datetime
|
||||||
|
ts1 = datetime.fromisoformat(time_pr_updated)
|
||||||
|
ts2 = datetime.fromisoformat(time_last_commit)
|
||||||
|
diff = (ts1 - ts2).total_seconds()
|
||||||
|
max_delta_seconds = 15
|
||||||
|
if diff > 0 and diff < max_delta_seconds:
|
||||||
|
is_valid_push = True
|
||||||
|
else:
|
||||||
|
get_logger().debug(f"Too much time passed since last commit",
|
||||||
|
artifact={'updated': time_pr_updated, 'last_commit': time_last_commit})
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().exception(f"Failed to validate time difference between last commit and PR update",
|
||||||
|
artifact={'error': e, 'data': data})
|
||||||
|
return is_valid_push
|
||||||
|
|
||||||
async def _perform_commands_bitbucket(commands_conf: str, agent: PRAgent, api_url: str, log_context: dict, data: dict):
|
async def _perform_commands_bitbucket(commands_conf: str, agent: PRAgent, api_url: str, log_context: dict, data: dict):
|
||||||
apply_repo_settings(api_url)
|
apply_repo_settings(api_url)
|
||||||
if commands_conf == "pr_commands" and get_settings().config.disable_auto_feedback: # auto commands for PR, and auto feedback is disabled
|
if commands_conf == "pr_commands" and get_settings().config.disable_auto_feedback: # auto commands for PR, and auto feedback is disabled
|
||||||
get_logger().info(f"Auto feedback is disabled, skipping auto commands for PR {api_url=}")
|
get_logger().info(f"Auto feedback is disabled, skipping auto commands for PR {api_url=}")
|
||||||
return
|
return
|
||||||
|
if commands_conf == "push_commands":
|
||||||
|
if not get_settings().get("bitbucket_app.handle_push_trigger"):
|
||||||
|
get_logger().info(
|
||||||
|
"Bitbucket push trigger handling disabled via config; skipping push commands")
|
||||||
|
return
|
||||||
if data.get("event", "") == "pullrequest:created":
|
if data.get("event", "") == "pullrequest:created":
|
||||||
if not should_process_pr_logic(data):
|
if not should_process_pr_logic(data):
|
||||||
return
|
return
|
||||||
commands = get_settings().get(f"bitbucket_app.{commands_conf}", {})
|
commands = get_settings().get(f"bitbucket_app.{commands_conf}", {})
|
||||||
get_settings().set("config.is_auto_command", True)
|
get_settings().set("config.is_auto_command", True)
|
||||||
|
if commands_conf == "push_commands":
|
||||||
|
is_valid_push = await _validate_time_from_last_commit_to_pr_update(data)
|
||||||
|
if not is_valid_push:
|
||||||
|
get_logger().info(f"Bitbucket skipping 'pullrequest:updated' for push commands")
|
||||||
|
return
|
||||||
for command in commands:
|
for command in commands:
|
||||||
try:
|
try:
|
||||||
split_command = command.split(" ")
|
split_command = command.split(" ")
|
||||||
|
|
@ -139,7 +202,7 @@ def should_process_pr_logic(data) -> bool:
|
||||||
# logic to ignore PRs from specific users
|
# logic to ignore PRs from specific users
|
||||||
ignore_pr_users = get_settings().get("CONFIG.IGNORE_PR_AUTHORS", [])
|
ignore_pr_users = get_settings().get("CONFIG.IGNORE_PR_AUTHORS", [])
|
||||||
if ignore_pr_users and sender:
|
if ignore_pr_users and sender:
|
||||||
if sender in ignore_pr_users:
|
if any(re.search(regex, sender) for regex in ignore_pr_users):
|
||||||
get_logger().info(f"Ignoring PR from user '{sender}' due to 'config.ignore_pr_authors' setting")
|
get_logger().info(f"Ignoring PR from user '{sender}' due to 'config.ignore_pr_authors' setting")
|
||||||
return False
|
return False
|
||||||
|
|
||||||
|
|
@ -215,11 +278,21 @@ async def handle_github_webhooks(background_tasks: BackgroundTasks, request: Req
|
||||||
log_context["event"] = "pull_request"
|
log_context["event"] = "pull_request"
|
||||||
if pr_url:
|
if pr_url:
|
||||||
with get_logger().contextualize(**log_context):
|
with get_logger().contextualize(**log_context):
|
||||||
apply_repo_settings(pr_url)
|
|
||||||
if get_identity_provider().verify_eligibility("bitbucket",
|
if get_identity_provider().verify_eligibility("bitbucket",
|
||||||
sender_id, pr_url) is not Eligibility.NOT_ELIGIBLE:
|
sender_id, pr_url) is not Eligibility.NOT_ELIGIBLE:
|
||||||
if get_settings().get("bitbucket_app.pr_commands"):
|
if get_settings().get("bitbucket_app.pr_commands"):
|
||||||
await _perform_commands_bitbucket("pr_commands", PRAgent(), pr_url, log_context, data)
|
await _perform_commands_bitbucket("pr_commands", agent, pr_url, log_context, data)
|
||||||
|
elif event == "pullrequest:updated": # PR updated, might be from a push (we will validate this later)
|
||||||
|
pr_url = data["data"]["pullrequest"]["links"]["html"]["href"]
|
||||||
|
log_context["api_url"] = pr_url
|
||||||
|
log_context["event"] = "pull_request"
|
||||||
|
if pr_url:
|
||||||
|
with get_logger().contextualize(**log_context):
|
||||||
|
if get_identity_provider().verify_eligibility("bitbucket",
|
||||||
|
sender_id, pr_url) is not Eligibility.NOT_ELIGIBLE:
|
||||||
|
|
||||||
|
if get_settings().get("bitbucket_app.push_commands"):
|
||||||
|
await _perform_commands_bitbucket("push_commands", agent, pr_url, log_context, data)
|
||||||
elif event == "pullrequest:comment_created":
|
elif event == "pullrequest:comment_created":
|
||||||
pr_url = data["data"]["pullrequest"]["links"]["html"]["href"]
|
pr_url = data["data"]["pullrequest"]["links"]["html"]["href"]
|
||||||
log_context["api_url"] = pr_url
|
log_context["api_url"] = pr_url
|
||||||
|
|
|
||||||
|
|
@ -1,6 +1,7 @@
|
||||||
import ast
|
import ast
|
||||||
import json
|
import json
|
||||||
import os
|
import os
|
||||||
|
import re
|
||||||
from typing import List
|
from typing import List
|
||||||
|
|
||||||
import uvicorn
|
import uvicorn
|
||||||
|
|
@ -40,6 +41,88 @@ def handle_request(
|
||||||
|
|
||||||
background_tasks.add_task(inner)
|
background_tasks.add_task(inner)
|
||||||
|
|
||||||
|
def should_process_pr_logic(data) -> bool:
|
||||||
|
try:
|
||||||
|
pr_data = data.get("pullRequest", {})
|
||||||
|
title = pr_data.get("title", "")
|
||||||
|
|
||||||
|
from_ref = pr_data.get("fromRef", {})
|
||||||
|
source_branch = from_ref.get("displayId", "") if from_ref else ""
|
||||||
|
|
||||||
|
to_ref = pr_data.get("toRef", {})
|
||||||
|
target_branch = to_ref.get("displayId", "") if to_ref else ""
|
||||||
|
|
||||||
|
author = pr_data.get("author", {})
|
||||||
|
user = author.get("user", {}) if author else {}
|
||||||
|
sender = user.get("name", "") if user else ""
|
||||||
|
|
||||||
|
repository = to_ref.get("repository", {}) if to_ref else {}
|
||||||
|
project = repository.get("project", {}) if repository else {}
|
||||||
|
project_key = project.get("key", "") if project else ""
|
||||||
|
repo_slug = repository.get("slug", "") if repository else ""
|
||||||
|
|
||||||
|
repo_full_name = f"{project_key}/{repo_slug}" if project_key and repo_slug else ""
|
||||||
|
pr_id = pr_data.get("id", None)
|
||||||
|
|
||||||
|
# To ignore PRs from specific repositories
|
||||||
|
ignore_repos = get_settings().get("CONFIG.IGNORE_REPOSITORIES", [])
|
||||||
|
if repo_full_name and ignore_repos:
|
||||||
|
if any(re.search(regex, repo_full_name) for regex in ignore_repos):
|
||||||
|
get_logger().info(f"Ignoring PR from repository '{repo_full_name}' due to 'config.ignore_repositories' setting")
|
||||||
|
return False
|
||||||
|
|
||||||
|
# To ignore PRs from specific users
|
||||||
|
ignore_pr_users = get_settings().get("CONFIG.IGNORE_PR_AUTHORS", [])
|
||||||
|
if ignore_pr_users and sender:
|
||||||
|
if any(re.search(regex, sender) for regex in ignore_pr_users):
|
||||||
|
get_logger().info(f"Ignoring PR from user '{sender}' due to 'config.ignore_pr_authors' setting")
|
||||||
|
return False
|
||||||
|
|
||||||
|
# To ignore PRs with specific titles
|
||||||
|
if title:
|
||||||
|
ignore_pr_title_re = get_settings().get("CONFIG.IGNORE_PR_TITLE", [])
|
||||||
|
if not isinstance(ignore_pr_title_re, list):
|
||||||
|
ignore_pr_title_re = [ignore_pr_title_re]
|
||||||
|
if ignore_pr_title_re and any(re.search(regex, title) for regex in ignore_pr_title_re):
|
||||||
|
get_logger().info(f"Ignoring PR with title '{title}' due to config.ignore_pr_title setting")
|
||||||
|
return False
|
||||||
|
|
||||||
|
ignore_pr_source_branches = get_settings().get("CONFIG.IGNORE_PR_SOURCE_BRANCHES", [])
|
||||||
|
ignore_pr_target_branches = get_settings().get("CONFIG.IGNORE_PR_TARGET_BRANCHES", [])
|
||||||
|
if (ignore_pr_source_branches or ignore_pr_target_branches):
|
||||||
|
if any(re.search(regex, source_branch) for regex in ignore_pr_source_branches):
|
||||||
|
get_logger().info(
|
||||||
|
f"Ignoring PR with source branch '{source_branch}' due to config.ignore_pr_source_branches settings")
|
||||||
|
return False
|
||||||
|
if any(re.search(regex, target_branch) for regex in ignore_pr_target_branches):
|
||||||
|
get_logger().info(
|
||||||
|
f"Ignoring PR with target branch '{target_branch}' due to config.ignore_pr_target_branches settings")
|
||||||
|
return False
|
||||||
|
|
||||||
|
# Allow_only_specific_folders
|
||||||
|
allowed_folders = get_settings().config.get("allow_only_specific_folders", [])
|
||||||
|
if allowed_folders and pr_id and project_key and repo_slug:
|
||||||
|
from pr_agent.git_providers.bitbucket_server_provider import BitbucketServerProvider
|
||||||
|
bitbucket_server_url = get_settings().get("BITBUCKET_SERVER.URL", "")
|
||||||
|
pr_url = f"{bitbucket_server_url}/projects/{project_key}/repos/{repo_slug}/pull-requests/{pr_id}"
|
||||||
|
provider = BitbucketServerProvider(pr_url=pr_url)
|
||||||
|
changed_files = provider.get_files()
|
||||||
|
if changed_files:
|
||||||
|
# Check if ALL files are outside allowed folders
|
||||||
|
all_files_outside = True
|
||||||
|
for file_path in changed_files:
|
||||||
|
if any(file_path.startswith(folder) for folder in allowed_folders):
|
||||||
|
all_files_outside = False
|
||||||
|
break
|
||||||
|
|
||||||
|
if all_files_outside:
|
||||||
|
get_logger().info(f"Ignoring PR because all files {changed_files} are outside allowed folders {allowed_folders}")
|
||||||
|
return False
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().error(f"Failed 'should_process_pr_logic': {e}")
|
||||||
|
return True # On exception - we continue. Otherwise, we could just end up with filtering all PRs
|
||||||
|
return True
|
||||||
|
|
||||||
@router.post("/")
|
@router.post("/")
|
||||||
async def redirect_to_webhook():
|
async def redirect_to_webhook():
|
||||||
return RedirectResponse(url="/webhook")
|
return RedirectResponse(url="/webhook")
|
||||||
|
|
@ -71,13 +154,31 @@ async def handle_webhook(background_tasks: BackgroundTasks, request: Request):
|
||||||
|
|
||||||
commands_to_run = []
|
commands_to_run = []
|
||||||
|
|
||||||
if data["eventKey"] == "pr:opened":
|
if (data["eventKey"] == "pr:opened"
|
||||||
|
or (data["eventKey"] == "repo:refs_changed" and data.get("pullRequest", {}).get("id", -1) != -1)): # push event; -1 for push unassigned to a PR: #Check auto commands for creation/updating
|
||||||
apply_repo_settings(pr_url)
|
apply_repo_settings(pr_url)
|
||||||
|
if not should_process_pr_logic(data):
|
||||||
|
get_logger().info(f"PR ignored due to config settings", **log_context)
|
||||||
|
return JSONResponse(
|
||||||
|
status_code=status.HTTP_200_OK, content=jsonable_encoder({"message": "PR ignored by config"})
|
||||||
|
)
|
||||||
if get_settings().config.disable_auto_feedback: # auto commands for PR, and auto feedback is disabled
|
if get_settings().config.disable_auto_feedback: # auto commands for PR, and auto feedback is disabled
|
||||||
get_logger().info(f"Auto feedback is disabled, skipping auto commands for PR {pr_url}", **log_context)
|
get_logger().info(f"Auto feedback is disabled, skipping auto commands for PR {pr_url}", **log_context)
|
||||||
return
|
return JSONResponse(
|
||||||
|
status_code=status.HTTP_200_OK, content=jsonable_encoder({"message": "PR ignored due to auto feedback not enabled"})
|
||||||
|
)
|
||||||
get_settings().set("config.is_auto_command", True)
|
get_settings().set("config.is_auto_command", True)
|
||||||
commands_to_run.extend(_get_commands_list_from_settings('BITBUCKET_SERVER.PR_COMMANDS'))
|
if data["eventKey"] == "pr:opened":
|
||||||
|
commands_to_run.extend(_get_commands_list_from_settings('BITBUCKET_SERVER.PR_COMMANDS'))
|
||||||
|
else: #Has to be: data["eventKey"] == "pr:from_ref_updated"
|
||||||
|
if not get_settings().get("BITBUCKET_SERVER.HANDLE_PUSH_TRIGGER"):
|
||||||
|
get_logger().info(f"Push trigger is disabled, skipping push commands for PR {pr_url}", **log_context)
|
||||||
|
return JSONResponse(
|
||||||
|
status_code=status.HTTP_200_OK, content=jsonable_encoder({"message": "PR ignored due to push trigger not enabled"})
|
||||||
|
)
|
||||||
|
|
||||||
|
get_settings().set("config.is_new_pr", False)
|
||||||
|
commands_to_run.extend(_get_commands_list_from_settings('BITBUCKET_SERVER.PUSH_COMMANDS'))
|
||||||
elif data["eventKey"] == "pr:comment:added":
|
elif data["eventKey"] == "pr:comment:added":
|
||||||
commands_to_run.append(data["comment"]["text"])
|
commands_to_run.append(data["comment"]["text"])
|
||||||
else:
|
else:
|
||||||
|
|
|
||||||
|
|
@ -1,6 +1,6 @@
|
||||||
import asyncio
|
|
||||||
import copy
|
import copy
|
||||||
import os
|
import os
|
||||||
|
import re
|
||||||
from typing import Any, Dict
|
from typing import Any, Dict
|
||||||
|
|
||||||
from fastapi import APIRouter, FastAPI, HTTPException, Request, Response
|
from fastapi import APIRouter, FastAPI, HTTPException, Request, Response
|
||||||
|
|
@ -10,7 +10,9 @@ from starlette_context import context
|
||||||
from starlette_context.middleware import RawContextMiddleware
|
from starlette_context.middleware import RawContextMiddleware
|
||||||
|
|
||||||
from pr_agent.agent.pr_agent import PRAgent
|
from pr_agent.agent.pr_agent import PRAgent
|
||||||
|
from pr_agent.algo.utils import update_settings_from_args
|
||||||
from pr_agent.config_loader import get_settings, global_settings
|
from pr_agent.config_loader import get_settings, global_settings
|
||||||
|
from pr_agent.git_providers.utils import apply_repo_settings
|
||||||
from pr_agent.log import LoggingFormat, get_logger, setup_logger
|
from pr_agent.log import LoggingFormat, get_logger, setup_logger
|
||||||
from pr_agent.servers.utils import verify_signature
|
from pr_agent.servers.utils import verify_signature
|
||||||
|
|
||||||
|
|
@ -50,7 +52,7 @@ async def get_body(request: Request):
|
||||||
if not signature_header:
|
if not signature_header:
|
||||||
get_logger().error("Missing signature header")
|
get_logger().error("Missing signature header")
|
||||||
raise HTTPException(status_code=400, detail="Missing signature header")
|
raise HTTPException(status_code=400, detail="Missing signature header")
|
||||||
|
|
||||||
try:
|
try:
|
||||||
verify_signature(body_bytes, webhook_secret, f"sha256={signature_header}")
|
verify_signature(body_bytes, webhook_secret, f"sha256={signature_header}")
|
||||||
except Exception as ex:
|
except Exception as ex:
|
||||||
|
|
@ -70,6 +72,9 @@ async def handle_request(body: Dict[str, Any], event: str):
|
||||||
|
|
||||||
# Handle different event types
|
# Handle different event types
|
||||||
if event == "pull_request":
|
if event == "pull_request":
|
||||||
|
if not should_process_pr_logic(body):
|
||||||
|
get_logger().debug(f"Request ignored: PR logic filtering")
|
||||||
|
return {}
|
||||||
if action in ["opened", "reopened", "synchronized"]:
|
if action in ["opened", "reopened", "synchronized"]:
|
||||||
await handle_pr_event(body, event, action, agent)
|
await handle_pr_event(body, event, action, agent)
|
||||||
elif event == "issue_comment":
|
elif event == "issue_comment":
|
||||||
|
|
@ -90,12 +95,21 @@ async def handle_pr_event(body: Dict[str, Any], event: str, action: str, agent:
|
||||||
|
|
||||||
# Handle PR based on action
|
# Handle PR based on action
|
||||||
if action in ["opened", "reopened"]:
|
if action in ["opened", "reopened"]:
|
||||||
commands = get_settings().get("gitea.pr_commands", [])
|
# commands = get_settings().get("gitea.pr_commands", [])
|
||||||
for command in commands:
|
await _perform_commands_gitea("pr_commands", agent, body, api_url)
|
||||||
await agent.handle_request(api_url, command)
|
# for command in commands:
|
||||||
|
# await agent.handle_request(api_url, command)
|
||||||
elif action == "synchronized":
|
elif action == "synchronized":
|
||||||
# Handle push to PR
|
# Handle push to PR
|
||||||
await agent.handle_request(api_url, "/review --incremental")
|
commands_on_push = get_settings().get(f"gitea.push_commands", {})
|
||||||
|
handle_push_trigger = get_settings().get(f"gitea.handle_push_trigger", False)
|
||||||
|
if not commands_on_push or not handle_push_trigger:
|
||||||
|
get_logger().info("Push event, but no push commands found or push trigger is disabled")
|
||||||
|
return
|
||||||
|
get_logger().debug(f'A push event has been received: {api_url}')
|
||||||
|
await _perform_commands_gitea("push_commands", agent, body, api_url)
|
||||||
|
# for command in commands_on_push:
|
||||||
|
# await agent.handle_request(api_url, command)
|
||||||
|
|
||||||
async def handle_comment_event(body: Dict[str, Any], event: str, action: str, agent: PRAgent):
|
async def handle_comment_event(body: Dict[str, Any], event: str, action: str, agent: PRAgent):
|
||||||
"""Handle comment events"""
|
"""Handle comment events"""
|
||||||
|
|
@ -113,6 +127,85 @@ async def handle_comment_event(body: Dict[str, Any], event: str, action: str, ag
|
||||||
|
|
||||||
await agent.handle_request(pr_url, comment_body)
|
await agent.handle_request(pr_url, comment_body)
|
||||||
|
|
||||||
|
async def _perform_commands_gitea(commands_conf: str, agent: PRAgent, body: dict, api_url: str):
|
||||||
|
apply_repo_settings(api_url)
|
||||||
|
if commands_conf == "pr_commands" and get_settings().config.disable_auto_feedback: # auto commands for PR, and auto feedback is disabled
|
||||||
|
get_logger().info(f"Auto feedback is disabled, skipping auto commands for PR {api_url=}")
|
||||||
|
return
|
||||||
|
if not should_process_pr_logic(body): # Here we already updated the configuration with the repo settings
|
||||||
|
return {}
|
||||||
|
commands = get_settings().get(f"gitea.{commands_conf}")
|
||||||
|
if not commands:
|
||||||
|
get_logger().info(f"New PR, but no auto commands configured")
|
||||||
|
return
|
||||||
|
get_settings().set("config.is_auto_command", True)
|
||||||
|
for command in commands:
|
||||||
|
split_command = command.split(" ")
|
||||||
|
command = split_command[0]
|
||||||
|
args = split_command[1:]
|
||||||
|
other_args = update_settings_from_args(args)
|
||||||
|
new_command = ' '.join([command] + other_args)
|
||||||
|
get_logger().info(f"{commands_conf}. Performing auto command '{new_command}', for {api_url=}")
|
||||||
|
await agent.handle_request(api_url, new_command)
|
||||||
|
|
||||||
|
def should_process_pr_logic(body) -> bool:
|
||||||
|
try:
|
||||||
|
pull_request = body.get("pull_request", {})
|
||||||
|
title = pull_request.get("title", "")
|
||||||
|
pr_labels = pull_request.get("labels", [])
|
||||||
|
source_branch = pull_request.get("head", {}).get("ref", "")
|
||||||
|
target_branch = pull_request.get("base", {}).get("ref", "")
|
||||||
|
sender = body.get("sender", {}).get("login")
|
||||||
|
repo_full_name = body.get("repository", {}).get("full_name", "")
|
||||||
|
|
||||||
|
# logic to ignore PRs from specific repositories
|
||||||
|
ignore_repos = get_settings().get("CONFIG.IGNORE_REPOSITORIES", [])
|
||||||
|
if ignore_repos and repo_full_name:
|
||||||
|
if any(re.search(regex, repo_full_name) for regex in ignore_repos):
|
||||||
|
get_logger().info(f"Ignoring PR from repository '{repo_full_name}' due to 'config.ignore_repositories' setting")
|
||||||
|
return False
|
||||||
|
|
||||||
|
# logic to ignore PRs from specific users
|
||||||
|
ignore_pr_users = get_settings().get("CONFIG.IGNORE_PR_AUTHORS", [])
|
||||||
|
if ignore_pr_users and sender:
|
||||||
|
if any(re.search(regex, sender) for regex in ignore_pr_users):
|
||||||
|
get_logger().info(f"Ignoring PR from user '{sender}' due to 'config.ignore_pr_authors' setting")
|
||||||
|
return False
|
||||||
|
|
||||||
|
# logic to ignore PRs with specific titles
|
||||||
|
if title:
|
||||||
|
ignore_pr_title_re = get_settings().get("CONFIG.IGNORE_PR_TITLE", [])
|
||||||
|
if not isinstance(ignore_pr_title_re, list):
|
||||||
|
ignore_pr_title_re = [ignore_pr_title_re]
|
||||||
|
if ignore_pr_title_re and any(re.search(regex, title) for regex in ignore_pr_title_re):
|
||||||
|
get_logger().info(f"Ignoring PR with title '{title}' due to config.ignore_pr_title setting")
|
||||||
|
return False
|
||||||
|
|
||||||
|
# logic to ignore PRs with specific labels or source branches or target branches.
|
||||||
|
ignore_pr_labels = get_settings().get("CONFIG.IGNORE_PR_LABELS", [])
|
||||||
|
if pr_labels and ignore_pr_labels:
|
||||||
|
labels = [label['name'] for label in pr_labels]
|
||||||
|
if any(label in ignore_pr_labels for label in labels):
|
||||||
|
labels_str = ", ".join(labels)
|
||||||
|
get_logger().info(f"Ignoring PR with labels '{labels_str}' due to config.ignore_pr_labels settings")
|
||||||
|
return False
|
||||||
|
|
||||||
|
# logic to ignore PRs with specific source or target branches
|
||||||
|
ignore_pr_source_branches = get_settings().get("CONFIG.IGNORE_PR_SOURCE_BRANCHES", [])
|
||||||
|
ignore_pr_target_branches = get_settings().get("CONFIG.IGNORE_PR_TARGET_BRANCHES", [])
|
||||||
|
if pull_request and (ignore_pr_source_branches or ignore_pr_target_branches):
|
||||||
|
if any(re.search(regex, source_branch) for regex in ignore_pr_source_branches):
|
||||||
|
get_logger().info(
|
||||||
|
f"Ignoring PR with source branch '{source_branch}' due to config.ignore_pr_source_branches settings")
|
||||||
|
return False
|
||||||
|
if any(re.search(regex, target_branch) for regex in ignore_pr_target_branches):
|
||||||
|
get_logger().info(
|
||||||
|
f"Ignoring PR with target branch '{target_branch}' due to config.ignore_pr_target_branches settings")
|
||||||
|
return False
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().error(f"Failed 'should_process_pr_logic': {e}")
|
||||||
|
return True
|
||||||
|
|
||||||
# FastAPI app setup
|
# FastAPI app setup
|
||||||
middleware = [Middleware(RawContextMiddleware)]
|
middleware = [Middleware(RawContextMiddleware)]
|
||||||
app = FastAPI(middleware=middleware)
|
app = FastAPI(middleware=middleware)
|
||||||
|
|
|
||||||
|
|
@ -270,7 +270,7 @@ def should_process_pr_logic(body) -> bool:
|
||||||
# logic to ignore PRs from specific users
|
# logic to ignore PRs from specific users
|
||||||
ignore_pr_users = get_settings().get("CONFIG.IGNORE_PR_AUTHORS", [])
|
ignore_pr_users = get_settings().get("CONFIG.IGNORE_PR_AUTHORS", [])
|
||||||
if ignore_pr_users and sender:
|
if ignore_pr_users and sender:
|
||||||
if sender in ignore_pr_users:
|
if any(re.search(regex, sender) for regex in ignore_pr_users):
|
||||||
get_logger().info(f"Ignoring PR from user '{sender}' due to 'config.ignore_pr_authors' setting")
|
get_logger().info(f"Ignoring PR from user '{sender}' due to 'config.ignore_pr_authors' setting")
|
||||||
return False
|
return False
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -18,6 +18,7 @@ from pr_agent.config_loader import get_settings, global_settings
|
||||||
from pr_agent.git_providers.utils import apply_repo_settings
|
from pr_agent.git_providers.utils import apply_repo_settings
|
||||||
from pr_agent.log import LoggingFormat, get_logger, setup_logger
|
from pr_agent.log import LoggingFormat, get_logger, setup_logger
|
||||||
from pr_agent.secret_providers import get_secret_provider
|
from pr_agent.secret_providers import get_secret_provider
|
||||||
|
from pr_agent.git_providers import get_git_provider_with_context
|
||||||
|
|
||||||
setup_logger(fmt=LoggingFormat.JSON, level=get_settings().get("CONFIG.LOG_LEVEL", "DEBUG"))
|
setup_logger(fmt=LoggingFormat.JSON, level=get_settings().get("CONFIG.LOG_LEVEL", "DEBUG"))
|
||||||
router = APIRouter()
|
router = APIRouter()
|
||||||
|
|
@ -25,15 +26,14 @@ router = APIRouter()
|
||||||
secret_provider = get_secret_provider() if get_settings().get("CONFIG.SECRET_PROVIDER") else None
|
secret_provider = get_secret_provider() if get_settings().get("CONFIG.SECRET_PROVIDER") else None
|
||||||
|
|
||||||
|
|
||||||
async def handle_request(api_url: str, body: str, log_context: dict, sender_id: str):
|
async def handle_request(api_url: str, body: str, log_context: dict, sender_id: str, notify=None):
|
||||||
log_context["action"] = body
|
log_context["action"] = body
|
||||||
log_context["event"] = "pull_request" if body == "/review" else "comment"
|
log_context["event"] = "pull_request" if body == "/review" else "comment"
|
||||||
log_context["api_url"] = api_url
|
log_context["api_url"] = api_url
|
||||||
log_context["app_name"] = get_settings().get("CONFIG.APP_NAME", "Unknown")
|
log_context["app_name"] = get_settings().get("CONFIG.APP_NAME", "Unknown")
|
||||||
|
|
||||||
with get_logger().contextualize(**log_context):
|
with get_logger().contextualize(**log_context):
|
||||||
await PRAgent().handle_request(api_url, body)
|
await PRAgent().handle_request(api_url, body, notify)
|
||||||
|
|
||||||
|
|
||||||
async def _perform_commands_gitlab(commands_conf: str, agent: PRAgent, api_url: str,
|
async def _perform_commands_gitlab(commands_conf: str, agent: PRAgent, api_url: str,
|
||||||
log_context: dict, data: dict):
|
log_context: dict, data: dict):
|
||||||
|
|
@ -125,7 +125,7 @@ def should_process_pr_logic(data) -> bool:
|
||||||
# logic to ignore PRs from specific users
|
# logic to ignore PRs from specific users
|
||||||
ignore_pr_users = get_settings().get("CONFIG.IGNORE_PR_AUTHORS", [])
|
ignore_pr_users = get_settings().get("CONFIG.IGNORE_PR_AUTHORS", [])
|
||||||
if ignore_pr_users and sender:
|
if ignore_pr_users and sender:
|
||||||
if sender in ignore_pr_users:
|
if any(re.search(regex, sender) for regex in ignore_pr_users):
|
||||||
get_logger().info(f"Ignoring PR from user '{sender}' due to 'config.ignore_pr_authors' settings")
|
get_logger().info(f"Ignoring PR from user '{sender}' due to 'config.ignore_pr_authors' settings")
|
||||||
return False
|
return False
|
||||||
|
|
||||||
|
|
@ -234,6 +234,9 @@ async def gitlab_webhook(background_tasks: BackgroundTasks, request: Request):
|
||||||
get_logger().info(f"Skipping draft MR: {url}")
|
get_logger().info(f"Skipping draft MR: {url}")
|
||||||
return JSONResponse(status_code=status.HTTP_200_OK, content=jsonable_encoder({"message": "success"}))
|
return JSONResponse(status_code=status.HTTP_200_OK, content=jsonable_encoder({"message": "success"}))
|
||||||
|
|
||||||
|
# Apply repo settings before checking push commands or handle_push_trigger
|
||||||
|
apply_repo_settings(url)
|
||||||
|
|
||||||
commands_on_push = get_settings().get(f"gitlab.push_commands", {})
|
commands_on_push = get_settings().get(f"gitlab.push_commands", {})
|
||||||
handle_push_trigger = get_settings().get(f"gitlab.handle_push_trigger", False)
|
handle_push_trigger = get_settings().get(f"gitlab.handle_push_trigger", False)
|
||||||
if not commands_on_push or not handle_push_trigger:
|
if not commands_on_push or not handle_push_trigger:
|
||||||
|
|
@ -256,13 +259,15 @@ async def gitlab_webhook(background_tasks: BackgroundTasks, request: Request):
|
||||||
if 'merge_request' in data:
|
if 'merge_request' in data:
|
||||||
mr = data['merge_request']
|
mr = data['merge_request']
|
||||||
url = mr.get('url')
|
url = mr.get('url')
|
||||||
|
comment_id = data.get('object_attributes', {}).get('id')
|
||||||
|
provider = get_git_provider_with_context(pr_url=url)
|
||||||
|
|
||||||
get_logger().info(f"A comment has been added to a merge request: {url}")
|
get_logger().info(f"A comment has been added to a merge request: {url}")
|
||||||
body = data.get('object_attributes', {}).get('note')
|
body = data.get('object_attributes', {}).get('note')
|
||||||
if data.get('object_attributes', {}).get('type') == 'DiffNote' and '/ask' in body: # /ask_line
|
if data.get('object_attributes', {}).get('type') == 'DiffNote' and '/ask' in body: # /ask_line
|
||||||
body = handle_ask_line(body, data)
|
body = handle_ask_line(body, data)
|
||||||
|
|
||||||
await handle_request(url, body, log_context, sender_id)
|
await handle_request(url, body, log_context, sender_id, notify=lambda: provider.add_eyes_reaction(comment_id))
|
||||||
|
|
||||||
background_tasks.add_task(inner, request_json)
|
background_tasks.add_task(inner, request_json)
|
||||||
end_time = datetime.now()
|
end_time = datetime.now()
|
||||||
|
|
@ -283,7 +288,7 @@ def handle_ask_line(body, data):
|
||||||
path = data['object_attributes']['position']['new_path']
|
path = data['object_attributes']['position']['new_path']
|
||||||
side = 'RIGHT' # if line_range_['start']['type'] == 'new' else 'LEFT'
|
side = 'RIGHT' # if line_range_['start']['type'] == 'new' else 'LEFT'
|
||||||
comment_id = data['object_attributes']["discussion_id"]
|
comment_id = data['object_attributes']["discussion_id"]
|
||||||
get_logger().info("Handling line comment")
|
get_logger().info("Handling line ")
|
||||||
body = f"/ask_line --line_start={start_line} --line_end={end_line} --side={side} --file_name={path} --comment_id={comment_id} {question}"
|
body = f"/ask_line --line_start={start_line} --line_end={end_line} --side={side} --file_name={path} --comment_id={comment_id} {question}"
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
get_logger().error(f"Failed to handle ask line comment: {e}")
|
get_logger().error(f"Failed to handle ask line comment: {e}")
|
||||||
|
|
|
||||||
|
|
@ -81,6 +81,7 @@ the tool will replace every marker of the form `pr_agent:marker_name` in the PR
|
||||||
- `type`: the PR type.
|
- `type`: the PR type.
|
||||||
- `summary`: the PR summary.
|
- `summary`: the PR summary.
|
||||||
- `walkthrough`: the PR walkthrough.
|
- `walkthrough`: the PR walkthrough.
|
||||||
|
- `diagram`: the PR sequence diagram (if enabled).
|
||||||
|
|
||||||
Note that when markers are enabled, if the original PR description does not contain any markers, the tool will not alter the description at all.
|
Note that when markers are enabled, if the original PR description does not contain any markers, the tool will not alter the description at all.
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -16,10 +16,20 @@ key = "" # Acquire through https://platform.openai.com
|
||||||
#deployment_id = "" # The deployment name you chose when you deployed the engine
|
#deployment_id = "" # The deployment name you chose when you deployed the engine
|
||||||
#fallback_deployments = [] # For each fallback model specified in configuration.toml in the [config] section, specify the appropriate deployment_id
|
#fallback_deployments = [] # For each fallback model specified in configuration.toml in the [config] section, specify the appropriate deployment_id
|
||||||
|
|
||||||
|
# OpenAI Flex Processing (optional, for cost savings)
|
||||||
|
# [litellm]
|
||||||
|
# extra_body='{"processing_mode": "flex"}'
|
||||||
|
# model_id = "" # Optional: Custom inference profile ID for Amazon Bedrock
|
||||||
|
|
||||||
[pinecone]
|
[pinecone]
|
||||||
api_key = "..."
|
api_key = "..."
|
||||||
environment = "gcp-starter"
|
environment = "gcp-starter"
|
||||||
|
|
||||||
|
[qdrant]
|
||||||
|
# For Qdrant Cloud or self-hosted Qdrant
|
||||||
|
url = "" # e.g., https://xxxxxxxx-xxxxxxxx.eu-central-1-0.aws.cloud.qdrant.io
|
||||||
|
api_key = ""
|
||||||
|
|
||||||
[anthropic]
|
[anthropic]
|
||||||
key = "" # Optional, uncomment if you want to use Anthropic. Acquire through https://www.anthropic.com/
|
key = "" # Optional, uncomment if you want to use Anthropic. Acquire through https://www.anthropic.com/
|
||||||
|
|
||||||
|
|
@ -88,7 +98,7 @@ webhook_secret = ""
|
||||||
|
|
||||||
# For Bitbucket app
|
# For Bitbucket app
|
||||||
app_key = ""
|
app_key = ""
|
||||||
base_url = ""
|
url = ""
|
||||||
|
|
||||||
[azure_devops]
|
[azure_devops]
|
||||||
# For Azure devops personal access token
|
# For Azure devops personal access token
|
||||||
|
|
|
||||||
|
|
@ -63,10 +63,15 @@ Specific guidelines for generating code suggestions:
|
||||||
- Don't suggest to add docstring, type hints, or comments, to remove unused imports, or to use more specific exception types.
|
- Don't suggest to add docstring, type hints, or comments, to remove unused imports, or to use more specific exception types.
|
||||||
{%- else %}
|
{%- else %}
|
||||||
- Only give suggestions that address critical problems and bugs in the PR code. If no relevant suggestions are applicable, return an empty list.
|
- Only give suggestions that address critical problems and bugs in the PR code. If no relevant suggestions are applicable, return an empty list.
|
||||||
- Do not suggest to change packages version, add missing import statement, or declare undefined variable.
|
- DO NOT suggest the following:
|
||||||
|
- change packages version
|
||||||
|
- add missing import statement
|
||||||
|
- declare undefined variable, or remove unused variable
|
||||||
|
- use more specific exception types
|
||||||
|
- repeat changes already done in the PR code
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
|
- Be aware that your input consists only of partial code segments (PR diff code), not the complete codebase. Therefore, avoid making suggestions that might duplicate existing functionality, and refrain from questioning code elements (such as variable declarations or import statements) that may be defined elsewhere in the codebase.
|
||||||
- When mentioning code elements (variables, names, or files) in your response, surround them with backticks (`). For example: "verify that `user_id` is..."
|
- When mentioning code elements (variables, names, or files) in your response, surround them with backticks (`). For example: "verify that `user_id` is..."
|
||||||
- Note that you only see changed code segments (diff hunks in a PR), not the entire codebase. Avoid suggestions that might duplicate existing functionality or questioning code elements (like variables declarations or import statements) that may be defined elsewhere in the codebase.
|
|
||||||
|
|
||||||
{%- if extra_instructions %}
|
{%- if extra_instructions %}
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -5,7 +5,7 @@ In addition to evaluating the suggestion correctness and importance, another sub
|
||||||
|
|
||||||
Examine each suggestion meticulously, assessing its quality, relevance, and accuracy within the context of PR. Keep in mind that the suggestions may vary in their correctness, accuracy and impact.
|
Examine each suggestion meticulously, assessing its quality, relevance, and accuracy within the context of PR. Keep in mind that the suggestions may vary in their correctness, accuracy and impact.
|
||||||
Consider the following components of each suggestion:
|
Consider the following components of each suggestion:
|
||||||
1. 'one_sentence_summary' - A one-liner summary summary of the suggestion's purpose
|
1. 'one_sentence_summary' - A one-liner summary of the suggestion's purpose
|
||||||
2. 'suggestion_content' - The suggestion content, explaining the proposed modification
|
2. 'suggestion_content' - The suggestion content, explaining the proposed modification
|
||||||
3. 'existing_code' - a code snippet from a __new hunk__ section in the PR code diff that the suggestion addresses
|
3. 'existing_code' - a code snippet from a __new hunk__ section in the PR code diff that the suggestion addresses
|
||||||
4. 'improved_code' - a code snippet demonstrating how the 'existing_code' should be after the suggestion is applied
|
4. 'improved_code' - a code snippet demonstrating how the 'existing_code' should be after the suggestion is applied
|
||||||
|
|
|
||||||
|
|
@ -6,9 +6,9 @@
|
||||||
|
|
||||||
[config]
|
[config]
|
||||||
# models
|
# models
|
||||||
model="o4-mini"
|
model="gpt-5-2025-08-07"
|
||||||
fallback_models=["gpt-4.1"]
|
fallback_models=["o4-mini"]
|
||||||
#model_reasoning="o4-mini" # dedictated reasoning model for self-reflection
|
#model_reasoning="o4-mini" # dedicated reasoning model for self-reflection
|
||||||
#model_weak="gpt-4o" # optional, a weaker model to use for some easier tasks
|
#model_weak="gpt-4o" # optional, a weaker model to use for some easier tasks
|
||||||
# CLI
|
# CLI
|
||||||
git_provider="github"
|
git_provider="github"
|
||||||
|
|
@ -49,6 +49,9 @@ duplicate_prompt_examples = false
|
||||||
# seed
|
# seed
|
||||||
seed=-1 # set positive value to fix the seed (and ensure temperature=0)
|
seed=-1 # set positive value to fix the seed (and ensure temperature=0)
|
||||||
temperature=0.2
|
temperature=0.2
|
||||||
|
# bring repo metadata 💎
|
||||||
|
add_repo_metadata=false # if true, will try to add metadata from files like 'AGENTS.MD', 'CLAUDE.MD', 'QODO.MD'
|
||||||
|
add_repo_metadata_file_list =["AGENTS.MD", "CLAUDE.MD", "QODO.MD"]
|
||||||
# ignore logic
|
# ignore logic
|
||||||
ignore_pr_title = ["^\\[Auto\\]", "^Auto"] # a list of regular expressions to match against the PR title to ignore the PR agent
|
ignore_pr_title = ["^\\[Auto\\]", "^Auto"] # a list of regular expressions to match against the PR title to ignore the PR agent
|
||||||
ignore_pr_target_branches = [] # a list of regular expressions of target branches to ignore from PR agent when an PR is created
|
ignore_pr_target_branches = [] # a list of regular expressions of target branches to ignore from PR agent when an PR is created
|
||||||
|
|
@ -56,6 +59,7 @@ ignore_pr_source_branches = [] # a list of regular expressions of source branche
|
||||||
ignore_pr_labels = [] # labels to ignore from PR agent when an PR is created
|
ignore_pr_labels = [] # labels to ignore from PR agent when an PR is created
|
||||||
ignore_pr_authors = [] # authors to ignore from PR agent when an PR is created
|
ignore_pr_authors = [] # authors to ignore from PR agent when an PR is created
|
||||||
ignore_repositories = [] # a list of regular expressions of repository full names (e.g. "org/repo") to ignore from PR agent processing
|
ignore_repositories = [] # a list of regular expressions of repository full names (e.g. "org/repo") to ignore from PR agent processing
|
||||||
|
ignore_language_framework = [] # a list of code-generation languages or frameworks (e.g. 'protobuf', 'go_gen') whose auto-generated source files will be excluded from analysis
|
||||||
#
|
#
|
||||||
is_auto_command = false # will be auto-set to true if the command is triggered by an automation
|
is_auto_command = false # will be auto-set to true if the command is triggered by an automation
|
||||||
enable_ai_metadata = false # will enable adding ai metadata
|
enable_ai_metadata = false # will enable adding ai metadata
|
||||||
|
|
@ -78,6 +82,7 @@ require_tests_review=true
|
||||||
require_estimate_effort_to_review=true
|
require_estimate_effort_to_review=true
|
||||||
require_can_be_split_review=false
|
require_can_be_split_review=false
|
||||||
require_security_review=true
|
require_security_review=true
|
||||||
|
require_estimate_contribution_time_cost=false
|
||||||
require_todo_scan=false
|
require_todo_scan=false
|
||||||
require_ticket_analysis_review=true
|
require_ticket_analysis_review=true
|
||||||
# general options
|
# general options
|
||||||
|
|
@ -105,8 +110,8 @@ extra_instructions = ""
|
||||||
enable_pr_type=true
|
enable_pr_type=true
|
||||||
final_update_message = true
|
final_update_message = true
|
||||||
enable_help_text=false
|
enable_help_text=false
|
||||||
enable_help_comment=true
|
enable_help_comment=false
|
||||||
enable_pr_diagram=false # adds a section with a diagram of the PR changes
|
enable_pr_diagram=true # adds a section with a diagram of the PR changes
|
||||||
# describe as comment
|
# describe as comment
|
||||||
publish_description_as_comment=false
|
publish_description_as_comment=false
|
||||||
publish_description_as_comment_persistent=true
|
publish_description_as_comment_persistent=true
|
||||||
|
|
@ -130,8 +135,6 @@ use_conversation_history=true
|
||||||
|
|
||||||
|
|
||||||
[pr_code_suggestions] # /improve #
|
[pr_code_suggestions] # /improve #
|
||||||
max_context_tokens=24000
|
|
||||||
#
|
|
||||||
commitable_code_suggestions = false
|
commitable_code_suggestions = false
|
||||||
dual_publishing_score_threshold=-1 # -1 to disable, [0-10] to set the threshold (>=) for publishing a code suggestion both in a table and as commitable
|
dual_publishing_score_threshold=-1 # -1 to disable, [0-10] to set the threshold (>=) for publishing a code suggestion both in a table and as commitable
|
||||||
focus_only_on_problems=true
|
focus_only_on_problems=true
|
||||||
|
|
@ -151,7 +154,8 @@ new_score_mechanism_th_high=9
|
||||||
new_score_mechanism_th_medium=7
|
new_score_mechanism_th_medium=7
|
||||||
# params for '/improve --extended' mode
|
# params for '/improve --extended' mode
|
||||||
auto_extended_mode=true
|
auto_extended_mode=true
|
||||||
num_code_suggestions_per_chunk=4
|
num_code_suggestions_per_chunk=3
|
||||||
|
num_best_practice_suggestions=1 # 💎
|
||||||
max_number_of_calls = 3
|
max_number_of_calls = 3
|
||||||
parallel_calls = true
|
parallel_calls = true
|
||||||
|
|
||||||
|
|
@ -272,6 +276,7 @@ push_commands = [
|
||||||
|
|
||||||
[gitlab]
|
[gitlab]
|
||||||
url = "https://gitlab.com"
|
url = "https://gitlab.com"
|
||||||
|
expand_submodule_diffs = false
|
||||||
pr_commands = [
|
pr_commands = [
|
||||||
"/describe --pr_description.final_update_message=false",
|
"/describe --pr_description.final_update_message=false",
|
||||||
"/review",
|
"/review",
|
||||||
|
|
@ -282,8 +287,10 @@ push_commands = [
|
||||||
"/describe",
|
"/describe",
|
||||||
"/review",
|
"/review",
|
||||||
]
|
]
|
||||||
|
# Configure SSL validation for GitLab. Can be either set to the path of a custom CA or disabled entirely.
|
||||||
|
# ssl_verify = true
|
||||||
|
|
||||||
[gitea_app]
|
[gitea]
|
||||||
url = "https://gitea.com"
|
url = "https://gitea.com"
|
||||||
handle_push_trigger = false
|
handle_push_trigger = false
|
||||||
pr_commands = [
|
pr_commands = [
|
||||||
|
|
@ -291,6 +298,10 @@ pr_commands = [
|
||||||
"/review",
|
"/review",
|
||||||
"/improve",
|
"/improve",
|
||||||
]
|
]
|
||||||
|
push_commands = [
|
||||||
|
"/describe",
|
||||||
|
"/review",
|
||||||
|
]
|
||||||
|
|
||||||
[bitbucket_app]
|
[bitbucket_app]
|
||||||
pr_commands = [
|
pr_commands = [
|
||||||
|
|
@ -332,12 +343,13 @@ enable_callbacks = false
|
||||||
success_callback = []
|
success_callback = []
|
||||||
failure_callback = []
|
failure_callback = []
|
||||||
service_callback = []
|
service_callback = []
|
||||||
|
# model_id = "" # Optional: Custom inference profile ID for Amazon Bedrock
|
||||||
|
|
||||||
[pr_similar_issue]
|
[pr_similar_issue]
|
||||||
skip_comments = false
|
skip_comments = false
|
||||||
force_update_dataset = false
|
force_update_dataset = false
|
||||||
max_issues_to_scan = 500
|
max_issues_to_scan = 500
|
||||||
vectordb = "pinecone"
|
vectordb = "pinecone" # options: "pinecone", "lancedb", "qdrant"
|
||||||
|
|
||||||
[pr_find_similar_component]
|
[pr_find_similar_component]
|
||||||
class_name = ""
|
class_name = ""
|
||||||
|
|
@ -355,6 +367,11 @@ number_of_results = 5
|
||||||
[lancedb]
|
[lancedb]
|
||||||
uri = "./lancedb"
|
uri = "./lancedb"
|
||||||
|
|
||||||
|
[qdrant]
|
||||||
|
# fill and place credentials in .secrets.toml
|
||||||
|
# url = "https://YOUR-QDRANT-URL"
|
||||||
|
# api_key = "..."
|
||||||
|
|
||||||
[best_practices]
|
[best_practices]
|
||||||
content = ""
|
content = ""
|
||||||
organization_name = ""
|
organization_name = ""
|
||||||
|
|
@ -368,6 +385,8 @@ extra_instructions = "" # public - extra instructions to the auto best practices
|
||||||
content = ""
|
content = ""
|
||||||
max_patterns = 5 # max number of patterns to be detected
|
max_patterns = 5 # max number of patterns to be detected
|
||||||
|
|
||||||
|
[azure_devops]
|
||||||
|
default_comment_status = "closed"
|
||||||
|
|
||||||
[azure_devops_server]
|
[azure_devops_server]
|
||||||
pr_commands = [
|
pr_commands = [
|
||||||
|
|
|
||||||
42
pr_agent/settings/generated_code_ignore.toml
Normal file
42
pr_agent/settings/generated_code_ignore.toml
Normal file
|
|
@ -0,0 +1,42 @@
|
||||||
|
[generated_code]
|
||||||
|
|
||||||
|
# Protocol Buffers
|
||||||
|
protobuf = [
|
||||||
|
"**/*.pb.go",
|
||||||
|
"**/*.pb.cc",
|
||||||
|
"**/*_pb2.py",
|
||||||
|
"**/*.pb.swift",
|
||||||
|
"**/*.pb.rb",
|
||||||
|
"**/*.pb.php",
|
||||||
|
"**/*.pb.h"
|
||||||
|
]
|
||||||
|
|
||||||
|
# OpenAPI / Swagger stubs
|
||||||
|
openapi = [
|
||||||
|
"**/__generated__/**",
|
||||||
|
"**/openapi_client/**",
|
||||||
|
"**/openapi_server/**"
|
||||||
|
]
|
||||||
|
swagger = [
|
||||||
|
"**/swagger.json",
|
||||||
|
"**/swagger.yaml"
|
||||||
|
]
|
||||||
|
|
||||||
|
# GraphQL codegen
|
||||||
|
graphql = [
|
||||||
|
"**/*.graphql.ts",
|
||||||
|
"**/*.generated.ts",
|
||||||
|
"**/*.graphql.js"
|
||||||
|
]
|
||||||
|
|
||||||
|
# RPC / gRPC Generators
|
||||||
|
grpc_python = ["**/*_grpc.py"]
|
||||||
|
grpc_java = ["**/*Grpc.java"]
|
||||||
|
grpc_csharp = ["**/*Grpc.cs"]
|
||||||
|
grpc_typescript = ["**/*_grpc.ts", "**/*_grpc.js"]
|
||||||
|
|
||||||
|
# Go code generators
|
||||||
|
go_gen = [
|
||||||
|
"**/*_gen.go",
|
||||||
|
"**/*generated.go"
|
||||||
|
]
|
||||||
|
|
@ -45,11 +45,11 @@ class FileDescription(BaseModel):
|
||||||
|
|
||||||
class PRDescription(BaseModel):
|
class PRDescription(BaseModel):
|
||||||
type: List[PRType] = Field(description="one or more types that describe the PR content. Return the label member value (e.g. 'Bug fix', not 'bug_fix')")
|
type: List[PRType] = Field(description="one or more types that describe the PR content. Return the label member value (e.g. 'Bug fix', not 'bug_fix')")
|
||||||
description: str = Field(description="summarize the PR changes in up to four bullet points, each up to 8 words. For large PRs, add sub-bullets if needed. Order bullets by importance, with each bullet highlighting a key change group.")
|
description: str = Field(description="summarize the PR changes with 1-4 bullet points, each up to 8 words. For large PRs, add sub-bullets for each bullet if needed. Order bullets by importance, with each bullet highlighting a key change group.")
|
||||||
title: str = Field(description="a concise and descriptive title that captures the PR's main theme")
|
title: str = Field(description="a concise and descriptive title that captures the PR's main theme")
|
||||||
{%- if enable_pr_diagram %}
|
{%- if enable_pr_diagram %}
|
||||||
changes_diagram: str = Field(description="a horizontal diagram that represents the main PR changes, in the format of a valid mermaid LR flowchart. The diagram should be concise and easy to read. Leave empty if no diagram is relevant. To create robust Mermaid diagrams, follow this two-step process: (1) Declare the nodes: nodeID["node description"]. (2) Then define the links: nodeID1 -- "link text" --> nodeID2 ")
|
changes_diagram: str = Field(description='a horizontal diagram that represents the main PR changes, in the format of a valid mermaid LR flowchart. The diagram should be concise and easy to read. Leave empty if no diagram is relevant. To create robust Mermaid diagrams, follow this two-step process: (1) Declare the nodes: nodeID["node description"]. (2) Then define the links: nodeID1 -- "link text" --> nodeID2. Node description must always be surrounded with double quotation marks')
|
||||||
{%- endif %}
|
'{%- endif %}
|
||||||
{%- if enable_semantic_files_types %}
|
{%- if enable_semantic_files_types %}
|
||||||
pr_files: List[FileDescription] = Field(max_items=20, description="a list of all the files that were changed in the PR, and summary of their changes. Each file must be analyzed regardless of change size.")
|
pr_files: List[FileDescription] = Field(max_items=20, description="a list of all the files that were changed in the PR, and summary of their changes. Each file must be analyzed regardless of change size.")
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
|
|
@ -63,15 +63,16 @@ type:
|
||||||
- ...
|
- ...
|
||||||
- ...
|
- ...
|
||||||
description: |
|
description: |
|
||||||
...
|
- ...
|
||||||
|
- ...
|
||||||
title: |
|
title: |
|
||||||
...
|
...
|
||||||
{%- if enable_pr_diagram %}
|
{%- if enable_pr_diagram %}
|
||||||
changes_diagram: |
|
changes_diagram: |
|
||||||
```mermaid
|
```mermaid
|
||||||
flowchart LR
|
flowchart LR
|
||||||
...
|
...
|
||||||
```
|
```
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
{%- if enable_semantic_files_types %}
|
{%- if enable_semantic_files_types %}
|
||||||
pr_files:
|
pr_files:
|
||||||
|
|
@ -151,15 +152,16 @@ type:
|
||||||
- Refactoring
|
- Refactoring
|
||||||
- ...
|
- ...
|
||||||
description: |
|
description: |
|
||||||
...
|
- ...
|
||||||
|
- ...
|
||||||
title: |
|
title: |
|
||||||
...
|
...
|
||||||
{%- if enable_pr_diagram %}
|
{%- if enable_pr_diagram %}
|
||||||
changes_diagram: |
|
changes_diagram: |
|
||||||
```mermaid
|
```mermaid
|
||||||
flowchart LR
|
flowchart LR
|
||||||
...
|
...
|
||||||
```
|
```
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
{%- if enable_semantic_files_types %}
|
{%- if enable_semantic_files_types %}
|
||||||
pr_files:
|
pr_files:
|
||||||
|
|
|
||||||
|
|
@ -89,6 +89,14 @@ class TicketCompliance(BaseModel):
|
||||||
requires_further_human_verification: str = Field(description="Bullet-point list of items from the 'ticket_requirements' section above that cannot be assessed through code review alone, are unclear, or need further human review (e.g., browser testing, UI checks). Leave empty if all 'ticket_requirements' were marked as fully compliant or not compliant")
|
requires_further_human_verification: str = Field(description="Bullet-point list of items from the 'ticket_requirements' section above that cannot be assessed through code review alone, are unclear, or need further human review (e.g., browser testing, UI checks). Leave empty if all 'ticket_requirements' were marked as fully compliant or not compliant")
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
|
|
||||||
|
{%- if require_estimate_contribution_time_cost %}
|
||||||
|
|
||||||
|
class ContributionTimeCostEstimate(BaseModel):
|
||||||
|
best_case: str = Field(description="An expert in the relevant technology stack, with no unforeseen issues or bugs during the work.", examples=["45m", "5h", "30h"])
|
||||||
|
average_case: str = Field(description="A senior developer with only brief familiarity with this specific technology stack, and no major unforeseen issues.", examples=["45m", "5h", "30h"])
|
||||||
|
worst_case: str = Field(description="A senior developer with no prior experience in this specific technology stack, requiring significant time for research, debugging, or resolving unexpected errors.", examples=["45m", "5h", "30h"])
|
||||||
|
{%- endif %}
|
||||||
|
|
||||||
class Review(BaseModel):
|
class Review(BaseModel):
|
||||||
{%- if related_tickets %}
|
{%- if related_tickets %}
|
||||||
ticket_compliance_check: List[TicketCompliance] = Field(description="A list of compliance checks for the related tickets")
|
ticket_compliance_check: List[TicketCompliance] = Field(description="A list of compliance checks for the related tickets")
|
||||||
|
|
@ -96,6 +104,9 @@ class Review(BaseModel):
|
||||||
{%- if require_estimate_effort_to_review %}
|
{%- if require_estimate_effort_to_review %}
|
||||||
estimated_effort_to_review_[1-5]: int = Field(description="Estimate, on a scale of 1-5 (inclusive), the time and effort required to review this PR by an experienced and knowledgeable developer. 1 means short and easy review , 5 means long and hard review. Take into account the size, complexity, quality, and the needed changes of the PR code diff.")
|
estimated_effort_to_review_[1-5]: int = Field(description="Estimate, on a scale of 1-5 (inclusive), the time and effort required to review this PR by an experienced and knowledgeable developer. 1 means short and easy review , 5 means long and hard review. Take into account the size, complexity, quality, and the needed changes of the PR code diff.")
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
|
{%- if require_estimate_contribution_time_cost %}
|
||||||
|
contribution_time_cost_estimate: ContributionTimeCostEstimate = Field(description="An estimate of the time required to implement the changes, based on the quantity, quality, and complexity of the contribution, as well as the context from the PR description and commit messages.")
|
||||||
|
{%- endif %}
|
||||||
{%- if require_score %}
|
{%- if require_score %}
|
||||||
score: str = Field(description="Rate this PR on a scale of 0-100 (inclusive), where 0 means the worst possible PR code, and 100 means PR code of the highest quality, without any bugs or performance issues, that is ready to be merged immediately and run in production at scale.")
|
score: str = Field(description="Rate this PR on a scale of 0-100 (inclusive), where 0 means the worst possible PR code, and 100 means PR code of the highest quality, without any bugs or performance issues, that is ready to be merged immediately and run in production at scale.")
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
|
|
@ -170,6 +181,15 @@ review:
|
||||||
title: ...
|
title: ...
|
||||||
- ...
|
- ...
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
|
{%- if require_estimate_contribution_time_cost %}
|
||||||
|
contribution_time_cost_estimate:
|
||||||
|
best_case: |
|
||||||
|
...
|
||||||
|
average_case: |
|
||||||
|
...
|
||||||
|
worst_case: |
|
||||||
|
...
|
||||||
|
{%- endif %}
|
||||||
```
|
```
|
||||||
|
|
||||||
Answer should be a valid YAML, and nothing else. Each YAML output MUST be after a newline, with proper indent, and block scalar indicator ('|')
|
Answer should be a valid YAML, and nothing else. Each YAML output MUST be after a newline, with proper indent, and block scalar indicator ('|')
|
||||||
|
|
@ -196,6 +216,13 @@ Ticket Description:
|
||||||
{{ ticket.body }}
|
{{ ticket.body }}
|
||||||
#####
|
#####
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
|
|
||||||
|
{%- if ticket.requirements is defined and ticket.requirements %}
|
||||||
|
Ticket Requirements:
|
||||||
|
#####
|
||||||
|
{{ ticket.requirements }}
|
||||||
|
#####
|
||||||
|
{%- endif %}
|
||||||
=====
|
=====
|
||||||
{% endfor %}
|
{% endfor %}
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
|
|
@ -292,6 +319,15 @@ review:
|
||||||
title: ...
|
title: ...
|
||||||
- ...
|
- ...
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
|
{%- if require_estimate_contribution_time_cost %}
|
||||||
|
contribution_time_cost_estimate:
|
||||||
|
best_case: |
|
||||||
|
...
|
||||||
|
average_case: |
|
||||||
|
...
|
||||||
|
worst_case: |
|
||||||
|
...
|
||||||
|
{%- endif %}
|
||||||
```
|
```
|
||||||
(replace '...' with the actual values)
|
(replace '...' with the actual values)
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
|
|
|
||||||
|
|
@ -39,14 +39,6 @@ class PRCodeSuggestions:
|
||||||
self.git_provider.get_languages(), self.git_provider.get_files()
|
self.git_provider.get_languages(), self.git_provider.get_files()
|
||||||
)
|
)
|
||||||
|
|
||||||
# limit context specifically for the improve command, which has hard input to parse:
|
|
||||||
if get_settings().pr_code_suggestions.max_context_tokens:
|
|
||||||
MAX_CONTEXT_TOKENS_IMPROVE = get_settings().pr_code_suggestions.max_context_tokens
|
|
||||||
if get_settings().config.max_model_tokens > MAX_CONTEXT_TOKENS_IMPROVE:
|
|
||||||
get_logger().info(f"Setting max_model_tokens to {MAX_CONTEXT_TOKENS_IMPROVE} for PR improve")
|
|
||||||
get_settings().config.max_model_tokens_original = get_settings().config.max_model_tokens
|
|
||||||
get_settings().config.max_model_tokens = MAX_CONTEXT_TOKENS_IMPROVE
|
|
||||||
|
|
||||||
num_code_suggestions = int(get_settings().pr_code_suggestions.num_code_suggestions_per_chunk)
|
num_code_suggestions = int(get_settings().pr_code_suggestions.num_code_suggestions_per_chunk)
|
||||||
|
|
||||||
self.ai_handler = ai_handler()
|
self.ai_handler = ai_handler()
|
||||||
|
|
@ -614,11 +606,13 @@ class PRCodeSuggestions:
|
||||||
break
|
break
|
||||||
if original_initial_line:
|
if original_initial_line:
|
||||||
suggested_initial_line = new_code_snippet.splitlines()[0]
|
suggested_initial_line = new_code_snippet.splitlines()[0]
|
||||||
original_initial_spaces = len(original_initial_line) - len(original_initial_line.lstrip())
|
original_initial_spaces = len(original_initial_line) - len(original_initial_line.lstrip()) # lstrip works both for spaces and tabs
|
||||||
suggested_initial_spaces = len(suggested_initial_line) - len(suggested_initial_line.lstrip())
|
suggested_initial_spaces = len(suggested_initial_line) - len(suggested_initial_line.lstrip())
|
||||||
delta_spaces = original_initial_spaces - suggested_initial_spaces
|
delta_spaces = original_initial_spaces - suggested_initial_spaces
|
||||||
if delta_spaces > 0:
|
if delta_spaces > 0:
|
||||||
new_code_snippet = textwrap.indent(new_code_snippet, delta_spaces * " ").rstrip('\n')
|
# Detect indentation character from original line
|
||||||
|
indent_char = '\t' if original_initial_line.startswith('\t') else ' '
|
||||||
|
new_code_snippet = textwrap.indent(new_code_snippet, delta_spaces * indent_char).rstrip('\n')
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
get_logger().error(f"Error when dedenting code snippet for file {relevant_file}, error: {e}")
|
get_logger().error(f"Error when dedenting code snippet for file {relevant_file}, error: {e}")
|
||||||
|
|
||||||
|
|
@ -942,6 +936,7 @@ class PRCodeSuggestions:
|
||||||
with get_logger().contextualize(command="self_reflect_on_suggestions"):
|
with get_logger().contextualize(command="self_reflect_on_suggestions"):
|
||||||
response_reflect, finish_reason_reflect = await self.ai_handler.chat_completion(model=model,
|
response_reflect, finish_reason_reflect = await self.ai_handler.chat_completion(model=model,
|
||||||
system=system_prompt_reflect,
|
system=system_prompt_reflect,
|
||||||
|
temperature=get_settings().config.temperature,
|
||||||
user=user_prompt_reflect)
|
user=user_prompt_reflect)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
get_logger().info(f"Could not reflect on suggestions, error: {e}")
|
get_logger().info(f"Could not reflect on suggestions, error: {e}")
|
||||||
|
|
|
||||||
|
|
@ -30,8 +30,24 @@ class PRConfig:
|
||||||
return ""
|
return ""
|
||||||
|
|
||||||
def _prepare_pr_configs(self) -> str:
|
def _prepare_pr_configs(self) -> str:
|
||||||
conf_file = get_settings().find_file("configuration.toml")
|
try:
|
||||||
conf_settings = Dynaconf(settings_files=[conf_file])
|
conf_file = get_settings().find_file("configuration.toml")
|
||||||
|
dynconf_kwargs = {'core_loaders': [], # DISABLE default loaders, otherwise will load toml files more than once.
|
||||||
|
'loaders': ['pr_agent.custom_merge_loader'],
|
||||||
|
# Use a custom loader to merge sections, but overwrite their overlapping values. Do not use ENV variables.
|
||||||
|
'merge_enabled': True
|
||||||
|
# Merge multiple TOML files; prevent full section overwrite—only overlapping keys in sections overwrite prior ones.
|
||||||
|
}
|
||||||
|
conf_settings = Dynaconf(settings_files=[conf_file],
|
||||||
|
# Security: Disable all dynamic loading features
|
||||||
|
load_dotenv=False, # Don't load .env files
|
||||||
|
envvar_prefix=False,
|
||||||
|
**dynconf_kwargs
|
||||||
|
)
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().error("Caught exception during Dynaconf loading. Returning empty dict",
|
||||||
|
artifact={"exception": e})
|
||||||
|
conf_settings = {}
|
||||||
configuration_headers = [header.lower() for header in conf_settings.keys()]
|
configuration_headers = [header.lower() for header in conf_settings.keys()]
|
||||||
relevant_configs = {
|
relevant_configs = {
|
||||||
header: configs for header, configs in get_settings().to_dict().items()
|
header: configs for header, configs in get_settings().to_dict().items()
|
||||||
|
|
|
||||||
|
|
@ -59,6 +59,7 @@ class PRDescription:
|
||||||
|
|
||||||
# Initialize the variables dictionary
|
# Initialize the variables dictionary
|
||||||
self.COLLAPSIBLE_FILE_LIST_THRESHOLD = get_settings().pr_description.get("collapsible_file_list_threshold", 8)
|
self.COLLAPSIBLE_FILE_LIST_THRESHOLD = get_settings().pr_description.get("collapsible_file_list_threshold", 8)
|
||||||
|
enable_pr_diagram = get_settings().pr_description.get("enable_pr_diagram", False) and self.git_provider.is_supported("gfm_markdown") # github and gitlab support gfm_markdown
|
||||||
self.vars = {
|
self.vars = {
|
||||||
"title": self.git_provider.pr.title,
|
"title": self.git_provider.pr.title,
|
||||||
"branch": self.git_provider.get_pr_branch(),
|
"branch": self.git_provider.get_pr_branch(),
|
||||||
|
|
@ -73,7 +74,7 @@ class PRDescription:
|
||||||
"related_tickets": "",
|
"related_tickets": "",
|
||||||
"include_file_summary_changes": len(self.git_provider.get_diff_files()) <= self.COLLAPSIBLE_FILE_LIST_THRESHOLD,
|
"include_file_summary_changes": len(self.git_provider.get_diff_files()) <= self.COLLAPSIBLE_FILE_LIST_THRESHOLD,
|
||||||
"duplicate_prompt_examples": get_settings().config.get("duplicate_prompt_examples", False),
|
"duplicate_prompt_examples": get_settings().config.get("duplicate_prompt_examples", False),
|
||||||
"enable_pr_diagram": get_settings().pr_description.get("enable_pr_diagram", False),
|
"enable_pr_diagram": enable_pr_diagram,
|
||||||
}
|
}
|
||||||
|
|
||||||
self.user_description = self.git_provider.get_user_description()
|
self.user_description = self.git_provider.get_user_description()
|
||||||
|
|
@ -127,7 +128,7 @@ class PRDescription:
|
||||||
pr_title, pr_body, changes_walkthrough, pr_file_changes = self._prepare_pr_answer()
|
pr_title, pr_body, changes_walkthrough, pr_file_changes = self._prepare_pr_answer()
|
||||||
if not self.git_provider.is_supported(
|
if not self.git_provider.is_supported(
|
||||||
"publish_file_comments") or not get_settings().pr_description.inline_file_summary:
|
"publish_file_comments") or not get_settings().pr_description.inline_file_summary:
|
||||||
pr_body += "\n\n" + changes_walkthrough
|
pr_body += "\n\n" + changes_walkthrough + "___\n\n"
|
||||||
get_logger().debug("PR output", artifact={"title": pr_title, "body": pr_body})
|
get_logger().debug("PR output", artifact={"title": pr_title, "body": pr_body})
|
||||||
|
|
||||||
# Add help text if gfm_markdown is supported
|
# Add help text if gfm_markdown is supported
|
||||||
|
|
@ -168,7 +169,7 @@ class PRDescription:
|
||||||
|
|
||||||
# publish description
|
# publish description
|
||||||
if get_settings().pr_description.publish_description_as_comment:
|
if get_settings().pr_description.publish_description_as_comment:
|
||||||
full_markdown_description = f"## Title\n\n{pr_title}\n\n___\n{pr_body}"
|
full_markdown_description = f"## Title\n\n{pr_title.strip()}\n\n___\n{pr_body}"
|
||||||
if get_settings().pr_description.publish_description_as_comment_persistent:
|
if get_settings().pr_description.publish_description_as_comment_persistent:
|
||||||
self.git_provider.publish_persistent_comment(full_markdown_description,
|
self.git_provider.publish_persistent_comment(full_markdown_description,
|
||||||
initial_header="## Title",
|
initial_header="## Title",
|
||||||
|
|
@ -178,7 +179,7 @@ class PRDescription:
|
||||||
else:
|
else:
|
||||||
self.git_provider.publish_comment(full_markdown_description)
|
self.git_provider.publish_comment(full_markdown_description)
|
||||||
else:
|
else:
|
||||||
self.git_provider.publish_description(pr_title, pr_body)
|
self.git_provider.publish_description(pr_title.strip(), pr_body)
|
||||||
|
|
||||||
# publish final update message
|
# publish final update message
|
||||||
if (get_settings().pr_description.final_update_message and not get_settings().config.get('is_auto_command', False)):
|
if (get_settings().pr_description.final_update_message and not get_settings().config.get('is_auto_command', False)):
|
||||||
|
|
@ -330,7 +331,8 @@ class PRDescription:
|
||||||
else:
|
else:
|
||||||
original_prediction_dict = original_prediction_loaded
|
original_prediction_dict = original_prediction_loaded
|
||||||
if original_prediction_dict:
|
if original_prediction_dict:
|
||||||
filenames_predicted = [file.get('filename', '').strip() for file in original_prediction_dict.get('pr_files', [])]
|
files = original_prediction_dict.get('pr_files', [])
|
||||||
|
filenames_predicted = [file.get('filename', '').strip() for file in files if isinstance(file, dict)]
|
||||||
else:
|
else:
|
||||||
filenames_predicted = []
|
filenames_predicted = []
|
||||||
|
|
||||||
|
|
@ -537,6 +539,11 @@ class PRDescription:
|
||||||
get_logger().error(f"Failing to process walkthrough {self.pr_id}: {e}")
|
get_logger().error(f"Failing to process walkthrough {self.pr_id}: {e}")
|
||||||
body = body.replace('pr_agent:walkthrough', "")
|
body = body.replace('pr_agent:walkthrough', "")
|
||||||
|
|
||||||
|
# Add support for pr_agent:diagram marker (plain and HTML comment formats)
|
||||||
|
ai_diagram = self.data.get('changes_diagram')
|
||||||
|
if ai_diagram:
|
||||||
|
body = re.sub(r'<!--\s*pr_agent:diagram\s*-->|pr_agent:diagram', ai_diagram, body)
|
||||||
|
|
||||||
return title, body, walkthrough_gfm, pr_file_changes
|
return title, body, walkthrough_gfm, pr_file_changes
|
||||||
|
|
||||||
def _prepare_pr_answer(self) -> Tuple[str, str, str, List[dict]]:
|
def _prepare_pr_answer(self) -> Tuple[str, str, str, List[dict]]:
|
||||||
|
|
@ -549,15 +556,11 @@ class PRDescription:
|
||||||
"""
|
"""
|
||||||
|
|
||||||
# Iterate over the dictionary items and append the key and value to 'markdown_text' in a markdown format
|
# Iterate over the dictionary items and append the key and value to 'markdown_text' in a markdown format
|
||||||
markdown_text = ""
|
|
||||||
# Don't display 'PR Labels'
|
# Don't display 'PR Labels'
|
||||||
if 'labels' in self.data and self.git_provider.is_supported("get_labels"):
|
if 'labels' in self.data and self.git_provider.is_supported("get_labels"):
|
||||||
self.data.pop('labels')
|
self.data.pop('labels')
|
||||||
if not get_settings().pr_description.enable_pr_type:
|
if not get_settings().pr_description.enable_pr_type:
|
||||||
self.data.pop('type')
|
self.data.pop('type')
|
||||||
for key, value in self.data.items():
|
|
||||||
markdown_text += f"## **{key}**\n\n"
|
|
||||||
markdown_text += f"{value}\n\n"
|
|
||||||
|
|
||||||
# Remove the 'PR Title' key from the dictionary
|
# Remove the 'PR Title' key from the dictionary
|
||||||
ai_title = self.data.pop('title', self.vars["title"])
|
ai_title = self.data.pop('title', self.vars["title"])
|
||||||
|
|
@ -573,6 +576,10 @@ class PRDescription:
|
||||||
pr_body, changes_walkthrough = "", ""
|
pr_body, changes_walkthrough = "", ""
|
||||||
pr_file_changes = []
|
pr_file_changes = []
|
||||||
for idx, (key, value) in enumerate(self.data.items()):
|
for idx, (key, value) in enumerate(self.data.items()):
|
||||||
|
if key == 'changes_diagram':
|
||||||
|
pr_body += f"### {PRDescriptionHeader.DIAGRAM_WALKTHROUGH.value}\n\n"
|
||||||
|
pr_body += f"{value}\n\n"
|
||||||
|
continue
|
||||||
if key == 'pr_files':
|
if key == 'pr_files':
|
||||||
value = self.file_label_dict
|
value = self.file_label_dict
|
||||||
else:
|
else:
|
||||||
|
|
@ -591,9 +598,15 @@ class PRDescription:
|
||||||
pr_body += f'- `{filename}`: {description}\n'
|
pr_body += f'- `{filename}`: {description}\n'
|
||||||
if self.git_provider.is_supported("gfm_markdown"):
|
if self.git_provider.is_supported("gfm_markdown"):
|
||||||
pr_body += "</details>\n"
|
pr_body += "</details>\n"
|
||||||
elif 'pr_files' in key.lower() and get_settings().pr_description.enable_semantic_files_types:
|
elif 'pr_files' in key.lower() and get_settings().pr_description.enable_semantic_files_types: # 'File Walkthrough' section
|
||||||
changes_walkthrough, pr_file_changes = self.process_pr_files_prediction(changes_walkthrough, value)
|
changes_walkthrough_table, pr_file_changes = self.process_pr_files_prediction(changes_walkthrough, value)
|
||||||
changes_walkthrough = f"{PRDescriptionHeader.CHANGES_WALKTHROUGH.value}\n{changes_walkthrough}"
|
if get_settings().pr_description.get('file_table_collapsible_open_by_default', False):
|
||||||
|
initial_status = " open"
|
||||||
|
else:
|
||||||
|
initial_status = ""
|
||||||
|
changes_walkthrough = f"<details{initial_status}> <summary><h3> {PRDescriptionHeader.FILE_WALKTHROUGH.value}</h3></summary>\n\n"
|
||||||
|
changes_walkthrough += f"{changes_walkthrough_table}\n\n"
|
||||||
|
changes_walkthrough += "</details>\n\n"
|
||||||
elif key.lower().strip() == 'description':
|
elif key.lower().strip() == 'description':
|
||||||
if isinstance(value, list):
|
if isinstance(value, list):
|
||||||
value = ', '.join(v.rstrip() for v in value)
|
value = ', '.join(v.rstrip() for v in value)
|
||||||
|
|
@ -627,14 +640,19 @@ class PRDescription:
|
||||||
artifact={"file": file})
|
artifact={"file": file})
|
||||||
continue
|
continue
|
||||||
filename = file['filename'].replace("'", "`").replace('"', '`')
|
filename = file['filename'].replace("'", "`").replace('"', '`')
|
||||||
changes_summary = file.get('changes_summary', "").strip()
|
changes_summary = file.get('changes_summary', "")
|
||||||
|
if not changes_summary and self.vars.get('include_file_summary_changes', True):
|
||||||
|
get_logger().warning(f"Empty changes summary in file label dict, skipping file",
|
||||||
|
artifact={"file": file})
|
||||||
|
continue
|
||||||
|
changes_summary = changes_summary.strip()
|
||||||
changes_title = file['changes_title'].strip()
|
changes_title = file['changes_title'].strip()
|
||||||
label = file.get('label').strip().lower()
|
label = file.get('label').strip().lower()
|
||||||
if label not in file_label_dict:
|
if label not in file_label_dict:
|
||||||
file_label_dict[label] = []
|
file_label_dict[label] = []
|
||||||
file_label_dict[label].append((filename, changes_title, changes_summary))
|
file_label_dict[label].append((filename, changes_title, changes_summary))
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
get_logger().error(f"Error preparing file label dict {self.pr_id}: {e}")
|
get_logger().exception(f"Error preparing file label dict {self.pr_id}")
|
||||||
pass
|
pass
|
||||||
return file_label_dict
|
return file_label_dict
|
||||||
|
|
||||||
|
|
@ -714,7 +732,7 @@ class PRDescription:
|
||||||
pr_body += """</tr></tbody></table>"""
|
pr_body += """</tr></tbody></table>"""
|
||||||
|
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
get_logger().error(f"Error processing PR files to markdown {self.pr_id}: {str(e)}")
|
get_logger().error(f"Error processing pr files to markdown {self.pr_id}: {str(e)}")
|
||||||
pass
|
pass
|
||||||
return pr_body, pr_comments
|
return pr_body, pr_comments
|
||||||
|
|
||||||
|
|
@ -770,14 +788,21 @@ def insert_br_after_x_chars(text: str, x=70):
|
||||||
if count_chars_without_html(text) < x:
|
if count_chars_without_html(text) < x:
|
||||||
return text
|
return text
|
||||||
|
|
||||||
|
is_list = text.lstrip().startswith(("- ", "* "))
|
||||||
|
|
||||||
# replace odd instances of ` with <code> and even instances of ` with </code>
|
# replace odd instances of ` with <code> and even instances of ` with </code>
|
||||||
text = replace_code_tags(text)
|
text = replace_code_tags(text)
|
||||||
|
|
||||||
# convert list items to <li>
|
# convert list items to <li> only if the text is identified as a list
|
||||||
if text.startswith("- ") or text.startswith("* "):
|
if is_list:
|
||||||
text = "<li>" + text[2:]
|
# To handle lists that start with indentation
|
||||||
text = text.replace("\n- ", '<br><li> ').replace("\n - ", '<br><li> ')
|
leading_whitespace = text[:len(text) - len(text.lstrip())]
|
||||||
text = text.replace("\n* ", '<br><li> ').replace("\n * ", '<br><li> ')
|
body = text.lstrip()
|
||||||
|
body = "<li>" + body[2:]
|
||||||
|
text = leading_whitespace + body
|
||||||
|
|
||||||
|
text = text.replace("\n- ", '<br><li> ').replace("\n - ", '<br><li> ')
|
||||||
|
text = text.replace("\n* ", '<br><li> ').replace("\n * ", '<br><li> ')
|
||||||
|
|
||||||
# convert new lines to <br>
|
# convert new lines to <br>
|
||||||
text = text.replace("\n", '<br>')
|
text = text.replace("\n", '<br>')
|
||||||
|
|
@ -817,7 +842,13 @@ def insert_br_after_x_chars(text: str, x=70):
|
||||||
is_inside_code = True
|
is_inside_code = True
|
||||||
if "</code>" in word:
|
if "</code>" in word:
|
||||||
is_inside_code = False
|
is_inside_code = False
|
||||||
return ''.join(new_text).strip()
|
|
||||||
|
processed_text = ''.join(new_text).strip()
|
||||||
|
|
||||||
|
if is_list:
|
||||||
|
processed_text = f"<ul>{processed_text}</ul>"
|
||||||
|
|
||||||
|
return processed_text
|
||||||
|
|
||||||
|
|
||||||
def replace_code_tags(text):
|
def replace_code_tags(text):
|
||||||
|
|
|
||||||
|
|
@ -85,6 +85,7 @@ class PRReviewer:
|
||||||
"require_score": get_settings().pr_reviewer.require_score_review,
|
"require_score": get_settings().pr_reviewer.require_score_review,
|
||||||
"require_tests": get_settings().pr_reviewer.require_tests_review,
|
"require_tests": get_settings().pr_reviewer.require_tests_review,
|
||||||
"require_estimate_effort_to_review": get_settings().pr_reviewer.require_estimate_effort_to_review,
|
"require_estimate_effort_to_review": get_settings().pr_reviewer.require_estimate_effort_to_review,
|
||||||
|
"require_estimate_contribution_time_cost": get_settings().pr_reviewer.require_estimate_contribution_time_cost,
|
||||||
'require_can_be_split_review': get_settings().pr_reviewer.require_can_be_split_review,
|
'require_can_be_split_review': get_settings().pr_reviewer.require_can_be_split_review,
|
||||||
'require_security_review': get_settings().pr_reviewer.require_security_review,
|
'require_security_review': get_settings().pr_reviewer.require_security_review,
|
||||||
'require_todo_scan': get_settings().pr_reviewer.get("require_todo_scan", False),
|
'require_todo_scan': get_settings().pr_reviewer.get("require_todo_scan", False),
|
||||||
|
|
|
||||||
|
|
@ -174,6 +174,87 @@ class PRSimilarIssue:
|
||||||
else:
|
else:
|
||||||
get_logger().info('No new issues to update')
|
get_logger().info('No new issues to update')
|
||||||
|
|
||||||
|
elif get_settings().pr_similar_issue.vectordb == "qdrant":
|
||||||
|
try:
|
||||||
|
import qdrant_client
|
||||||
|
from qdrant_client.models import (Distance, FieldCondition,
|
||||||
|
Filter, MatchValue,
|
||||||
|
PointStruct, VectorParams)
|
||||||
|
except Exception:
|
||||||
|
raise Exception("Please install qdrant-client to use qdrant as vectordb")
|
||||||
|
|
||||||
|
api_key = None
|
||||||
|
url = None
|
||||||
|
try:
|
||||||
|
api_key = get_settings().qdrant.api_key
|
||||||
|
url = get_settings().qdrant.url
|
||||||
|
except Exception:
|
||||||
|
if not self.cli_mode:
|
||||||
|
repo_name, original_issue_number = self.git_provider._parse_issue_url(self.issue_url.split('=')[-1])
|
||||||
|
issue_main = self.git_provider.repo_obj.get_issue(original_issue_number)
|
||||||
|
issue_main.create_comment("Please set qdrant url and api key in secrets file")
|
||||||
|
raise Exception("Please set qdrant url and api key in secrets file")
|
||||||
|
|
||||||
|
self.qdrant = qdrant_client.QdrantClient(url=url, api_key=api_key)
|
||||||
|
|
||||||
|
run_from_scratch = False
|
||||||
|
ingest = True
|
||||||
|
|
||||||
|
if not self.qdrant.collection_exists(collection_name=self.index_name):
|
||||||
|
run_from_scratch = True
|
||||||
|
ingest = False
|
||||||
|
self.qdrant.create_collection(
|
||||||
|
collection_name=self.index_name,
|
||||||
|
vectors_config=VectorParams(size=1536, distance=Distance.COSINE),
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
if get_settings().pr_similar_issue.force_update_dataset:
|
||||||
|
ingest = True
|
||||||
|
else:
|
||||||
|
response = self.qdrant.count(
|
||||||
|
collection_name=self.index_name,
|
||||||
|
count_filter=Filter(must=[
|
||||||
|
FieldCondition(key="metadata.repo", match=MatchValue(value=repo_name_for_index)),
|
||||||
|
FieldCondition(key="id", match=MatchValue(value=f"example_issue_{repo_name_for_index}")),
|
||||||
|
]),
|
||||||
|
)
|
||||||
|
ingest = True if response.count == 0 else False
|
||||||
|
|
||||||
|
if run_from_scratch or ingest:
|
||||||
|
get_logger().info('Indexing the entire repo...')
|
||||||
|
get_logger().info('Getting issues...')
|
||||||
|
issues = list(repo_obj.get_issues(state='all'))
|
||||||
|
get_logger().info('Done')
|
||||||
|
self._update_qdrant_with_issues(issues, repo_name_for_index, ingest=ingest)
|
||||||
|
else:
|
||||||
|
issues_to_update = []
|
||||||
|
issues_paginated_list = repo_obj.get_issues(state='all')
|
||||||
|
counter = 1
|
||||||
|
for issue in issues_paginated_list:
|
||||||
|
if issue.pull_request:
|
||||||
|
continue
|
||||||
|
issue_str, comments, number = self._process_issue(issue)
|
||||||
|
issue_key = f"issue_{number}"
|
||||||
|
point_id = issue_key + "." + "issue"
|
||||||
|
response = self.qdrant.count(
|
||||||
|
collection_name=self.index_name,
|
||||||
|
count_filter=Filter(must=[
|
||||||
|
FieldCondition(key="id", match=MatchValue(value=point_id)),
|
||||||
|
FieldCondition(key="metadata.repo", match=MatchValue(value=repo_name_for_index)),
|
||||||
|
]),
|
||||||
|
)
|
||||||
|
if response.count == 0:
|
||||||
|
counter += 1
|
||||||
|
issues_to_update.append(issue)
|
||||||
|
else:
|
||||||
|
break
|
||||||
|
|
||||||
|
if issues_to_update:
|
||||||
|
get_logger().info(f'Updating index with {counter} new issues...')
|
||||||
|
self._update_qdrant_with_issues(issues_to_update, repo_name_for_index, ingest=True)
|
||||||
|
else:
|
||||||
|
get_logger().info('No new issues to update')
|
||||||
|
|
||||||
|
|
||||||
async def run(self):
|
async def run(self):
|
||||||
get_logger().info('Getting issue...')
|
get_logger().info('Getting issue...')
|
||||||
|
|
@ -246,6 +327,36 @@ class PRSimilarIssue:
|
||||||
score_list.append(str("{:.2f}".format(1-r['_distance'])))
|
score_list.append(str("{:.2f}".format(1-r['_distance'])))
|
||||||
get_logger().info('Done')
|
get_logger().info('Done')
|
||||||
|
|
||||||
|
elif get_settings().pr_similar_issue.vectordb == "qdrant":
|
||||||
|
from qdrant_client.models import FieldCondition, Filter, MatchValue
|
||||||
|
res = self.qdrant.search(
|
||||||
|
collection_name=self.index_name,
|
||||||
|
query_vector=embeds[0],
|
||||||
|
limit=5,
|
||||||
|
query_filter=Filter(must=[FieldCondition(key="metadata.repo", match=MatchValue(value=self.repo_name_for_index))]),
|
||||||
|
with_payload=True,
|
||||||
|
)
|
||||||
|
|
||||||
|
for r in res:
|
||||||
|
rid = r.payload.get("id", "")
|
||||||
|
if 'example_issue_' in rid:
|
||||||
|
continue
|
||||||
|
try:
|
||||||
|
issue_number = int(rid.split('.')[0].split('_')[-1])
|
||||||
|
except Exception:
|
||||||
|
get_logger().debug(f"Failed to parse issue number from {rid}")
|
||||||
|
continue
|
||||||
|
if original_issue_number == issue_number:
|
||||||
|
continue
|
||||||
|
if issue_number not in relevant_issues_number_list:
|
||||||
|
relevant_issues_number_list.append(issue_number)
|
||||||
|
if 'comment' in rid:
|
||||||
|
relevant_comment_number_list.append(int(rid.split('.')[1].split('_')[-1]))
|
||||||
|
else:
|
||||||
|
relevant_comment_number_list.append(-1)
|
||||||
|
score_list.append(str("{:.2f}".format(r.score)))
|
||||||
|
get_logger().info('Done')
|
||||||
|
|
||||||
get_logger().info('Publishing response...')
|
get_logger().info('Publishing response...')
|
||||||
similar_issues_str = "### Similar Issues\n___\n\n"
|
similar_issues_str = "### Similar Issues\n___\n\n"
|
||||||
|
|
||||||
|
|
@ -458,6 +569,101 @@ class PRSimilarIssue:
|
||||||
get_logger().info('Done')
|
get_logger().info('Done')
|
||||||
|
|
||||||
|
|
||||||
|
def _update_qdrant_with_issues(self, issues_list, repo_name_for_index, ingest=False):
|
||||||
|
try:
|
||||||
|
import uuid
|
||||||
|
|
||||||
|
import pandas as pd
|
||||||
|
from qdrant_client.models import PointStruct
|
||||||
|
except Exception:
|
||||||
|
raise
|
||||||
|
|
||||||
|
get_logger().info('Processing issues...')
|
||||||
|
corpus = Corpus()
|
||||||
|
example_issue_record = Record(
|
||||||
|
id=f"example_issue_{repo_name_for_index}",
|
||||||
|
text="example_issue",
|
||||||
|
metadata=Metadata(repo=repo_name_for_index)
|
||||||
|
)
|
||||||
|
corpus.append(example_issue_record)
|
||||||
|
|
||||||
|
counter = 0
|
||||||
|
for issue in issues_list:
|
||||||
|
if issue.pull_request:
|
||||||
|
continue
|
||||||
|
|
||||||
|
counter += 1
|
||||||
|
if counter % 100 == 0:
|
||||||
|
get_logger().info(f"Scanned {counter} issues")
|
||||||
|
if counter >= self.max_issues_to_scan:
|
||||||
|
get_logger().info(f"Scanned {self.max_issues_to_scan} issues, stopping")
|
||||||
|
break
|
||||||
|
|
||||||
|
issue_str, comments, number = self._process_issue(issue)
|
||||||
|
issue_key = f"issue_{number}"
|
||||||
|
username = issue.user.login
|
||||||
|
created_at = str(issue.created_at)
|
||||||
|
if len(issue_str) < 8000 or \
|
||||||
|
self.token_handler.count_tokens(issue_str) < get_max_tokens(MODEL):
|
||||||
|
issue_record = Record(
|
||||||
|
id=issue_key + "." + "issue",
|
||||||
|
text=issue_str,
|
||||||
|
metadata=Metadata(repo=repo_name_for_index,
|
||||||
|
username=username,
|
||||||
|
created_at=created_at,
|
||||||
|
level=IssueLevel.ISSUE)
|
||||||
|
)
|
||||||
|
corpus.append(issue_record)
|
||||||
|
if comments:
|
||||||
|
for j, comment in enumerate(comments):
|
||||||
|
comment_body = comment.body
|
||||||
|
num_words_comment = len(comment_body.split())
|
||||||
|
if num_words_comment < 10 or not isinstance(comment_body, str):
|
||||||
|
continue
|
||||||
|
|
||||||
|
if len(comment_body) < 8000 or \
|
||||||
|
self.token_handler.count_tokens(comment_body) < MAX_TOKENS[MODEL]:
|
||||||
|
comment_record = Record(
|
||||||
|
id=issue_key + ".comment_" + str(j + 1),
|
||||||
|
text=comment_body,
|
||||||
|
metadata=Metadata(repo=repo_name_for_index,
|
||||||
|
username=username,
|
||||||
|
created_at=created_at,
|
||||||
|
level=IssueLevel.COMMENT)
|
||||||
|
)
|
||||||
|
corpus.append(comment_record)
|
||||||
|
|
||||||
|
df = pd.DataFrame(corpus.dict()["documents"])
|
||||||
|
get_logger().info('Done')
|
||||||
|
|
||||||
|
get_logger().info('Embedding...')
|
||||||
|
openai.api_key = get_settings().openai.key
|
||||||
|
list_to_encode = list(df["text"].values)
|
||||||
|
try:
|
||||||
|
res = openai.Embedding.create(input=list_to_encode, engine=MODEL)
|
||||||
|
embeds = [record['embedding'] for record in res['data']]
|
||||||
|
except Exception:
|
||||||
|
embeds = []
|
||||||
|
get_logger().error('Failed to embed entire list, embedding one by one...')
|
||||||
|
for i, text in enumerate(list_to_encode):
|
||||||
|
try:
|
||||||
|
res = openai.Embedding.create(input=[text], engine=MODEL)
|
||||||
|
embeds.append(res['data'][0]['embedding'])
|
||||||
|
except Exception:
|
||||||
|
embeds.append([0] * 1536)
|
||||||
|
df["vector"] = embeds
|
||||||
|
get_logger().info('Done')
|
||||||
|
|
||||||
|
get_logger().info('Upserting into Qdrant...')
|
||||||
|
points = []
|
||||||
|
for row in df.to_dict(orient="records"):
|
||||||
|
points.append(
|
||||||
|
PointStruct(id=uuid.uuid5(uuid.NAMESPACE_DNS, row["id"]).hex, vector=row["vector"], payload={"id": row["id"], "text": row["text"], "metadata": row["metadata"]})
|
||||||
|
)
|
||||||
|
self.qdrant.upsert(collection_name=self.index_name, points=points)
|
||||||
|
get_logger().info('Done')
|
||||||
|
|
||||||
|
|
||||||
class IssueLevel(str, Enum):
|
class IssueLevel(str, Enum):
|
||||||
ISSUE = "issue"
|
ISSUE = "issue"
|
||||||
COMMENT = "comment"
|
COMMENT = "comment"
|
||||||
|
|
|
||||||
|
|
@ -3,6 +3,7 @@ import traceback
|
||||||
|
|
||||||
from pr_agent.config_loader import get_settings
|
from pr_agent.config_loader import get_settings
|
||||||
from pr_agent.git_providers import GithubProvider
|
from pr_agent.git_providers import GithubProvider
|
||||||
|
from pr_agent.git_providers import AzureDevopsProvider
|
||||||
from pr_agent.log import get_logger
|
from pr_agent.log import get_logger
|
||||||
|
|
||||||
# Compile the regex pattern once, outside the function
|
# Compile the regex pattern once, outside the function
|
||||||
|
|
@ -131,6 +132,32 @@ async def extract_tickets(git_provider):
|
||||||
|
|
||||||
return tickets_content
|
return tickets_content
|
||||||
|
|
||||||
|
elif isinstance(git_provider, AzureDevopsProvider):
|
||||||
|
tickets_info = git_provider.get_linked_work_items()
|
||||||
|
tickets_content = []
|
||||||
|
for ticket in tickets_info:
|
||||||
|
try:
|
||||||
|
ticket_body_str = ticket.get("body", "")
|
||||||
|
if len(ticket_body_str) > MAX_TICKET_CHARACTERS:
|
||||||
|
ticket_body_str = ticket_body_str[:MAX_TICKET_CHARACTERS] + "..."
|
||||||
|
|
||||||
|
tickets_content.append(
|
||||||
|
{
|
||||||
|
"ticket_id": ticket.get("id"),
|
||||||
|
"ticket_url": ticket.get("url"),
|
||||||
|
"title": ticket.get("title"),
|
||||||
|
"body": ticket_body_str,
|
||||||
|
"requirements": ticket.get("acceptance_criteria", ""),
|
||||||
|
"labels": ", ".join(ticket.get("labels", [])),
|
||||||
|
}
|
||||||
|
)
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().error(
|
||||||
|
f"Error processing Azure DevOps ticket: {e}",
|
||||||
|
artifact={"traceback": traceback.format_exc()},
|
||||||
|
)
|
||||||
|
return tickets_content
|
||||||
|
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
get_logger().error(f"Error extracting tickets error= {e}",
|
get_logger().error(f"Error extracting tickets error= {e}",
|
||||||
artifact={"traceback": traceback.format_exc()})
|
artifact={"traceback": traceback.format_exc()})
|
||||||
|
|
|
||||||
30
pr_compliance_checklist.yaml
Normal file
30
pr_compliance_checklist.yaml
Normal file
|
|
@ -0,0 +1,30 @@
|
||||||
|
pr_compliances:
|
||||||
|
- title: "Consistent Naming Conventions"
|
||||||
|
compliance_label: false
|
||||||
|
objective: "All new variables, functions, and classes must follow the project's established naming standards"
|
||||||
|
success_criteria: "All identifiers follow the established naming patterns (camelCase, snake_case, etc.)"
|
||||||
|
failure_criteria: "Inconsistent or non-standard naming that deviates from project conventions"
|
||||||
|
|
||||||
|
- title: "No Dead or Commented-Out Code"
|
||||||
|
compliance_label: false
|
||||||
|
objective: "Keep the codebase clean by ensuring all submitted code is active and necessary"
|
||||||
|
success_criteria: "All code in the PR is active and serves a purpose; no commented-out blocks"
|
||||||
|
failure_criteria: "Presence of unused, dead, or commented-out code sections"
|
||||||
|
|
||||||
|
- title: "Robust Error Handling"
|
||||||
|
compliance_label: false
|
||||||
|
objective: "Ensure potential errors and edge cases are anticipated and handled gracefully throughout the code"
|
||||||
|
success_criteria: "All error scenarios are properly caught and handled with appropriate responses"
|
||||||
|
failure_criteria: "Unhandled exceptions, ignored errors, or missing edge case handling"
|
||||||
|
|
||||||
|
- title: "Single Responsibility for Functions"
|
||||||
|
compliance_label: false
|
||||||
|
objective: "Each function should have a single, well-defined responsibility"
|
||||||
|
success_criteria: "Functions perform one cohesive task with a single purpose"
|
||||||
|
failure_criteria: "Functions that combine multiple unrelated operations or handle several distinct concerns"
|
||||||
|
|
||||||
|
- title: "When relevant, utilize early return"
|
||||||
|
compliance_label: false
|
||||||
|
objective: "In a code snippet containing multiple logic conditions (such as 'if-else'), prefer an early return on edge cases than deep nesting"
|
||||||
|
success_criteria: "When relevant, utilize early return that reduces nesting"
|
||||||
|
failure_criteria: "Unjustified deep nesting that can be simplified by early return"
|
||||||
|
|
@ -1,22 +1,22 @@
|
||||||
[build-system]
|
[build-system]
|
||||||
requires = ["setuptools>=61.0"]
|
requires = ["setuptools>=61.0", "wheel"]
|
||||||
build-backend = "setuptools.build_meta"
|
build-backend = "setuptools.build_meta"
|
||||||
|
|
||||||
[project]
|
[project]
|
||||||
name = "pr-agent"
|
name = "pr-agent"
|
||||||
version = "0.2.7"
|
version = "0.3.1"
|
||||||
|
|
||||||
authors = [{ name = "QodoAI", email = "tal.r@qodo.ai" }]
|
authors = [{ name = "QodoAI", email = "ofir.f@qodo.ai" }]
|
||||||
|
|
||||||
maintainers = [
|
maintainers = [
|
||||||
{ name = "Tal Ridnik", email = "tal.r@qodo.ai" },
|
{ name = "Ofir Friedman", email = "ofir.f@qodo.ai" },
|
||||||
]
|
]
|
||||||
|
|
||||||
description = "QodoAI PR-Agent aims to help efficiently review and handle pull requests, by providing AI feedbacks and suggestions."
|
description = "QodoAI PR-Agent aims to help efficiently review and handle pull requests, by providing AI feedbacks and suggestions."
|
||||||
readme = "README.md"
|
readme = "README.md"
|
||||||
requires-python = ">=3.12"
|
requires-python = ">=3.12"
|
||||||
keywords = ["AI", "Agents", "Pull Request", "Automation", "Code Review"]
|
keywords = ["AI", "Agents", "Pull Request", "Automation", "Code Review"]
|
||||||
license = "Apache-2.0"
|
license = { file = "LICENSE" }
|
||||||
|
|
||||||
classifiers = [
|
classifiers = [
|
||||||
"Intended Audience :: Developers",
|
"Intended Audience :: Developers",
|
||||||
|
|
@ -34,7 +34,6 @@ dependencies = { file = ["requirements.txt"] }
|
||||||
|
|
||||||
[tool.setuptools]
|
[tool.setuptools]
|
||||||
include-package-data = true
|
include-package-data = true
|
||||||
license-files = ["LICENSE"]
|
|
||||||
|
|
||||||
[tool.setuptools.packages.find]
|
[tool.setuptools.packages.find]
|
||||||
where = ["."]
|
where = ["."]
|
||||||
|
|
|
||||||
|
|
@ -1,19 +1,19 @@
|
||||||
aiohttp==3.9.5
|
aiohttp==3.12.15
|
||||||
anthropic>=0.52.0
|
anthropic>=0.69.0
|
||||||
#anthropic[vertex]==0.47.1
|
#anthropic[vertex]==0.47.1
|
||||||
atlassian-python-api==3.41.4
|
atlassian-python-api==3.41.4
|
||||||
azure-devops==7.1.0b3
|
azure-devops==7.1.0b3
|
||||||
azure-identity==1.15.0
|
azure-identity==1.25.0
|
||||||
boto3==1.33.6
|
boto3==1.40.45
|
||||||
certifi==2024.8.30
|
certifi==2024.8.30
|
||||||
dynaconf==3.2.4
|
dynaconf==3.2.4
|
||||||
fastapi==0.111.0
|
fastapi==0.118.0
|
||||||
GitPython==3.1.41
|
GitPython==3.1.41
|
||||||
google-cloud-aiplatform==1.38.0
|
google-cloud-aiplatform==1.38.0
|
||||||
google-generativeai==0.8.3
|
google-generativeai==0.8.3
|
||||||
google-cloud-storage==2.10.0
|
google-cloud-storage==2.10.0
|
||||||
Jinja2==3.1.2
|
Jinja2==3.1.6
|
||||||
litellm==1.70.4
|
litellm==1.77.7
|
||||||
loguru==0.7.2
|
loguru==0.7.2
|
||||||
msrest==0.7.1
|
msrest==0.7.1
|
||||||
openai>=1.55.3
|
openai>=1.55.3
|
||||||
|
|
@ -27,7 +27,7 @@ tiktoken==0.8.0
|
||||||
ujson==5.8.0
|
ujson==5.8.0
|
||||||
uvicorn==0.22.0
|
uvicorn==0.22.0
|
||||||
tenacity==8.2.3
|
tenacity==8.2.3
|
||||||
gunicorn==22.0.0
|
gunicorn==23.0.0
|
||||||
pytest-cov==5.0.0
|
pytest-cov==5.0.0
|
||||||
pydantic==2.8.2
|
pydantic==2.8.2
|
||||||
html2text==2024.2.26
|
html2text==2024.2.26
|
||||||
|
|
@ -36,6 +36,7 @@ giteapy==1.0.8
|
||||||
# pinecone-client
|
# pinecone-client
|
||||||
# pinecone-datasets @ git+https://github.com/mrT23/pinecone-datasets.git@main
|
# pinecone-datasets @ git+https://github.com/mrT23/pinecone-datasets.git@main
|
||||||
# lancedb==0.5.1
|
# lancedb==0.5.1
|
||||||
|
# qdrant-client==1.15.1
|
||||||
# uncomment this to support language LangChainOpenAIHandler
|
# uncomment this to support language LangChainOpenAIHandler
|
||||||
# langchain==0.2.0
|
# langchain==0.2.0
|
||||||
# langchain-core==0.2.28
|
# langchain-core==0.2.28
|
||||||
|
|
|
||||||
92
tests/unittest/test_add_docs_trigger.py
Normal file
92
tests/unittest/test_add_docs_trigger.py
Normal file
|
|
@ -0,0 +1,92 @@
|
||||||
|
import pytest
|
||||||
|
from pr_agent.servers.github_app import handle_new_pr_opened
|
||||||
|
from pr_agent.tools.pr_add_docs import PRAddDocs
|
||||||
|
from pr_agent.agent.pr_agent import PRAgent
|
||||||
|
from pr_agent.config_loader import get_settings
|
||||||
|
from pr_agent.identity_providers.identity_provider import Eligibility
|
||||||
|
from pr_agent.identity_providers import get_identity_provider
|
||||||
|
|
||||||
|
|
||||||
|
@pytest.mark.asyncio
|
||||||
|
@pytest.mark.parametrize(
|
||||||
|
"action,draft,state,should_run",
|
||||||
|
[
|
||||||
|
("opened", False, "open", True),
|
||||||
|
("edited", False, "open", False),
|
||||||
|
("opened", True, "open", False),
|
||||||
|
("opened", False, "closed", False),
|
||||||
|
],
|
||||||
|
)
|
||||||
|
async def test_add_docs_trigger(monkeypatch, action, draft, state, should_run):
|
||||||
|
# Mock settings to enable the "/add_docs" auto-command on PR opened
|
||||||
|
settings = get_settings()
|
||||||
|
settings.github_app.pr_commands = ["/add_docs"]
|
||||||
|
settings.github_app.handle_pr_actions = ["opened"]
|
||||||
|
|
||||||
|
# Define a FakeGitProvider for both apply_repo_settings and PRAddDocs
|
||||||
|
class FakeGitProvider:
|
||||||
|
def __init__(self, pr_url, *args, **kwargs):
|
||||||
|
self.pr = type("pr", (), {"title": "Test PR"})()
|
||||||
|
self.get_pr_branch = lambda: "test-branch"
|
||||||
|
self.get_pr_description = lambda: "desc"
|
||||||
|
self.get_languages = lambda: ["Python"]
|
||||||
|
self.get_files = lambda: []
|
||||||
|
self.get_commit_messages = lambda: "msg"
|
||||||
|
self.publish_comment = lambda *args, **kwargs: None
|
||||||
|
self.remove_initial_comment = lambda: None
|
||||||
|
self.publish_code_suggestions = lambda suggestions: True
|
||||||
|
self.diff_files = []
|
||||||
|
self.get_repo_settings = lambda: {}
|
||||||
|
|
||||||
|
# Patch Git provider lookups
|
||||||
|
monkeypatch.setattr(
|
||||||
|
"pr_agent.git_providers.utils.get_git_provider_with_context",
|
||||||
|
lambda pr_url: FakeGitProvider(pr_url),
|
||||||
|
)
|
||||||
|
monkeypatch.setattr(
|
||||||
|
"pr_agent.tools.pr_add_docs.get_git_provider",
|
||||||
|
lambda: FakeGitProvider,
|
||||||
|
)
|
||||||
|
|
||||||
|
# Ensure identity provider always eligible
|
||||||
|
monkeypatch.setattr(
|
||||||
|
get_identity_provider().__class__,
|
||||||
|
"verify_eligibility",
|
||||||
|
lambda *args, **kwargs: Eligibility.ELIGIBLE,
|
||||||
|
)
|
||||||
|
|
||||||
|
# Spy on PRAddDocs.run()
|
||||||
|
ran = {"flag": False}
|
||||||
|
|
||||||
|
async def fake_run(self):
|
||||||
|
ran["flag"] = True
|
||||||
|
|
||||||
|
monkeypatch.setattr(PRAddDocs, "run", fake_run)
|
||||||
|
|
||||||
|
# Build minimal PR payload
|
||||||
|
body = {
|
||||||
|
"action": action,
|
||||||
|
"pull_request": {
|
||||||
|
"url": "https://example.com/fake/pr",
|
||||||
|
"state": state,
|
||||||
|
"draft": draft,
|
||||||
|
},
|
||||||
|
}
|
||||||
|
log_context = {}
|
||||||
|
|
||||||
|
# Invoke the PR-open handler
|
||||||
|
agent = PRAgent()
|
||||||
|
await handle_new_pr_opened(
|
||||||
|
body=body,
|
||||||
|
event="pull_request",
|
||||||
|
sender="tester",
|
||||||
|
sender_id="123",
|
||||||
|
action=action,
|
||||||
|
log_context=log_context,
|
||||||
|
agent=agent,
|
||||||
|
)
|
||||||
|
|
||||||
|
assert ran["flag"] is should_run, (
|
||||||
|
f"Expected run() to be {'called' if should_run else 'skipped'}"
|
||||||
|
f" for action={action!r}, draft={draft}, state={state!r}"
|
||||||
|
)
|
||||||
59
tests/unittest/test_azure_devops_comment.py
Normal file
59
tests/unittest/test_azure_devops_comment.py
Normal file
|
|
@ -0,0 +1,59 @@
|
||||||
|
import unittest
|
||||||
|
from pr_agent.config_loader import get_settings
|
||||||
|
from unittest.mock import patch, MagicMock
|
||||||
|
from pr_agent.git_providers import AzureDevopsProvider
|
||||||
|
|
||||||
|
class TestAzureDevopsProviderPublishComment(unittest.TestCase):
|
||||||
|
@patch("pr_agent.git_providers.azuredevops_provider.get_settings")
|
||||||
|
def test_publish_comment_default_closed(self, mock_get_settings):
|
||||||
|
# Simulate config with no default_comment_status
|
||||||
|
mock_settings = MagicMock()
|
||||||
|
mock_settings.azure_devops.get.return_value = "closed"
|
||||||
|
mock_settings.config.publish_output_progress = True
|
||||||
|
mock_get_settings.return_value = mock_settings
|
||||||
|
|
||||||
|
with patch.object(AzureDevopsProvider, "_get_azure_devops_client", return_value=(MagicMock(), MagicMock())):
|
||||||
|
provider = AzureDevopsProvider()
|
||||||
|
provider.workspace_slug = "ws"
|
||||||
|
provider.repo_slug = "repo"
|
||||||
|
provider.pr_num = 1
|
||||||
|
|
||||||
|
# Patch CommentThread and create_thread
|
||||||
|
with patch("pr_agent.git_providers.azuredevops_provider.CommentThread") as MockThread:
|
||||||
|
provider.azure_devops_client.create_thread.return_value.comments = [MagicMock()]
|
||||||
|
provider.azure_devops_client.create_thread.return_value.comments[0].thread_id = 123
|
||||||
|
provider.azure_devops_client.create_thread.return_value.id = 123
|
||||||
|
|
||||||
|
provider.publish_comment("test comment")
|
||||||
|
args, kwargs = MockThread.call_args
|
||||||
|
assert kwargs.get("status") == "closed"
|
||||||
|
|
||||||
|
@patch("pr_agent.git_providers.azuredevops_provider.get_settings")
|
||||||
|
def test_publish_comment_active(self, mock_get_settings):
|
||||||
|
# Simulate config with default_comment_status = "active"
|
||||||
|
mock_settings = MagicMock()
|
||||||
|
mock_settings.azure_devops.get.return_value = "active"
|
||||||
|
mock_settings.config.publish_output_progress = True
|
||||||
|
mock_get_settings.return_value = mock_settings
|
||||||
|
|
||||||
|
with patch.object(AzureDevopsProvider, "_get_azure_devops_client", return_value=(MagicMock(), MagicMock())):
|
||||||
|
provider = AzureDevopsProvider()
|
||||||
|
provider.workspace_slug = "ws"
|
||||||
|
provider.repo_slug = "repo"
|
||||||
|
provider.pr_num = 1
|
||||||
|
|
||||||
|
# Patch CommentThread and create_thread
|
||||||
|
with patch("pr_agent.git_providers.azuredevops_provider.CommentThread") as MockThread:
|
||||||
|
provider.azure_devops_client.create_thread.return_value.comments = [MagicMock()]
|
||||||
|
provider.azure_devops_client.create_thread.return_value.comments[0].thread_id = 123
|
||||||
|
provider.azure_devops_client.create_thread.return_value.id = 123
|
||||||
|
|
||||||
|
provider.publish_comment("test comment")
|
||||||
|
args, kwargs = MockThread.call_args
|
||||||
|
assert kwargs.get("status") == "active"
|
||||||
|
|
||||||
|
def test_default_comment_status_from_config_file(self):
|
||||||
|
# Import get_settings directly to read from configuration.toml
|
||||||
|
status = get_settings().azure_devops.default_comment_status
|
||||||
|
# The expected value should match what's in your configuration.toml
|
||||||
|
self.assertEqual(status, "closed")
|
||||||
|
|
@ -51,7 +51,7 @@ class TestConvertToMarkdown:
|
||||||
input_data = {'review': {
|
input_data = {'review': {
|
||||||
'estimated_effort_to_review_[1-5]': '1, because the changes are minimal and straightforward, focusing on a single functionality addition.\n',
|
'estimated_effort_to_review_[1-5]': '1, because the changes are minimal and straightforward, focusing on a single functionality addition.\n',
|
||||||
'relevant_tests': 'No\n', 'possible_issues': 'No\n', 'security_concerns': 'No\n'}}
|
'relevant_tests': 'No\n', 'possible_issues': 'No\n', 'security_concerns': 'No\n'}}
|
||||||
|
|
||||||
expected_output = textwrap.dedent(f"""\
|
expected_output = textwrap.dedent(f"""\
|
||||||
{PRReviewHeader.REGULAR.value} 🔍
|
{PRReviewHeader.REGULAR.value} 🔍
|
||||||
|
|
||||||
|
|
@ -67,12 +67,12 @@ class TestConvertToMarkdown:
|
||||||
""")
|
""")
|
||||||
|
|
||||||
assert convert_to_markdown_v2(input_data).strip() == expected_output.strip()
|
assert convert_to_markdown_v2(input_data).strip() == expected_output.strip()
|
||||||
|
|
||||||
def test_simple_dictionary_input_without_gfm_supported(self):
|
def test_simple_dictionary_input_without_gfm_supported(self):
|
||||||
input_data = {'review': {
|
input_data = {'review': {
|
||||||
'estimated_effort_to_review_[1-5]': '1, because the changes are minimal and straightforward, focusing on a single functionality addition.\n',
|
'estimated_effort_to_review_[1-5]': '1, because the changes are minimal and straightforward, focusing on a single functionality addition.\n',
|
||||||
'relevant_tests': 'No\n', 'possible_issues': 'No\n', 'security_concerns': 'No\n'}}
|
'relevant_tests': 'No\n', 'possible_issues': 'No\n', 'security_concerns': 'No\n'}}
|
||||||
|
|
||||||
expected_output = textwrap.dedent("""\
|
expected_output = textwrap.dedent("""\
|
||||||
## PR Reviewer Guide 🔍
|
## PR Reviewer Guide 🔍
|
||||||
|
|
||||||
|
|
@ -89,74 +89,74 @@ class TestConvertToMarkdown:
|
||||||
""")
|
""")
|
||||||
|
|
||||||
assert convert_to_markdown_v2(input_data, gfm_supported=False).strip() == expected_output.strip()
|
assert convert_to_markdown_v2(input_data, gfm_supported=False).strip() == expected_output.strip()
|
||||||
|
|
||||||
def test_key_issues_to_review(self):
|
def test_key_issues_to_review(self):
|
||||||
input_data = {'review': {
|
input_data = {'review': {
|
||||||
'key_issues_to_review': [
|
'key_issues_to_review': [
|
||||||
{
|
{
|
||||||
'relevant_file' : 'src/utils.py',
|
'relevant_file': 'src/utils.py',
|
||||||
'issue_header' : 'Code Smell',
|
'issue_header': 'Code Smell',
|
||||||
'issue_content' : 'The function is too long and complex.',
|
'issue_content': 'The function is too long and complex.',
|
||||||
'start_line': 30,
|
'start_line': 30,
|
||||||
'end_line': 50,
|
'end_line': 50,
|
||||||
}
|
}
|
||||||
]
|
]
|
||||||
}}
|
}}
|
||||||
mock_git_provider = Mock()
|
mock_git_provider = Mock()
|
||||||
reference_link = 'https://github.com/qodo/pr-agent/pull/1/files#diff-hashvalue-R174'
|
reference_link = 'https://github.com/qodo/pr-agent/pull/1/files#diff-hashvalue-R174'
|
||||||
mock_git_provider.get_line_link.return_value = reference_link
|
mock_git_provider.get_line_link.return_value = reference_link
|
||||||
|
|
||||||
expected_output = textwrap.dedent(f"""\
|
expected_output = textwrap.dedent(f"""\
|
||||||
## PR Reviewer Guide 🔍
|
## PR Reviewer Guide 🔍
|
||||||
|
|
||||||
Here are some key observations to aid the review process:
|
Here are some key observations to aid the review process:
|
||||||
|
|
||||||
<table>
|
<table>
|
||||||
<tr><td>⚡ <strong>Recommended focus areas for review</strong><br><br>
|
<tr><td>⚡ <strong>Recommended focus areas for review</strong><br><br>
|
||||||
|
|
||||||
<a href='{reference_link}'><strong>Code Smell</strong></a><br>The function is too long and complex.
|
<a href='{reference_link}'><strong>Code Smell</strong></a><br>The function is too long and complex.
|
||||||
|
|
||||||
</td></tr>
|
</td></tr>
|
||||||
</table>
|
</table>
|
||||||
""")
|
""")
|
||||||
|
|
||||||
assert convert_to_markdown_v2(input_data, git_provider=mock_git_provider).strip() == expected_output.strip()
|
assert convert_to_markdown_v2(input_data, git_provider=mock_git_provider).strip() == expected_output.strip()
|
||||||
mock_git_provider.get_line_link.assert_called_with('src/utils.py', 30, 50)
|
mock_git_provider.get_line_link.assert_called_with('src/utils.py', 30, 50)
|
||||||
|
|
||||||
def test_ticket_compliance(self):
|
def test_ticket_compliance(self):
|
||||||
input_data = {'review': {
|
input_data = {'review': {
|
||||||
'ticket_compliance_check': [
|
'ticket_compliance_check': [
|
||||||
{
|
{
|
||||||
'ticket_url': 'https://example.com/ticket/123',
|
'ticket_url': 'https://example.com/ticket/123',
|
||||||
'ticket_requirements': '- Requirement 1\n- Requirement 2\n',
|
'ticket_requirements': '- Requirement 1\n- Requirement 2\n',
|
||||||
'fully_compliant_requirements': '- Requirement 1\n- Requirement 2\n',
|
'fully_compliant_requirements': '- Requirement 1\n- Requirement 2\n',
|
||||||
'not_compliant_requirements': '',
|
'not_compliant_requirements': '',
|
||||||
'requires_further_human_verification': '',
|
'requires_further_human_verification': '',
|
||||||
}
|
}
|
||||||
]
|
]
|
||||||
}}
|
}}
|
||||||
|
|
||||||
expected_output = textwrap.dedent("""\
|
expected_output = textwrap.dedent("""\
|
||||||
## PR Reviewer Guide 🔍
|
## PR Reviewer Guide 🔍
|
||||||
|
|
||||||
Here are some key observations to aid the review process:
|
Here are some key observations to aid the review process:
|
||||||
|
|
||||||
<table>
|
<table>
|
||||||
<tr><td>
|
<tr><td>
|
||||||
|
|
||||||
**🎫 Ticket compliance analysis ✅**
|
**🎫 Ticket compliance analysis ✅**
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
**[123](https://example.com/ticket/123) - Fully compliant**
|
**[123](https://example.com/ticket/123) - Fully compliant**
|
||||||
|
|
||||||
Compliant requirements:
|
Compliant requirements:
|
||||||
|
|
||||||
- Requirement 1
|
- Requirement 1
|
||||||
- Requirement 2
|
- Requirement 2
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
</td></tr>
|
</td></tr>
|
||||||
</table>
|
</table>
|
||||||
""")
|
""")
|
||||||
|
|
@ -179,56 +179,89 @@ class TestConvertToMarkdown:
|
||||||
],
|
],
|
||||||
'title': 'Bug Fix',
|
'title': 'Bug Fix',
|
||||||
}
|
}
|
||||||
]
|
]
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
expected_output = textwrap.dedent("""\
|
expected_output = textwrap.dedent("""\
|
||||||
## PR Reviewer Guide 🔍
|
## PR Reviewer Guide 🔍
|
||||||
|
|
||||||
Here are some key observations to aid the review process:
|
Here are some key observations to aid the review process:
|
||||||
|
|
||||||
<table>
|
<table>
|
||||||
<tr><td>🔀 <strong>Multiple PR themes</strong><br><br>
|
<tr><td>🔀 <strong>Multiple PR themes</strong><br><br>
|
||||||
|
|
||||||
<details><summary>
|
<details><summary>
|
||||||
Sub-PR theme: <b>Refactoring</b></summary>
|
Sub-PR theme: <b>Refactoring</b></summary>
|
||||||
|
|
||||||
___
|
___
|
||||||
|
|
||||||
Relevant files:
|
Relevant files:
|
||||||
|
|
||||||
- src/file1.py
|
- src/file1.py
|
||||||
- src/file2.py
|
- src/file2.py
|
||||||
___
|
___
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
<details><summary>
|
<details><summary>
|
||||||
Sub-PR theme: <b>Bug Fix</b></summary>
|
Sub-PR theme: <b>Bug Fix</b></summary>
|
||||||
|
|
||||||
___
|
___
|
||||||
|
|
||||||
Relevant files:
|
Relevant files:
|
||||||
|
|
||||||
- src/file3.py
|
- src/file3.py
|
||||||
___
|
___
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
</td></tr>
|
</td></tr>
|
||||||
</table>
|
</table>
|
||||||
""")
|
""")
|
||||||
|
|
||||||
assert convert_to_markdown_v2(input_data).strip() == expected_output.strip()
|
assert convert_to_markdown_v2(input_data).strip() == expected_output.strip()
|
||||||
|
|
||||||
|
def test_contribution_time_cost_estimate(self):
|
||||||
|
input_data = {
|
||||||
|
'review': {
|
||||||
|
'contribution_time_cost_estimate': {
|
||||||
|
'best_case': '1h',
|
||||||
|
'average_case': '2h',
|
||||||
|
'worst_case': '30m',
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
expected_output = textwrap.dedent(f"""
|
||||||
|
{PRReviewHeader.REGULAR.value} 🔍
|
||||||
|
|
||||||
|
Here are some key observations to aid the review process:
|
||||||
|
|
||||||
|
<table>
|
||||||
|
<tr><td>⏳ <strong>Contribution time estimate</strong> (best, average, worst case): 1h | 2h | 30 minutes</td></tr>
|
||||||
|
</table>
|
||||||
|
""")
|
||||||
|
assert convert_to_markdown_v2(input_data).strip() == expected_output.strip()
|
||||||
|
|
||||||
|
# Non-GFM branch
|
||||||
|
expected_output_no_gfm = textwrap.dedent(f"""
|
||||||
|
{PRReviewHeader.REGULAR.value} 🔍
|
||||||
|
|
||||||
|
Here are some key observations to aid the review process:
|
||||||
|
|
||||||
|
### ⏳ Contribution time estimate (best, average, worst case): 1h | 2h | 30 minutes
|
||||||
|
|
||||||
|
""")
|
||||||
|
assert convert_to_markdown_v2(input_data, gfm_supported=False).strip() == expected_output_no_gfm.strip()
|
||||||
|
|
||||||
|
|
||||||
# Tests that the function works correctly with an empty dictionary input
|
# Tests that the function works correctly with an empty dictionary input
|
||||||
def test_empty_dictionary_input(self):
|
def test_empty_dictionary_input(self):
|
||||||
input_data = {}
|
input_data = {}
|
||||||
|
|
||||||
expected_output = ''
|
expected_output = ''
|
||||||
|
|
||||||
|
|
||||||
assert convert_to_markdown_v2(input_data).strip() == expected_output.strip()
|
assert convert_to_markdown_v2(input_data).strip() == expected_output.strip()
|
||||||
|
|
||||||
def test_dictionary_with_empty_dictionaries(self):
|
def test_dictionary_with_empty_dictionaries(self):
|
||||||
|
|
@ -236,16 +269,16 @@ class TestConvertToMarkdown:
|
||||||
|
|
||||||
expected_output = ''
|
expected_output = ''
|
||||||
|
|
||||||
|
|
||||||
assert convert_to_markdown_v2(input_data).strip() == expected_output.strip()
|
assert convert_to_markdown_v2(input_data).strip() == expected_output.strip()
|
||||||
|
|
||||||
|
|
||||||
class TestBR:
|
class TestBR:
|
||||||
def test_br1(self):
|
def test_br1(self):
|
||||||
file_change_description = '- Imported `FilePatchInfo` and `EDIT_TYPE` from `pr_agent.algo.types` instead of `pr_agent.git_providers.git_provider`.'
|
file_change_description = '- Imported `FilePatchInfo` and `EDIT_TYPE` from `pr_agent.algo.types` instead of `pr_agent.git_providers.git_provider`.'
|
||||||
file_change_description_br = insert_br_after_x_chars(file_change_description)
|
file_change_description_br = insert_br_after_x_chars(file_change_description)
|
||||||
expected_output = ('<li>Imported <code>FilePatchInfo</code> and <code>EDIT_TYPE</code> from '
|
expected_output = ('<ul><li>Imported <code>FilePatchInfo</code> and <code>EDIT_TYPE</code> from '
|
||||||
'<code>pr_agent.algo.types</code> instead <br>of '
|
'<code>pr_agent.algo.types</code> instead <br>of '
|
||||||
'<code>pr_agent.git_providers.git_provider</code>.')
|
'<code>pr_agent.git_providers.git_provider</code>.</ul>')
|
||||||
assert file_change_description_br == expected_output
|
assert file_change_description_br == expected_output
|
||||||
# print("-----")
|
# print("-----")
|
||||||
# print(file_change_description_br)
|
# print(file_change_description_br)
|
||||||
|
|
@ -255,9 +288,9 @@ class TestBR:
|
||||||
'- Created a - new -class `ColorPaletteResourcesCollection ColorPaletteResourcesCollection '
|
'- Created a - new -class `ColorPaletteResourcesCollection ColorPaletteResourcesCollection '
|
||||||
'ColorPaletteResourcesCollection ColorPaletteResourcesCollection`')
|
'ColorPaletteResourcesCollection ColorPaletteResourcesCollection`')
|
||||||
file_change_description_br = insert_br_after_x_chars(file_change_description)
|
file_change_description_br = insert_br_after_x_chars(file_change_description)
|
||||||
expected_output = ('<li>Created a - new -class <code>ColorPaletteResourcesCollection </code><br><code>'
|
expected_output = ('<ul><li>Created a - new -class <code>ColorPaletteResourcesCollection </code><br><code>'
|
||||||
'ColorPaletteResourcesCollection ColorPaletteResourcesCollection '
|
'ColorPaletteResourcesCollection ColorPaletteResourcesCollection '
|
||||||
'</code><br><code>ColorPaletteResourcesCollection</code>')
|
'</code><br><code>ColorPaletteResourcesCollection</code></ul>')
|
||||||
assert file_change_description_br == expected_output
|
assert file_change_description_br == expected_output
|
||||||
# print("-----")
|
# print("-----")
|
||||||
# print(file_change_description_br)
|
# print(file_change_description_br)
|
||||||
|
|
|
||||||
|
|
@ -80,3 +80,53 @@ class TestIgnoreFilter:
|
||||||
|
|
||||||
filtered_files = filter_ignored(files)
|
filtered_files = filter_ignored(files)
|
||||||
assert filtered_files == expected, f"Expected {[file.filename for file in expected]}, but got {[file.filename for file in filtered_files]}."
|
assert filtered_files == expected, f"Expected {[file.filename for file in expected]}, but got {[file.filename for file in filtered_files]}."
|
||||||
|
|
||||||
|
def test_language_framework_ignores(self, monkeypatch):
|
||||||
|
"""
|
||||||
|
Test files are ignored based on language/framework mapping (e.g., protobuf).
|
||||||
|
"""
|
||||||
|
monkeypatch.setattr(global_settings.config, 'ignore_language_framework', ['protobuf', 'go_gen'])
|
||||||
|
|
||||||
|
files = [
|
||||||
|
type('', (object,), {'filename': 'main.go'})(),
|
||||||
|
type('', (object,), {'filename': 'dir1/service.pb.go'})(),
|
||||||
|
type('', (object,), {'filename': 'dir1/dir/data_pb2.py'})(),
|
||||||
|
type('', (object,), {'filename': 'file.py'})(),
|
||||||
|
type('', (object,), {'filename': 'dir2/file_gen.go'})(),
|
||||||
|
type('', (object,), {'filename': 'file.generated.go'})()
|
||||||
|
]
|
||||||
|
expected = [
|
||||||
|
files[0],
|
||||||
|
files[3]
|
||||||
|
]
|
||||||
|
|
||||||
|
filtered = filter_ignored(files)
|
||||||
|
assert filtered == expected, (
|
||||||
|
f"Expected {[f.filename for f in expected]}, "
|
||||||
|
f"but got {[f.filename for f in filtered]}"
|
||||||
|
)
|
||||||
|
|
||||||
|
def test_skip_invalid_ignore_language_framework(self, monkeypatch):
|
||||||
|
"""
|
||||||
|
Test skipping of generated code filtering when ignore_language_framework is not a list
|
||||||
|
"""
|
||||||
|
monkeypatch.setattr(global_settings.config, 'ignore_language_framework', 'protobuf')
|
||||||
|
|
||||||
|
files = [
|
||||||
|
type('', (object,), {'filename': 'main.go'})(),
|
||||||
|
type('', (object,), {'filename': 'file.py'})(),
|
||||||
|
type('', (object,), {'filename': 'dir1/service.pb.go'})(),
|
||||||
|
type('', (object,), {'filename': 'file_pb2.py'})()
|
||||||
|
]
|
||||||
|
expected = [
|
||||||
|
files[0],
|
||||||
|
files[1],
|
||||||
|
files[2],
|
||||||
|
files[3]
|
||||||
|
]
|
||||||
|
|
||||||
|
filtered = filter_ignored(files)
|
||||||
|
assert filtered == expected, (
|
||||||
|
f"Expected {[f.filename for f in expected]}, "
|
||||||
|
f"but got {[f.filename for f in filtered]}"
|
||||||
|
)
|
||||||
|
|
|
||||||
|
|
@ -1,35 +1,36 @@
|
||||||
import pytest
|
|
||||||
from unittest.mock import MagicMock, patch
|
from unittest.mock import MagicMock, patch
|
||||||
|
|
||||||
from pr_agent.git_providers.gitlab_provider import GitLabProvider
|
import pytest
|
||||||
from gitlab import Gitlab
|
from gitlab import Gitlab
|
||||||
from gitlab.v4.objects import Project, ProjectFile
|
|
||||||
from gitlab.exceptions import GitlabGetError
|
from gitlab.exceptions import GitlabGetError
|
||||||
|
from gitlab.v4.objects import Project, ProjectFile
|
||||||
|
|
||||||
|
from pr_agent.git_providers.gitlab_provider import GitLabProvider
|
||||||
|
|
||||||
|
|
||||||
class TestGitLabProvider:
|
class TestGitLabProvider:
|
||||||
"""Test suite for GitLab provider functionality."""
|
"""Test suite for GitLab provider functionality."""
|
||||||
|
|
||||||
@pytest.fixture
|
@pytest.fixture
|
||||||
def mock_gitlab_client(self):
|
def mock_gitlab_client(self):
|
||||||
client = MagicMock()
|
client = MagicMock()
|
||||||
return client
|
return client
|
||||||
|
|
||||||
@pytest.fixture
|
@pytest.fixture
|
||||||
def mock_project(self):
|
def mock_project(self):
|
||||||
project = MagicMock()
|
project = MagicMock()
|
||||||
return project
|
return project
|
||||||
|
|
||||||
@pytest.fixture
|
@pytest.fixture
|
||||||
def gitlab_provider(self, mock_gitlab_client, mock_project):
|
def gitlab_provider(self, mock_gitlab_client, mock_project):
|
||||||
with patch('pr_agent.git_providers.gitlab_provider.gitlab.Gitlab', return_value=mock_gitlab_client), \
|
with patch('pr_agent.git_providers.gitlab_provider.gitlab.Gitlab', return_value=mock_gitlab_client), \
|
||||||
patch('pr_agent.git_providers.gitlab_provider.get_settings') as mock_settings:
|
patch('pr_agent.git_providers.gitlab_provider.get_settings') as mock_settings:
|
||||||
|
|
||||||
mock_settings.return_value.get.side_effect = lambda key, default=None: {
|
mock_settings.return_value.get.side_effect = lambda key, default=None: {
|
||||||
"GITLAB.URL": "https://gitlab.com",
|
"GITLAB.URL": "https://gitlab.com",
|
||||||
"GITLAB.PERSONAL_ACCESS_TOKEN": "fake_token"
|
"GITLAB.PERSONAL_ACCESS_TOKEN": "fake_token"
|
||||||
}.get(key, default)
|
}.get(key, default)
|
||||||
|
|
||||||
mock_gitlab_client.projects.get.return_value = mock_project
|
mock_gitlab_client.projects.get.return_value = mock_project
|
||||||
provider = GitLabProvider("https://gitlab.com/test/repo/-/merge_requests/1")
|
provider = GitLabProvider("https://gitlab.com/test/repo/-/merge_requests/1")
|
||||||
provider.gl = mock_gitlab_client
|
provider.gl = mock_gitlab_client
|
||||||
|
|
@ -40,9 +41,9 @@ class TestGitLabProvider:
|
||||||
mock_file = MagicMock(ProjectFile)
|
mock_file = MagicMock(ProjectFile)
|
||||||
mock_file.decode.return_value = "# Changelog\n\n## v1.0.0\n- Initial release"
|
mock_file.decode.return_value = "# Changelog\n\n## v1.0.0\n- Initial release"
|
||||||
mock_project.files.get.return_value = mock_file
|
mock_project.files.get.return_value = mock_file
|
||||||
|
|
||||||
content = gitlab_provider.get_pr_file_content("CHANGELOG.md", "main")
|
content = gitlab_provider.get_pr_file_content("CHANGELOG.md", "main")
|
||||||
|
|
||||||
assert content == "# Changelog\n\n## v1.0.0\n- Initial release"
|
assert content == "# Changelog\n\n## v1.0.0\n- Initial release"
|
||||||
mock_project.files.get.assert_called_once_with("CHANGELOG.md", "main")
|
mock_project.files.get.assert_called_once_with("CHANGELOG.md", "main")
|
||||||
mock_file.decode.assert_called_once()
|
mock_file.decode.assert_called_once()
|
||||||
|
|
@ -51,39 +52,39 @@ class TestGitLabProvider:
|
||||||
mock_file = MagicMock(ProjectFile)
|
mock_file = MagicMock(ProjectFile)
|
||||||
mock_file.decode.return_value = b"# Changelog\n\n## v1.0.0\n- Initial release"
|
mock_file.decode.return_value = b"# Changelog\n\n## v1.0.0\n- Initial release"
|
||||||
mock_project.files.get.return_value = mock_file
|
mock_project.files.get.return_value = mock_file
|
||||||
|
|
||||||
content = gitlab_provider.get_pr_file_content("CHANGELOG.md", "main")
|
content = gitlab_provider.get_pr_file_content("CHANGELOG.md", "main")
|
||||||
|
|
||||||
assert content == "# Changelog\n\n## v1.0.0\n- Initial release"
|
assert content == "# Changelog\n\n## v1.0.0\n- Initial release"
|
||||||
mock_project.files.get.assert_called_once_with("CHANGELOG.md", "main")
|
mock_project.files.get.assert_called_once_with("CHANGELOG.md", "main")
|
||||||
|
|
||||||
def test_get_pr_file_content_file_not_found(self, gitlab_provider, mock_project):
|
def test_get_pr_file_content_file_not_found(self, gitlab_provider, mock_project):
|
||||||
mock_project.files.get.side_effect = GitlabGetError("404 Not Found")
|
mock_project.files.get.side_effect = GitlabGetError("404 Not Found")
|
||||||
|
|
||||||
content = gitlab_provider.get_pr_file_content("CHANGELOG.md", "main")
|
content = gitlab_provider.get_pr_file_content("CHANGELOG.md", "main")
|
||||||
|
|
||||||
assert content == ""
|
assert content == ""
|
||||||
mock_project.files.get.assert_called_once_with("CHANGELOG.md", "main")
|
mock_project.files.get.assert_called_once_with("CHANGELOG.md", "main")
|
||||||
|
|
||||||
def test_get_pr_file_content_other_exception(self, gitlab_provider, mock_project):
|
def test_get_pr_file_content_other_exception(self, gitlab_provider, mock_project):
|
||||||
mock_project.files.get.side_effect = Exception("Network error")
|
mock_project.files.get.side_effect = Exception("Network error")
|
||||||
|
|
||||||
content = gitlab_provider.get_pr_file_content("CHANGELOG.md", "main")
|
content = gitlab_provider.get_pr_file_content("CHANGELOG.md", "main")
|
||||||
|
|
||||||
assert content == ""
|
assert content == ""
|
||||||
|
|
||||||
def test_create_or_update_pr_file_create_new(self, gitlab_provider, mock_project):
|
def test_create_or_update_pr_file_create_new(self, gitlab_provider, mock_project):
|
||||||
mock_project.files.get.side_effect = GitlabGetError("404 Not Found")
|
mock_project.files.get.side_effect = GitlabGetError("404 Not Found")
|
||||||
mock_file = MagicMock()
|
mock_file = MagicMock()
|
||||||
mock_project.files.create.return_value = mock_file
|
mock_project.files.create.return_value = mock_file
|
||||||
|
|
||||||
new_content = "# Changelog\n\n## v1.1.0\n- New feature"
|
new_content = "# Changelog\n\n## v1.1.0\n- New feature"
|
||||||
commit_message = "Add CHANGELOG.md"
|
commit_message = "Add CHANGELOG.md"
|
||||||
|
|
||||||
gitlab_provider.create_or_update_pr_file(
|
gitlab_provider.create_or_update_pr_file(
|
||||||
"CHANGELOG.md", "feature-branch", new_content, commit_message
|
"CHANGELOG.md", "feature-branch", new_content, commit_message
|
||||||
)
|
)
|
||||||
|
|
||||||
mock_project.files.get.assert_called_once_with("CHANGELOG.md", "feature-branch")
|
mock_project.files.get.assert_called_once_with("CHANGELOG.md", "feature-branch")
|
||||||
mock_project.files.create.assert_called_once_with({
|
mock_project.files.create.assert_called_once_with({
|
||||||
'file_path': 'CHANGELOG.md',
|
'file_path': 'CHANGELOG.md',
|
||||||
|
|
@ -96,21 +97,21 @@ class TestGitLabProvider:
|
||||||
mock_file = MagicMock(ProjectFile)
|
mock_file = MagicMock(ProjectFile)
|
||||||
mock_file.decode.return_value = "# Old changelog content"
|
mock_file.decode.return_value = "# Old changelog content"
|
||||||
mock_project.files.get.return_value = mock_file
|
mock_project.files.get.return_value = mock_file
|
||||||
|
|
||||||
new_content = "# New changelog content"
|
new_content = "# New changelog content"
|
||||||
commit_message = "Update CHANGELOG.md"
|
commit_message = "Update CHANGELOG.md"
|
||||||
|
|
||||||
gitlab_provider.create_or_update_pr_file(
|
gitlab_provider.create_or_update_pr_file(
|
||||||
"CHANGELOG.md", "feature-branch", new_content, commit_message
|
"CHANGELOG.md", "feature-branch", new_content, commit_message
|
||||||
)
|
)
|
||||||
|
|
||||||
mock_project.files.get.assert_called_once_with("CHANGELOG.md", "feature-branch")
|
mock_project.files.get.assert_called_once_with("CHANGELOG.md", "feature-branch")
|
||||||
mock_file.content = new_content
|
mock_file.content = new_content
|
||||||
mock_file.save.assert_called_once_with(branch="feature-branch", commit_message=commit_message)
|
mock_file.save.assert_called_once_with(branch="feature-branch", commit_message=commit_message)
|
||||||
|
|
||||||
def test_create_or_update_pr_file_update_exception(self, gitlab_provider, mock_project):
|
def test_create_or_update_pr_file_update_exception(self, gitlab_provider, mock_project):
|
||||||
mock_project.files.get.side_effect = Exception("Network error")
|
mock_project.files.get.side_effect = Exception("Network error")
|
||||||
|
|
||||||
with pytest.raises(Exception):
|
with pytest.raises(Exception):
|
||||||
gitlab_provider.create_or_update_pr_file(
|
gitlab_provider.create_or_update_pr_file(
|
||||||
"CHANGELOG.md", "feature-branch", "content", "message"
|
"CHANGELOG.md", "feature-branch", "content", "message"
|
||||||
|
|
@ -122,10 +123,10 @@ class TestGitLabProvider:
|
||||||
|
|
||||||
def test_method_signature_compatibility(self, gitlab_provider):
|
def test_method_signature_compatibility(self, gitlab_provider):
|
||||||
import inspect
|
import inspect
|
||||||
|
|
||||||
sig = inspect.signature(gitlab_provider.create_or_update_pr_file)
|
sig = inspect.signature(gitlab_provider.create_or_update_pr_file)
|
||||||
params = list(sig.parameters.keys())
|
params = list(sig.parameters.keys())
|
||||||
|
|
||||||
expected_params = ['file_path', 'branch', 'contents', 'message']
|
expected_params = ['file_path', 'branch', 'contents', 'message']
|
||||||
assert params == expected_params
|
assert params == expected_params
|
||||||
|
|
||||||
|
|
@ -141,7 +142,53 @@ class TestGitLabProvider:
|
||||||
mock_file = MagicMock(ProjectFile)
|
mock_file = MagicMock(ProjectFile)
|
||||||
mock_file.decode.return_value = content
|
mock_file.decode.return_value = content
|
||||||
mock_project.files.get.return_value = mock_file
|
mock_project.files.get.return_value = mock_file
|
||||||
|
|
||||||
result = gitlab_provider.get_pr_file_content("test.md", "main")
|
result = gitlab_provider.get_pr_file_content("test.md", "main")
|
||||||
|
|
||||||
assert result == expected
|
assert result == expected
|
||||||
|
|
||||||
|
def test_get_gitmodules_map_parsing(self, gitlab_provider, mock_project):
|
||||||
|
gitlab_provider.id_project = "1"
|
||||||
|
gitlab_provider.mr = MagicMock()
|
||||||
|
gitlab_provider.mr.target_branch = "main"
|
||||||
|
|
||||||
|
file_obj = MagicMock(ProjectFile)
|
||||||
|
file_obj.decode.return_value = (
|
||||||
|
"[submodule \"libs/a\"]\n"
|
||||||
|
" path = \"libs/a\"\n"
|
||||||
|
" url = \"https://gitlab.com/a.git\"\n"
|
||||||
|
"[submodule \"libs/b\"]\n"
|
||||||
|
" path = libs/b\n"
|
||||||
|
" url = git@gitlab.com:b.git\n"
|
||||||
|
)
|
||||||
|
mock_project.files.get.return_value = file_obj
|
||||||
|
gitlab_provider.gl.projects.get.return_value = mock_project
|
||||||
|
|
||||||
|
result = gitlab_provider._get_gitmodules_map()
|
||||||
|
assert result == {
|
||||||
|
"libs/a": "https://gitlab.com/a.git",
|
||||||
|
"libs/b": "git@gitlab.com:b.git",
|
||||||
|
}
|
||||||
|
|
||||||
|
def test_project_by_path_requires_exact_match(self, gitlab_provider):
|
||||||
|
gitlab_provider.gl.projects.get.reset_mock()
|
||||||
|
gitlab_provider.gl.projects.get.side_effect = Exception("not found")
|
||||||
|
fake = MagicMock()
|
||||||
|
fake.path_with_namespace = "other/group/repo"
|
||||||
|
gitlab_provider.gl.projects.list.return_value = [fake]
|
||||||
|
|
||||||
|
result = gitlab_provider._project_by_path("group/repo")
|
||||||
|
|
||||||
|
assert result is None
|
||||||
|
assert gitlab_provider.gl.projects.get.call_count == 2
|
||||||
|
|
||||||
|
def test_compare_submodule_cached(self, gitlab_provider):
|
||||||
|
proj = MagicMock()
|
||||||
|
proj.repository_compare.return_value = {"diffs": [{"diff": "d"}]}
|
||||||
|
with patch.object(gitlab_provider, "_project_by_path", return_value=proj) as m_pbp:
|
||||||
|
first = gitlab_provider._compare_submodule("grp/repo", "old", "new")
|
||||||
|
second = gitlab_provider._compare_submodule("grp/repo", "old", "new")
|
||||||
|
|
||||||
|
assert first == second == [{"diff": "d"}]
|
||||||
|
m_pbp.assert_called_once_with("grp/repo")
|
||||||
|
proj.repository_compare.assert_called_once_with("old", "new")
|
||||||
|
|
|
||||||
|
|
@ -242,12 +242,5 @@ int sub(int a, int b) {
|
||||||
return a - b;
|
return a - b;
|
||||||
}
|
}
|
||||||
'''
|
'''
|
||||||
expected_output = {
|
expected_output = {'code_suggestions': [{'relevant_file': 'a.c\n', 'existing_code': ' int sum(int a, int b) {\n return a + b;\n }\n\n int sub(int a, int b) {\n return a - b;\n }\n'}]}
|
||||||
"code_suggestions": [
|
|
||||||
{
|
|
||||||
"relevant_file": "a.c\n",
|
|
||||||
"existing_code": expected_code_block
|
|
||||||
}
|
|
||||||
]
|
|
||||||
}
|
|
||||||
assert try_fix_yaml(review_text, first_key='code_suggestions', last_key='existing_code') == expected_output
|
assert try_fix_yaml(review_text, first_key='code_suggestions', last_key='existing_code') == expected_output
|
||||||
|
|
|
||||||
Loading…
Reference in a new issue